지난 내용 복습하기 :
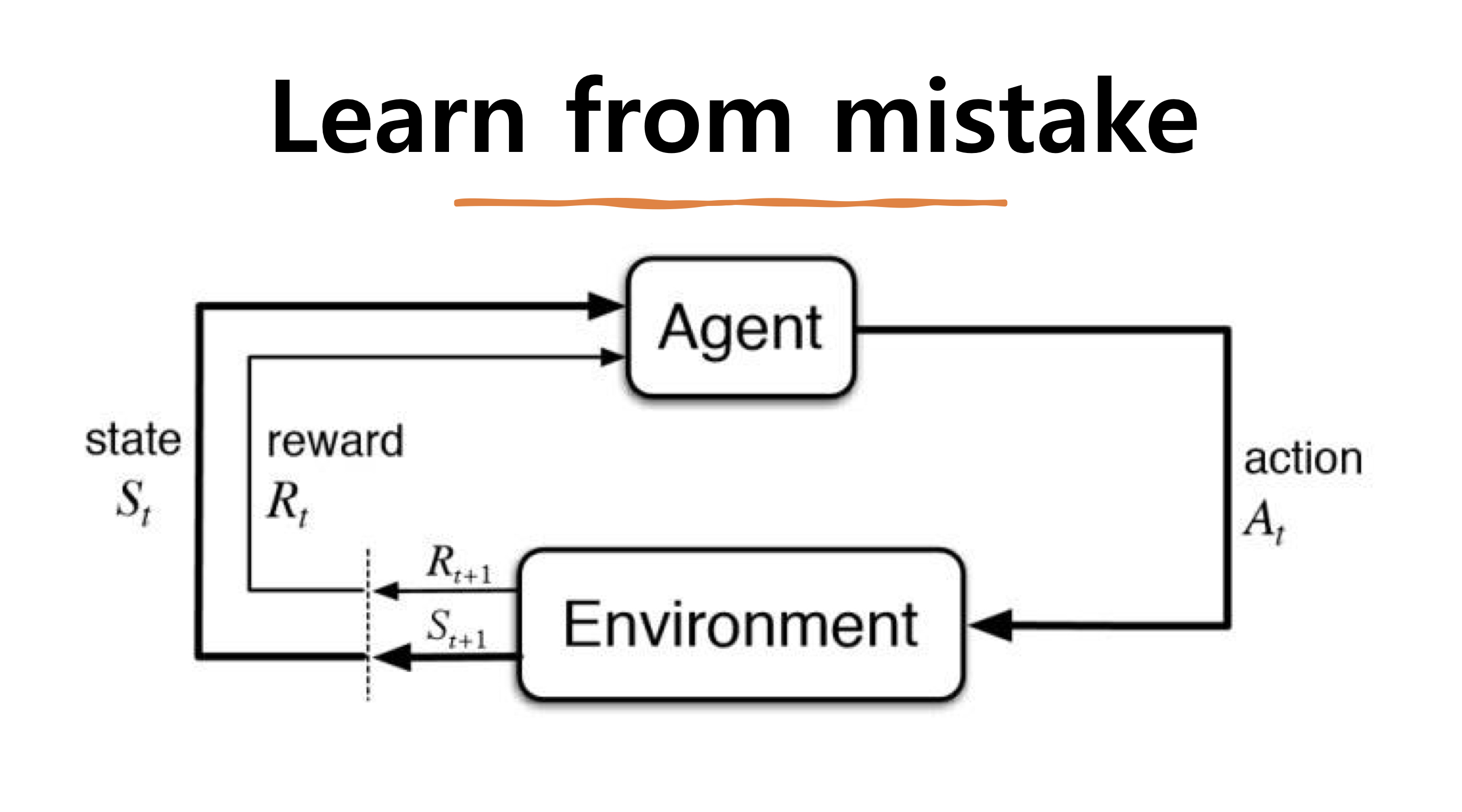
강화학습 정의 : 주어진 환경(environment)에서 에이전트(Agent)가 최대 보상(Reward)를 받을 수 있는 활동(Action)을 할 수 있도록 Policy를 학습하는 것!
- 환경(Environemt) : 에이전트가 액션을 취하는 환경을 말합니다. 슈퍼마리오 게임을 예를 든다면 버섯, 현재 마리오의 위치, 아이템, 구조물, 점수 등등 모든 것들이 환경이 됩니다.
- 상태(State) : 상태(State)는 Agent의 상태를 말하며 시간 t에서의 상황을 나타내며 상황이 어떠한지 나타내는 집합입니다. 가능한 모든 상태를 state space라고 부릅니다.
- 에이전트(Agent) : 에이전트는 학습 대상을 말합니다. 환경안에서 학습을 하는 주체로 보상을 최대로 받는 방식으로 학습을 합니다
- 보상(Reward) : 에이전트가 한 번 학습했을 때 주어지는 값입니다. 사용자가 설정한 결과를 만들어냈을때(최고점 획득,최소경로 학습, 최적경로 학습 등) 높은 값의 보상값을 얻을 수 있습니다.
- 행동(Act) : Agent가 취하는 행동으로 환경에 따라 다른 action 집합을 가지고 있습니다. 주로 앞으로가기, 뒤로가기와 같은 것들을 벡터형태 혹은 매트릭스 형태로 표현합니다. 그리고 이 가능한 모든 행동 집합을 Action Space라고 부르고 행동의 유한성에 따라 유한할 경우 Discrete Action set을 갖고, 무한한 경우 continuous Action Set을 갖고 있습니다.
