본 정리내용은 코드잇 강의를 공부하며 함께 정리한 내용입니다! 더 정확하고 자세한 내용을 공부하기 위해서는 "코드잇 머신러닝 실전 강의를 참고해주세요!"
신경망 경사하강법
경사하강법이란? 경사하강법은 특정 값에서 미분값을 이용하여 함수의 출력을 더 작게 하는 가장 빠른 방향으로 방향으로 이동하는 방법. 주로 손실함수를 최소로 만들기 위해 사용한다.
- 신경망에서는 경사하강법을 이용하기 위해 편미분을 사용하여 각 뉴런의
편미분값을 이용하여 모든 층을 업데이트 한다. 이 때 학습률 를 곱해 속도를 조절하게 된다.- Weight 경사하강법
- bias 경사하강법
- Weight 경사하강법
- 경사하강법이 복잡한 이유 : 신경망의 하나의 뉴런이 경사하강법을 이용한다면 뒤로 연결된 모든 뉴런이 단하나의 뉴런에 영향을 받아 값이 변화하게 된다. 즉 합성함수로 연결되어 있어 모든 뉴런이 서로 영향을 주고 받게 되기 때문에 입력과 출력으로 이루어진 다른 머신러닝 기법보다 경사하강법이 어렵다.

- 경사하강법의 손실함수의 볼록도 : 앞서 말했듯 여러가지 뉴런이 얽혀있기 때문에 손실함수가 convex하지 않다. 따라서 경사하강법을 진행해도 최소값을 찾는 것이 아닌 극소값을 찾을 확률이 크다. 하지만 경사하강법을 이용하는데, 그 이유는
- 첫째로 가중치와 편향에 어떤 값이 들어가야 될지 전혀 모르는 상황에서 어떤 임의 값에서 시작해도 그 값들보다는 손실을 줄일 수 있기 때문이다.
- 둘째로는 극소점들을 통해서 만들어진 신경망 성능이 충분히 좋기 때문이다.
따라서 손실 함수가 볼록하지 않다는 문제점을 극복하기 위해서는 여러번 초기화하여 경사 하강법을 많이 진행한 뒤, 가장 성능이 좋게 나온 모델을 사용한다.
합성함수와 연쇄법칙(Chaining Rule)
- 합성함수란? 함수의 출력이 다른 함수의 입력이되는 함수
Ex)
- 신경망의 손실함수 : 신경망은 앞의 층의 출력값이 뒤에 층의 입력값으로 활용된다. 따라서, 신경망의 손실함수는 여러개의 층의 손실함수가 합성된 형태이다.
- 신경망의 출력함수
- 신경망의 손실함수
두 함수를 통해 층이 서로 연결되어 있다는 것을 알 수 있다.
- 신경망의 출력함수
- 연쇄법칙(Chain Rule)이란?
합성함수의 미분은 합성함수를 구성하는 각 함수의 미분으로 곱으로 나타낼 수 있다를 이용하여 각 함수를 편미분을 하고 그함수의 곱을 통해 값을 구하게 된다.
Ex)를 미분- 풀이 :
- 풀이 :
역전파 (Back Propagation)
- 역전파(Back-propagation)란?
Forward Propagation(예측)과 반대의 진행방향으로 진행하며 예측값의 정확도를 높이기 위해 출력값과 실제 예측하고자 하는 값을 비교하여 가중치를 변경하는 작업을 말한다. 핵심은연쇄 법칙을 적용하는 것과뉴런의 출력에 대한 편미분을 앞 층에게 전달하는 것이다.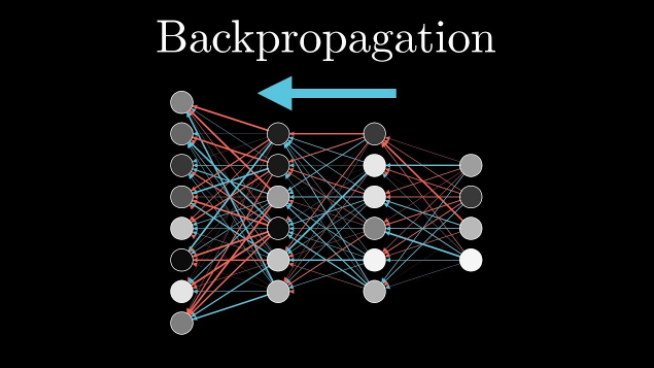
- 역전파의 장점:
연쇄 법칙을 사용해서 각 변화를 더 작은 변화로 표현하고 뒤 층들에서 계산한 편미분 값들을 앞 층 요소들의 편미분을 계산할 때 전달해 줌으로써 가중치와 편향에 대한 손실 함수의 편미분 계산을 최대한 쉽고 빠르게 진행할 수 있다.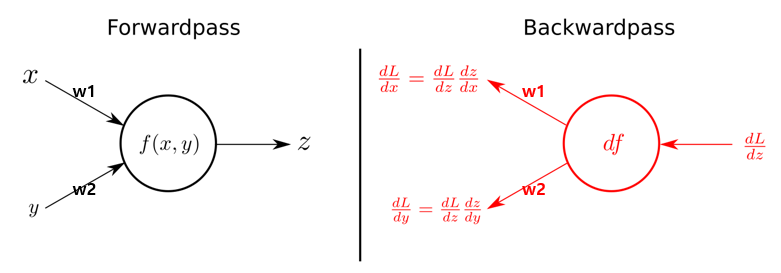
- 역전파의 방법 : 뒤에 있는 미분값은 오로지 앞에 있는 미분값에만 영향을 줍니다. 이를 이용하여 합성함수 미분을 통해 각 뉴런의 입력값과 출력값에 대한 편미분 값을 뒤에 층에서 앞에 층으로 순서대로 구합니다. 그 이후 최종적으로 뒤에 있는 미분값을 통해 순서대로 구해주고, 이미 계산된 뒤의 미분값을 이용함으로써 연산 속도를 빠르게 도와줍니다.