- Ex) Discrete Action Set 예시 : 마리오게임에서 점프, 앞으로 가기
- Ex) Continuous Action Set 예시 : 자율주행 자동차에서 회전각도
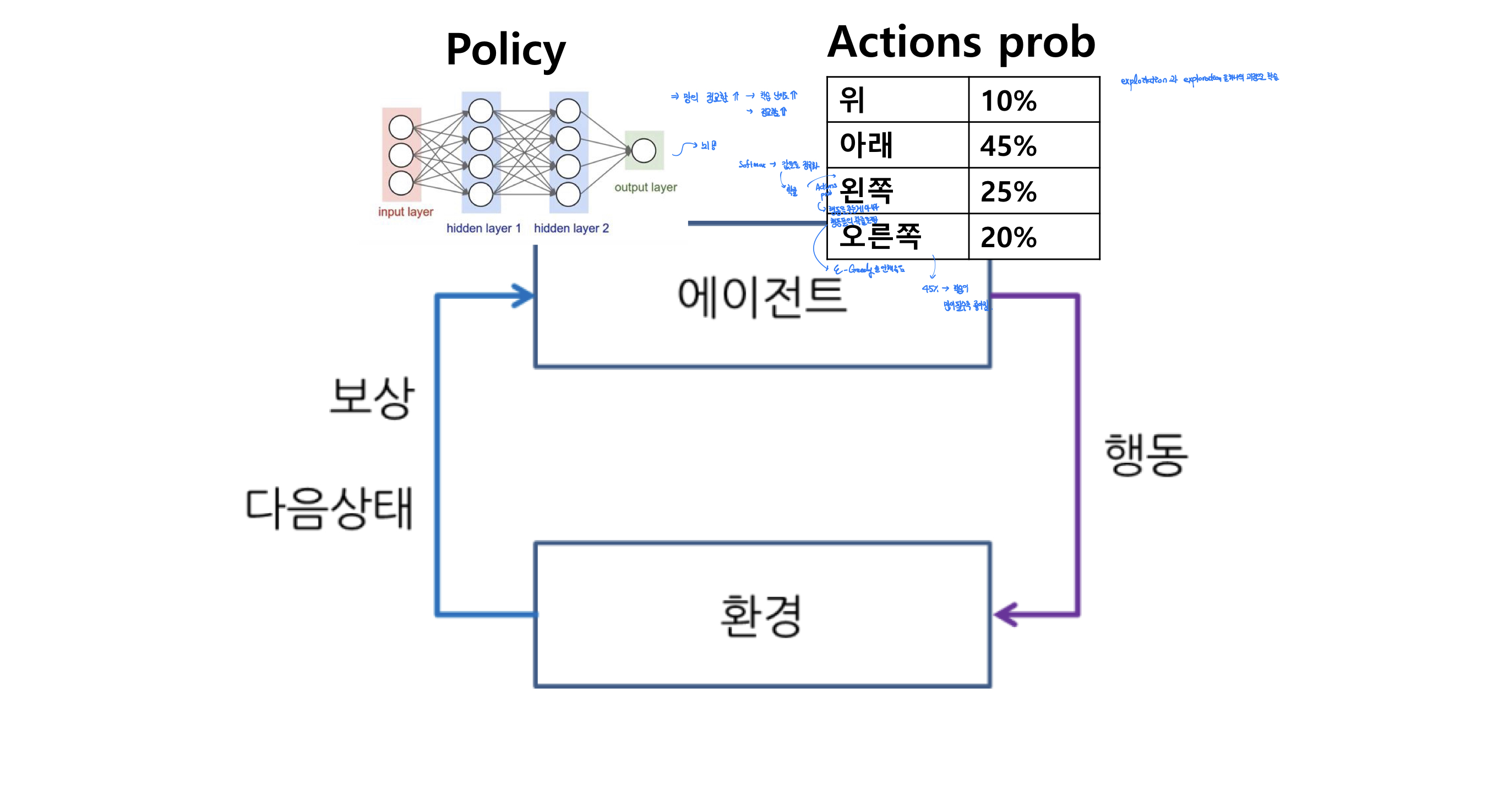
- 정책(Policy) : 궁극적으로 학습을 통해 구하려는 것으로 특정 상황에서의 action 혹은 action의 확률을 정의합니다.
- Exploitation : 학습을 한 결과를 바탕으로 탐색을 하는 방법
- Exploration : 새로운 학습을 위해 학습이 제시한 가이드라인 밖을 벗어난 방법으로 탐색을 하는 방법
- Episode : initial state부터 terminal state까지의 cycle을 말하며 보통 epoch과 같은 강화학습의 학습 단위로 쓰입니다. 여러 step으로 이루어져있습니다.
- Step: t번째 state에서 t+1 state까지 이동하는 cycle을 말합니다.
지난 Policy Gradient Learning ( REINFORCEMENT) 살펴보기
Policy Gradient Learning
REINFORCE
REward Increment = Nonnegative Factor Offset Reinforcement Characteristic Eligibility
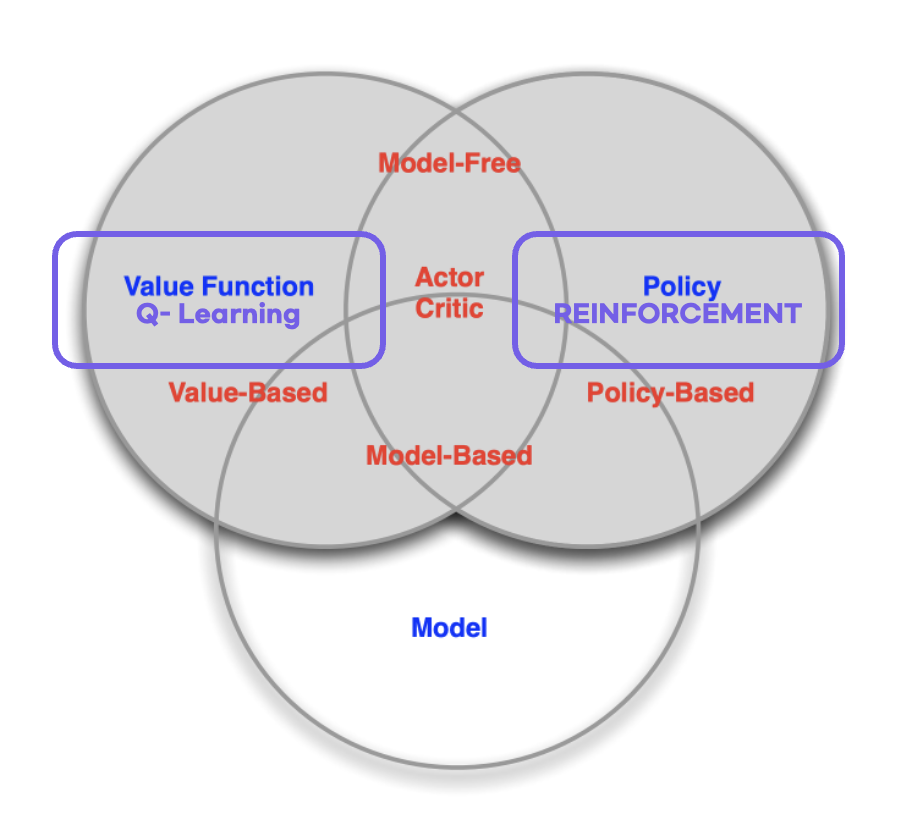
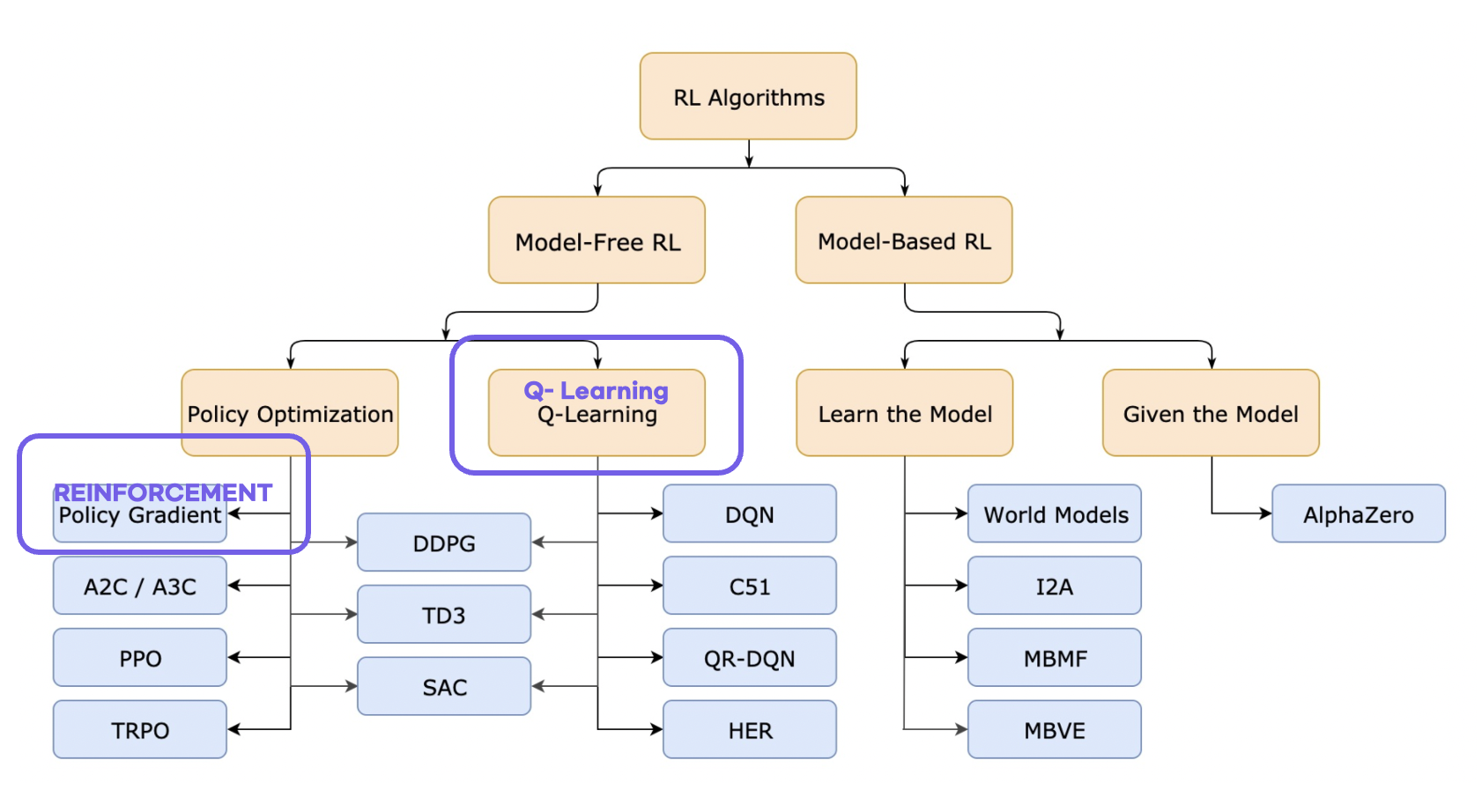
- Model Free Based Learning의 한 방식으로 Policy Gradient 방식으로 Q-learning의 한계점을 보완한 학습 방법, Q-table의 Value based 학습의 방식과 