- 그리고 이렇게 구한 최종 미분값을 이용하여 경사하강법을 정해진 반복수에 맞게 진행해주면 되며, 코드로 구현할 때에는 행렬로 이용하여 병렬로 처리하게 함으로써 보다 빠르게 계산할 수 있도록 구현해야한다.
- 역전파 행렬 계산식 :
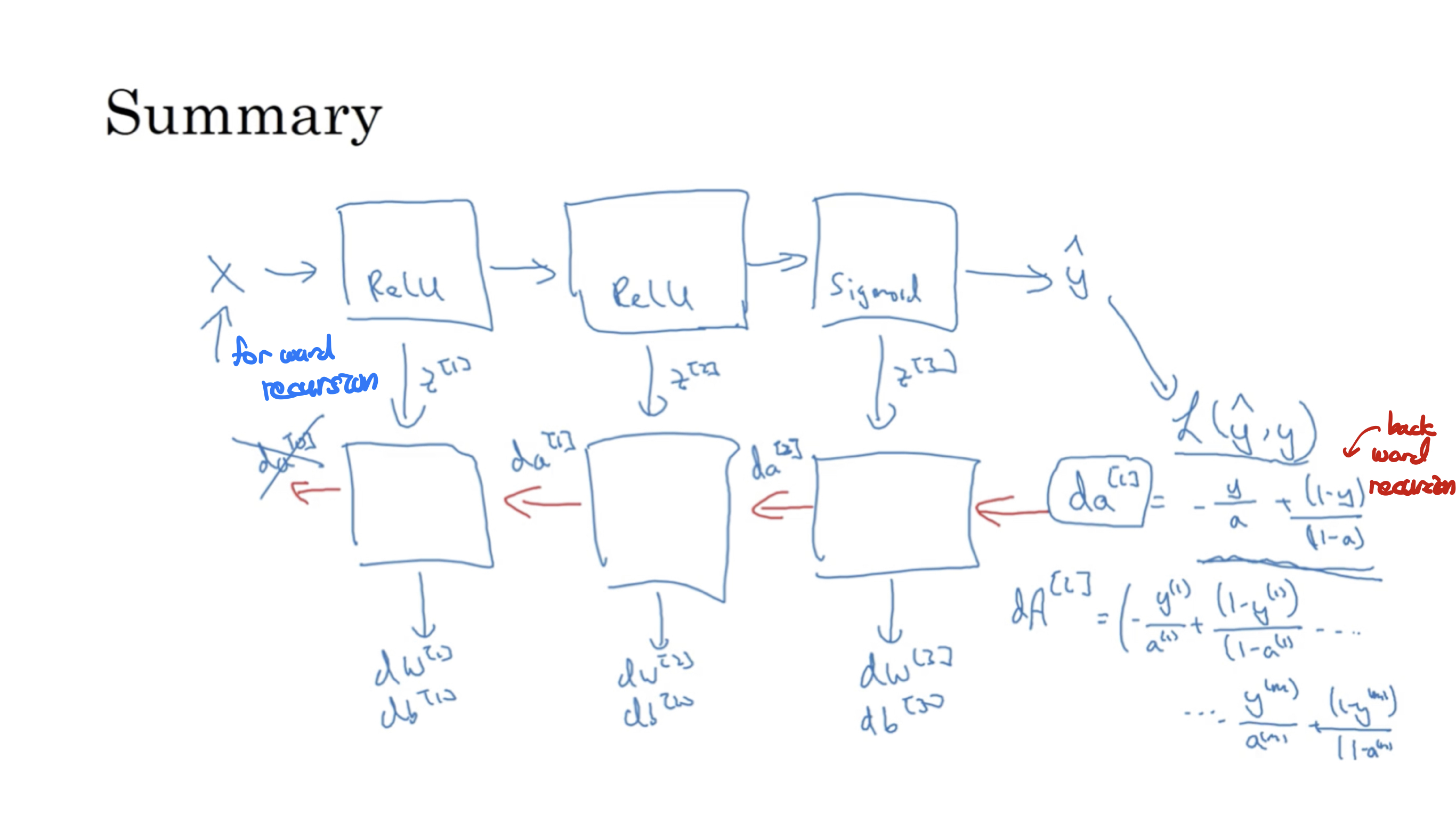
신경망의 학습
- 위와 같은 순전파와 역전파 과정을 많은 데이터에 여러번 반복하여 좋은 예측값을 출력할 수 있는 신경망이 될 수 있도록 학습을 시킴
참고 : 코드잇딥러닝

사회적 가치를 실현하는 프로그래머