다르게 신경망을 이용하여 Softmax Regression 방식으로 action들의 확률을 구하고 분포를 얻어 학습하는 방식
- 장점 :
- Continuous Action space, Continuous State Space에서 활용가능
- Policy가 수렴이 잘됨
PPO ( Proximal Policy Optimization )
등장 배경 ( REINFORCE 의 단점 ) :
- Gradient를 이용하므로 경사가 너무 급격할 경우, 상반된 결과가 반복되어 안정적인 학습이 되기 어렵다.-> Learning_rate가 클때와 같은 효과

-> Learning_rate가 클때와 같은 효과 - Gradient를 이용했을 때 경사가 너무 작을 경우, 학습의 속도가 매우 느리다.-> Learning_rate가 작을 때와 같은 효과

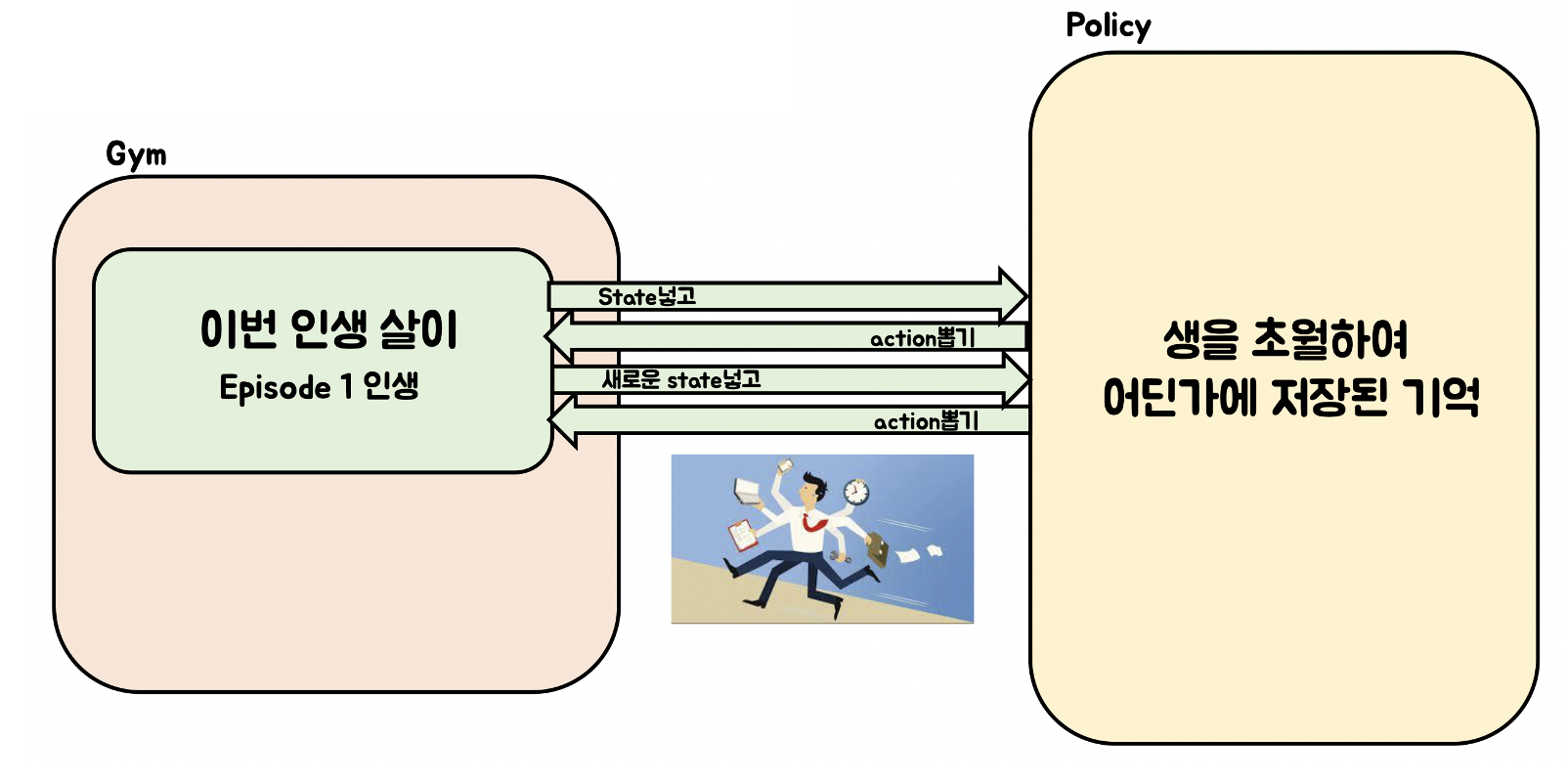
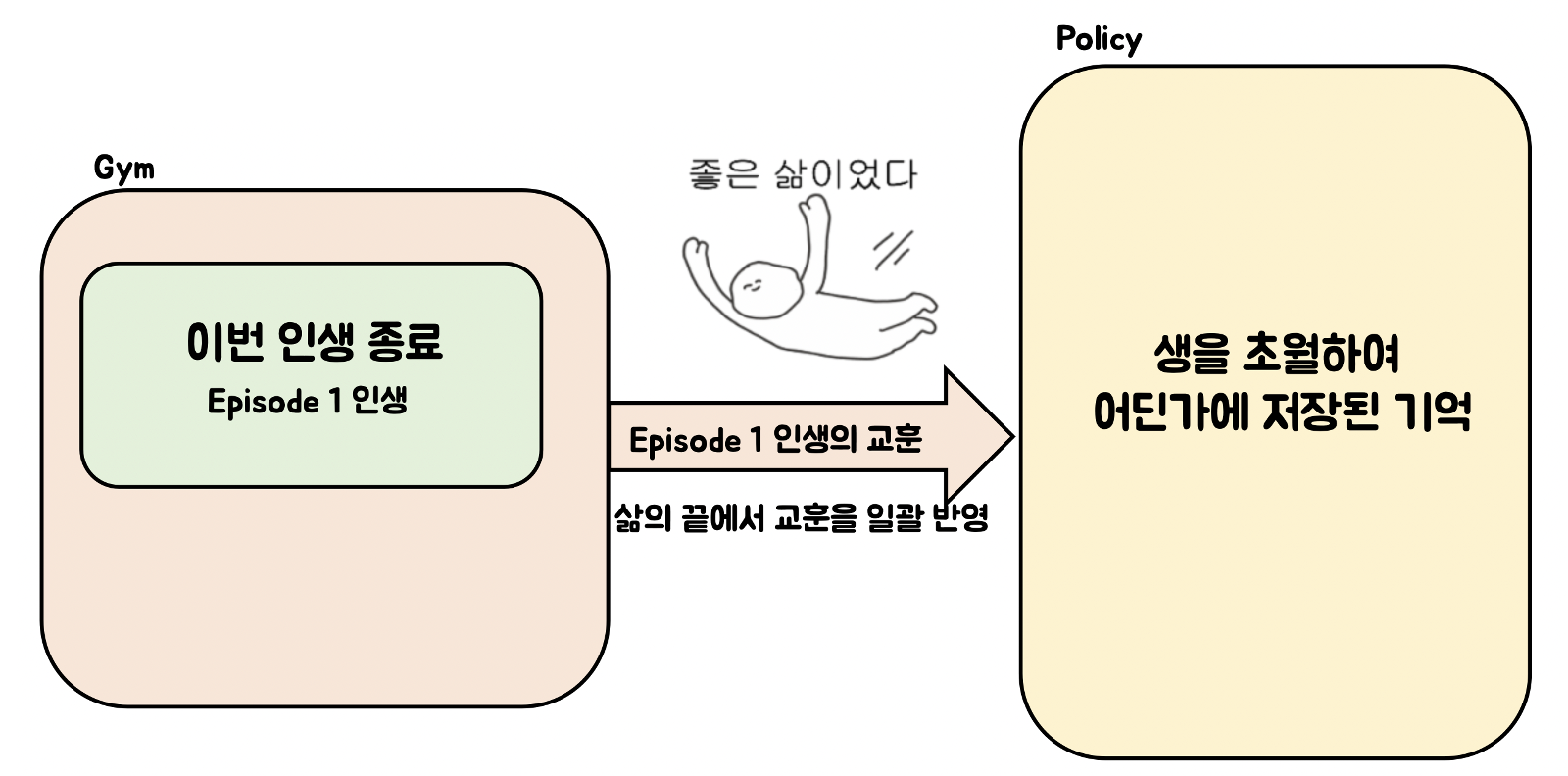
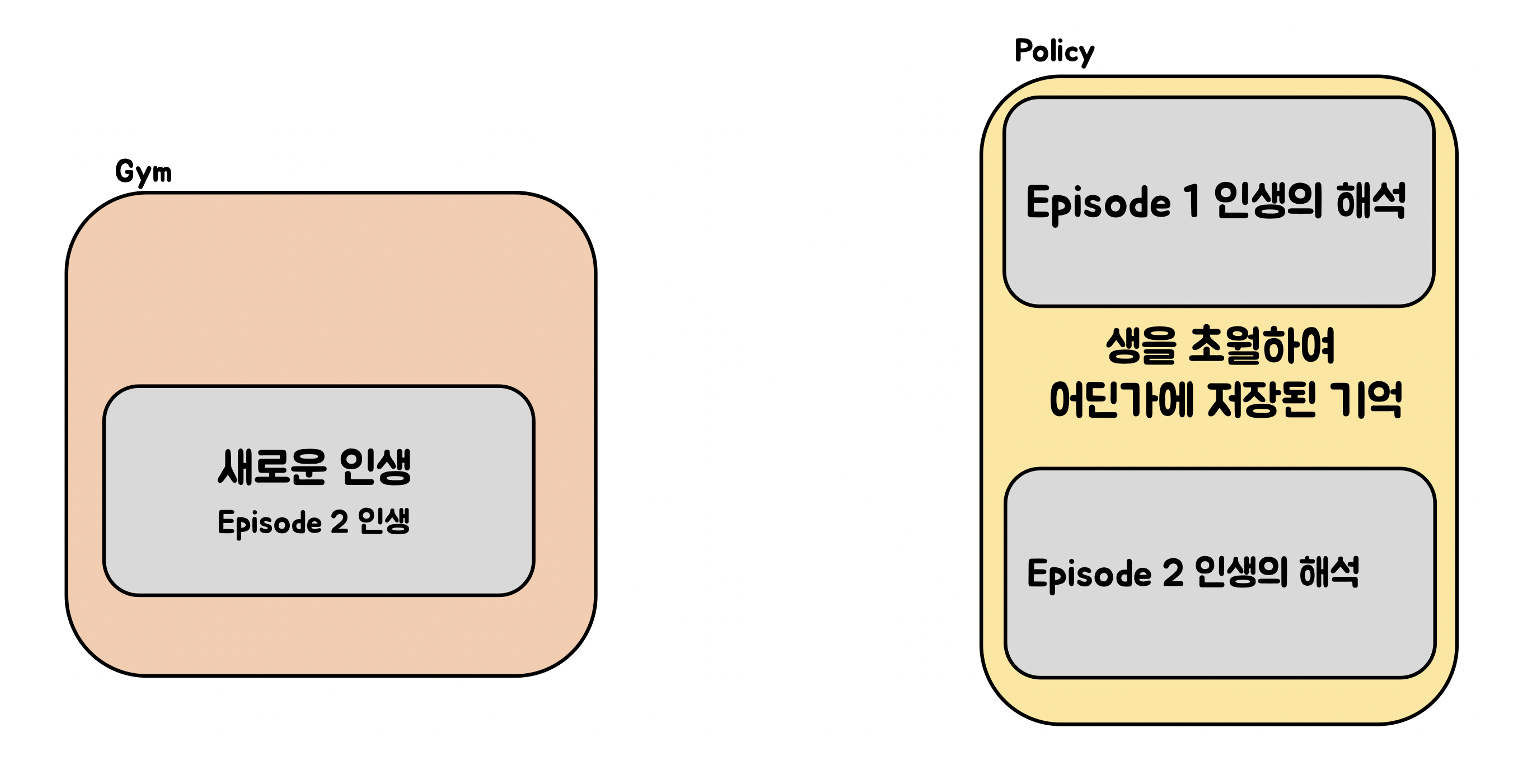
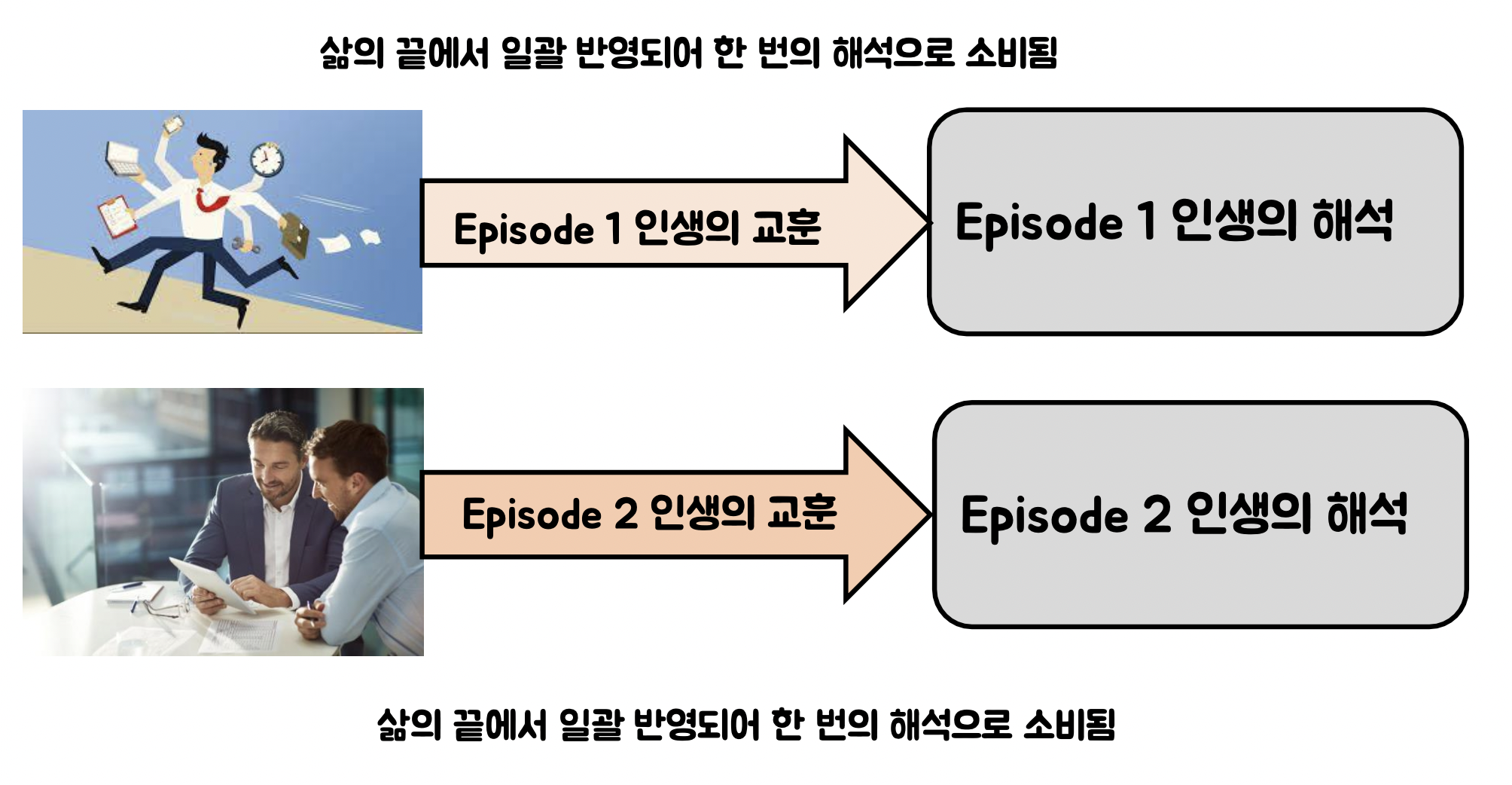
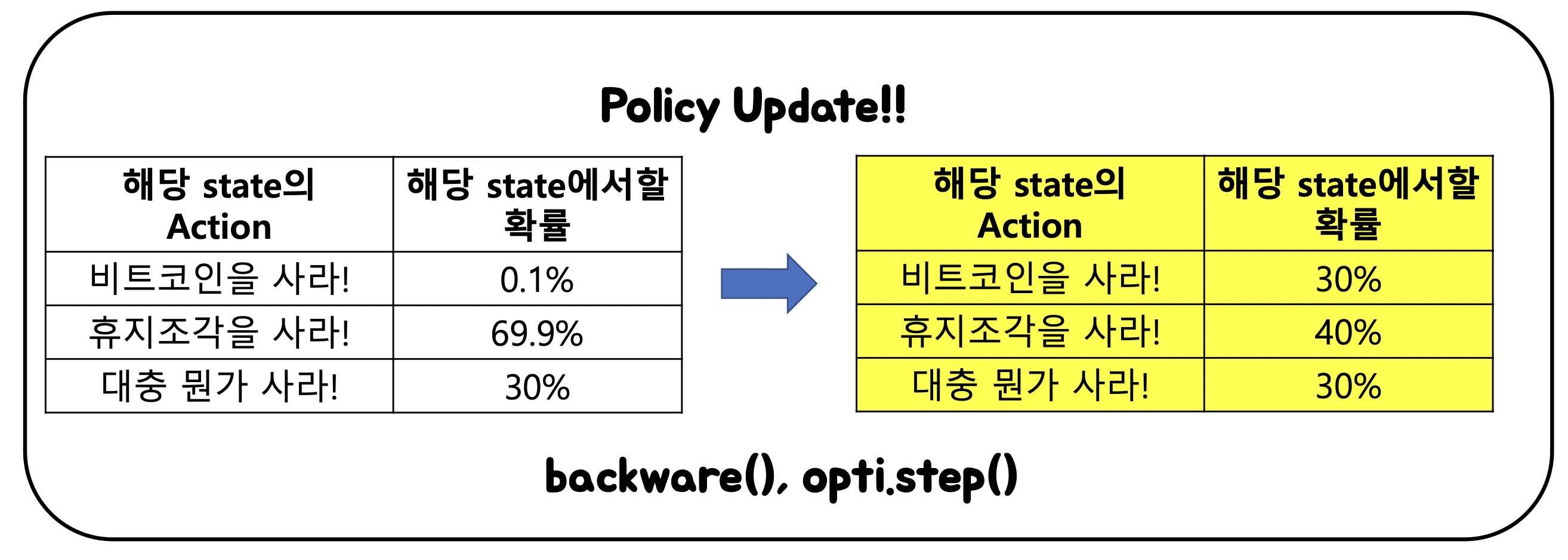
- Episode단위로 결과가 반영되어, 한 step내에서 학습된 결과가 반영되지 않은 채 episode가 진행된다. 즉, 사람의 생애로 봤을 때 하루, 하루의 결과가 그 생애에는 반영되지 않고, 생애 단위로 학습된 결과가 반영되어 학습이 된다. 즉 일괄 반영되어 한번의 해석으로 소비된다는 것이다. 즉 Episode내에서 step의 결과가 반영되지 않고, Episode단위로 학습이 되는 문제점을 가지고 있다.
 예시) 코인을 구매해야하는 상황
예시) 코인을 구매해야하는 상황
- 현재 상황은 1950년대 초반: 코인의 가치를 알지 못하므로 휴지를 사두는게 바람직함.
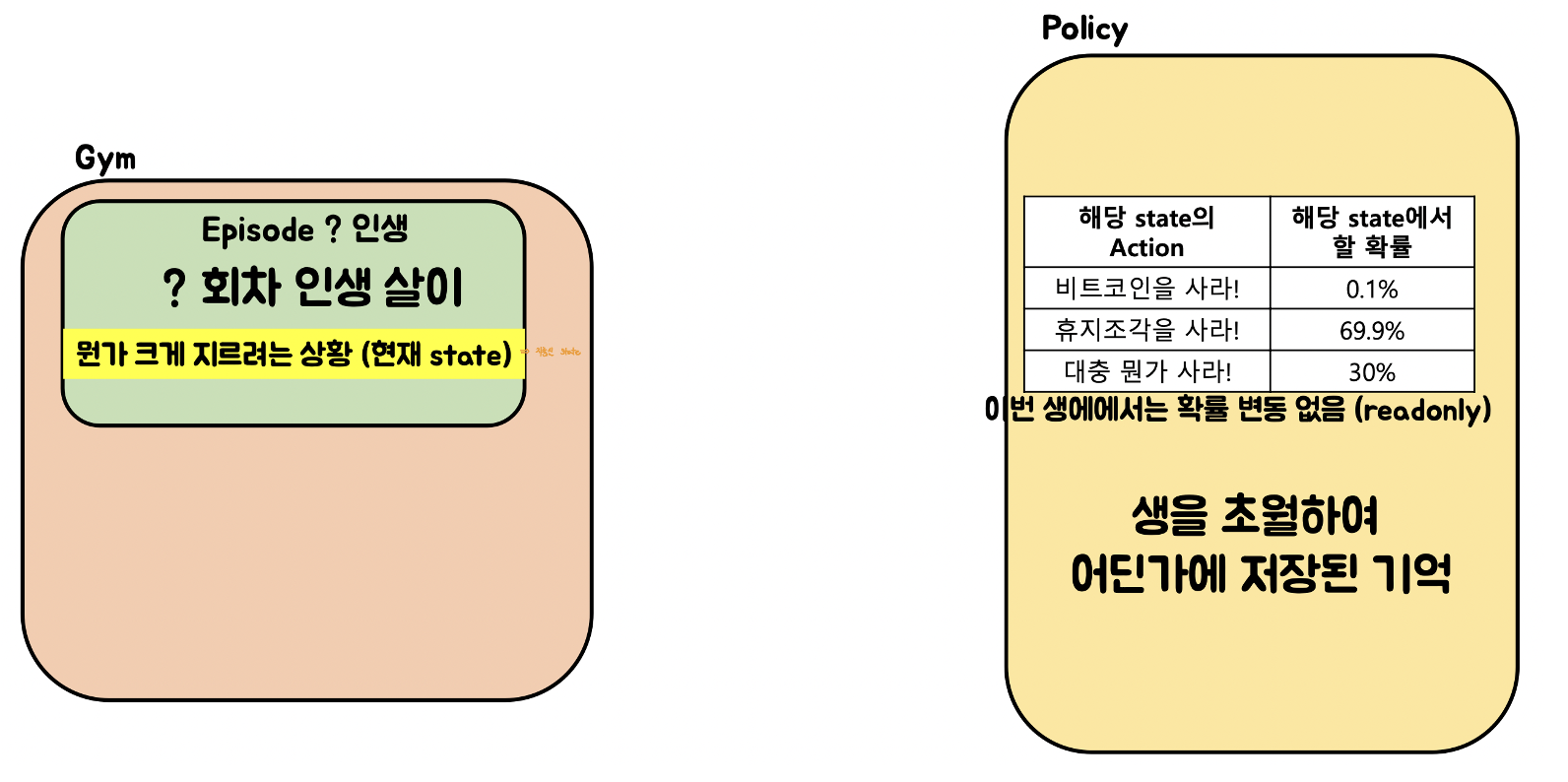
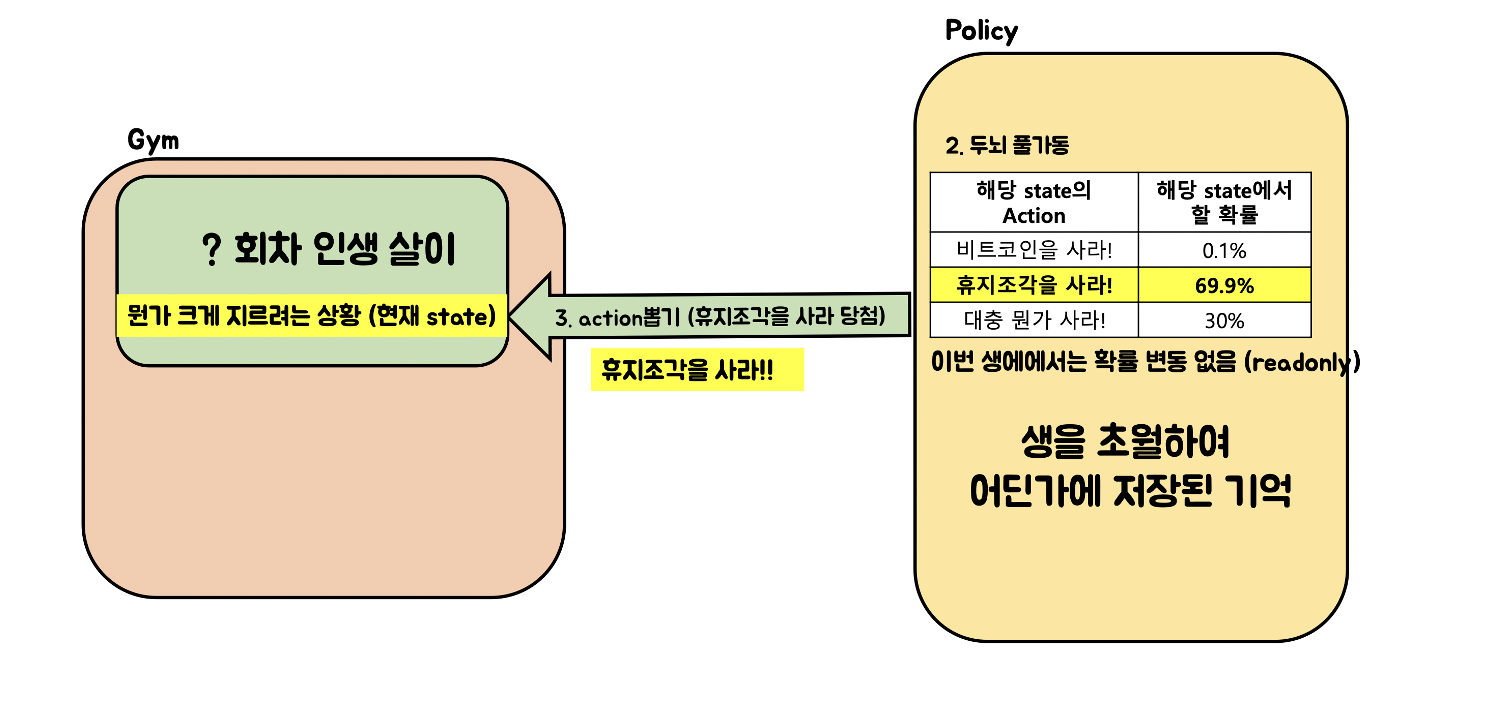
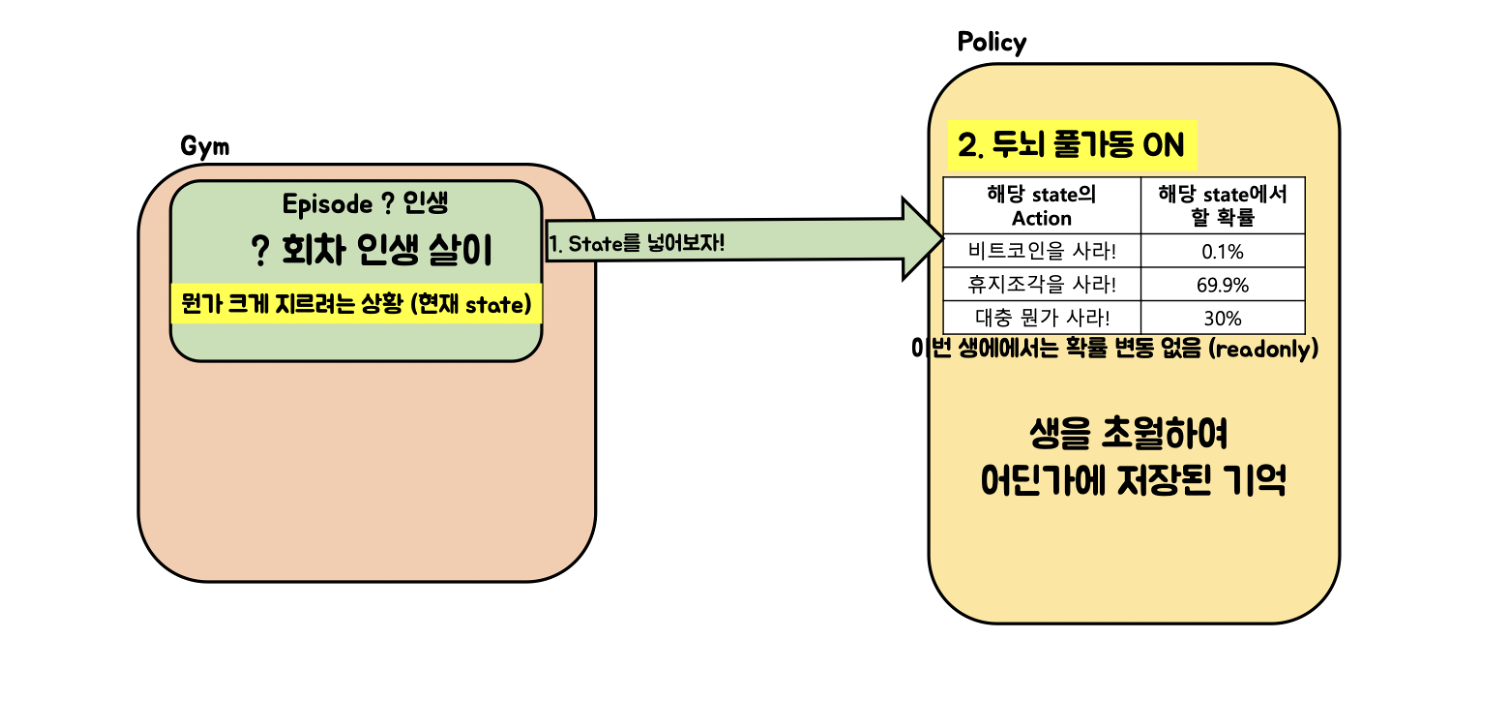
- 이제는 2014년: 코인이 오르기 전이므로 매수하는게 좋다. 따라서 올해가 지나고 나면 코인을 사야하는 확률이 매우 올라감. 하지만 이전에 학습된 확률 때문에 코인을 2014년도, 즉 해당 연도에 비트코인을 구매하는 건 매우 어려운 상황임
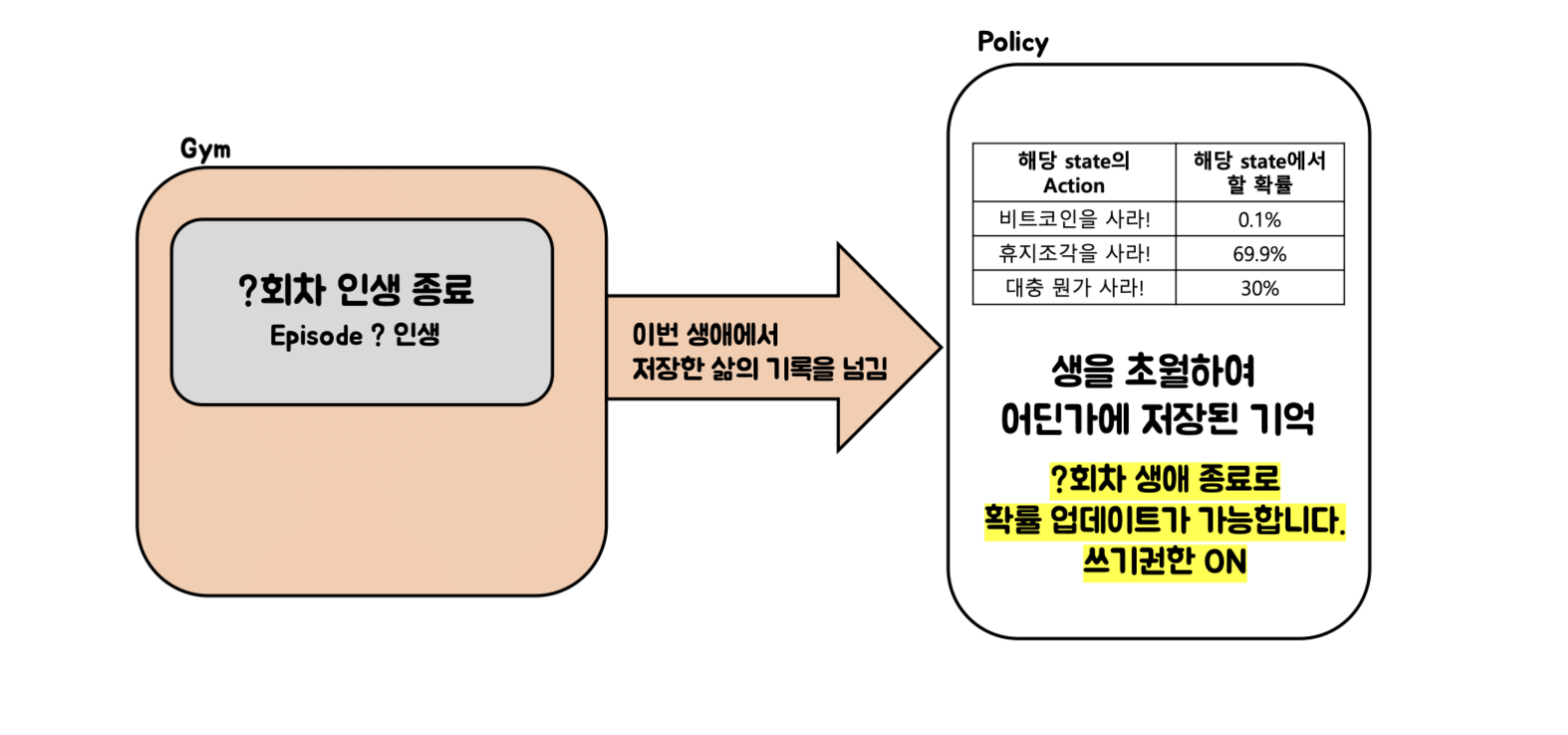

 따라서 다양한 State에서 이전 Episode 단위로 학습하는 것은 비효율성을 만들어 내기 때문에 Step에서 사용한 학습데이터를 활용할 수 있는 새로운 학습 방법이 필요한 상황임
따라서 다양한 State에서 이전 Episode 단위로 학습하는 것은 비효율성을 만들어 내기 때문에 Step에서 사용한 학습데이터를 활용할 수 있는 새로운 학습 방법이 필요한 상황임
PPO Definition
PPO는 TRPO처럼 "어떻게 하면 우리가 현재 가지고 있는 데이터를 효과적으로 사용하여, 퍼포먼스를 감소하지 않으면서 학습을 진행할 수 있을까?" 그리고 "이러한 방법을 만들기 위해서 어떠한 정책을 만들면될까?"에서 시작 되었습니다. ... PPO는 새로운 정책을 이전 정책에 가깝게 유지하기 위해 몇 가지 다른 트릭을 학습 방식입니다. 쉬운 구현과 적어도 TRPO이상의 성능을 가지고 있습니다. -OpenAI에서 내린 정의의역-
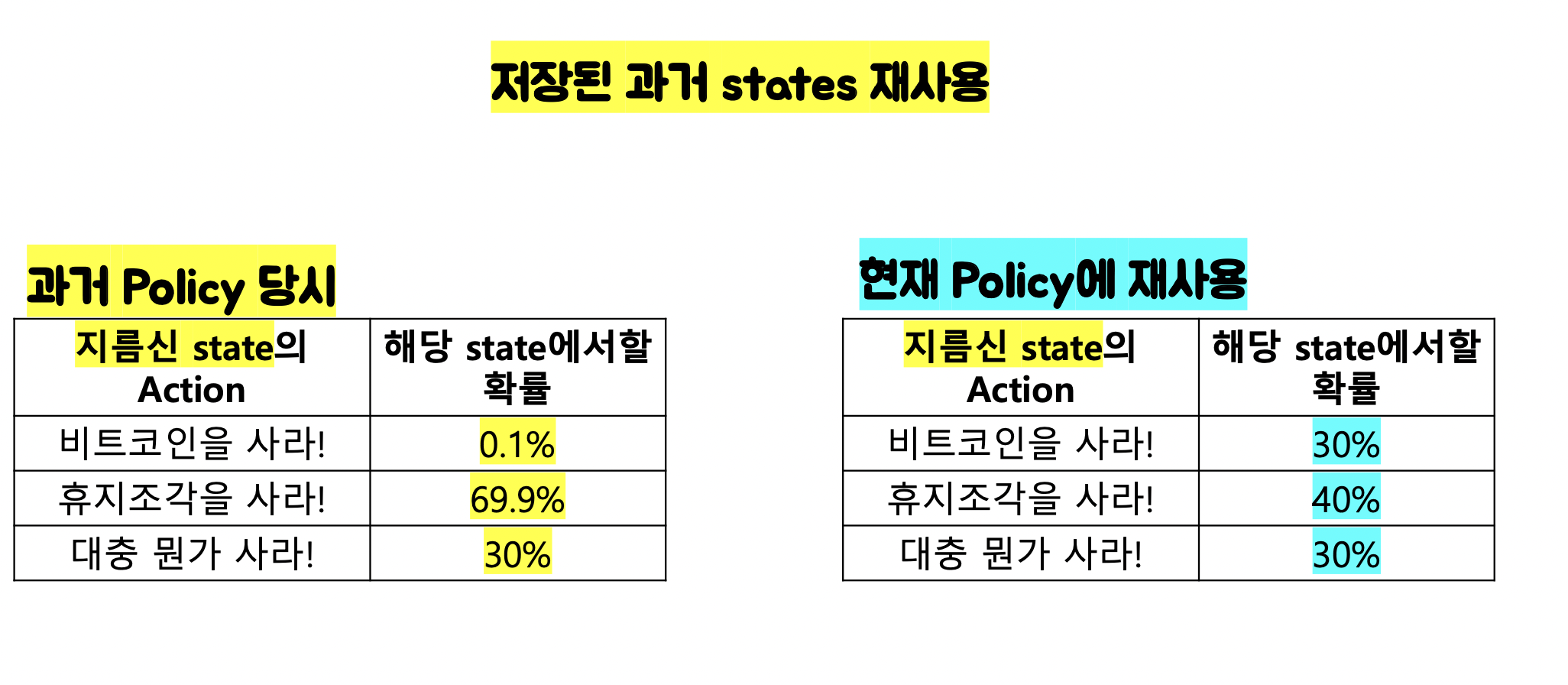
- 정의 : PPO(Proximal Policy Optimization)는 Model-Free based learning의 한 강화학습 방식으로 Policy Gradient Learning의 단점을 보안한 모델입니다. 학습데이터를 재사용하는 모델로, Episode 단위로 반영하는 것이아닌 Step 단위로 학습데이터를 만들어 내어 학습하는 방식으로 학습 효과를 높이는 방식을 취하고 있습니다.
- 특징 :
1. 소비했던 데이터를 다시 쓰기(데이터 재사용)
2. Episode가 끝난 뒤 결과를 반영하는데 아니라, step단위로 학습에 반영하기
3. Importance Sampling을 이용하는데, importance는 ratio = ( 최신 log P / 구형 log P ) [ratio가 클수록 중요] 이용하여 값을 보정하여 상하한선을 만들어주고, PPO에서는 다음 미래까지 반영하게 된다. 또한 신경망 Actor/Critic 2개의 신경망이 존재해, Action이 올바르게 되었는지 Critic 신경망이 평가하는 방식으로 성능을 보완해나갑니다.

사회적 가치를 실현하는 프로그래머