DDPG (Deep Deterministic Policy Gradient)
들어가기 전에 살펴봐야 할 것들
DQN(Deep Q-learning Network)
- 기존 Q-learning을 신경망을 이용해서 개선한 모델
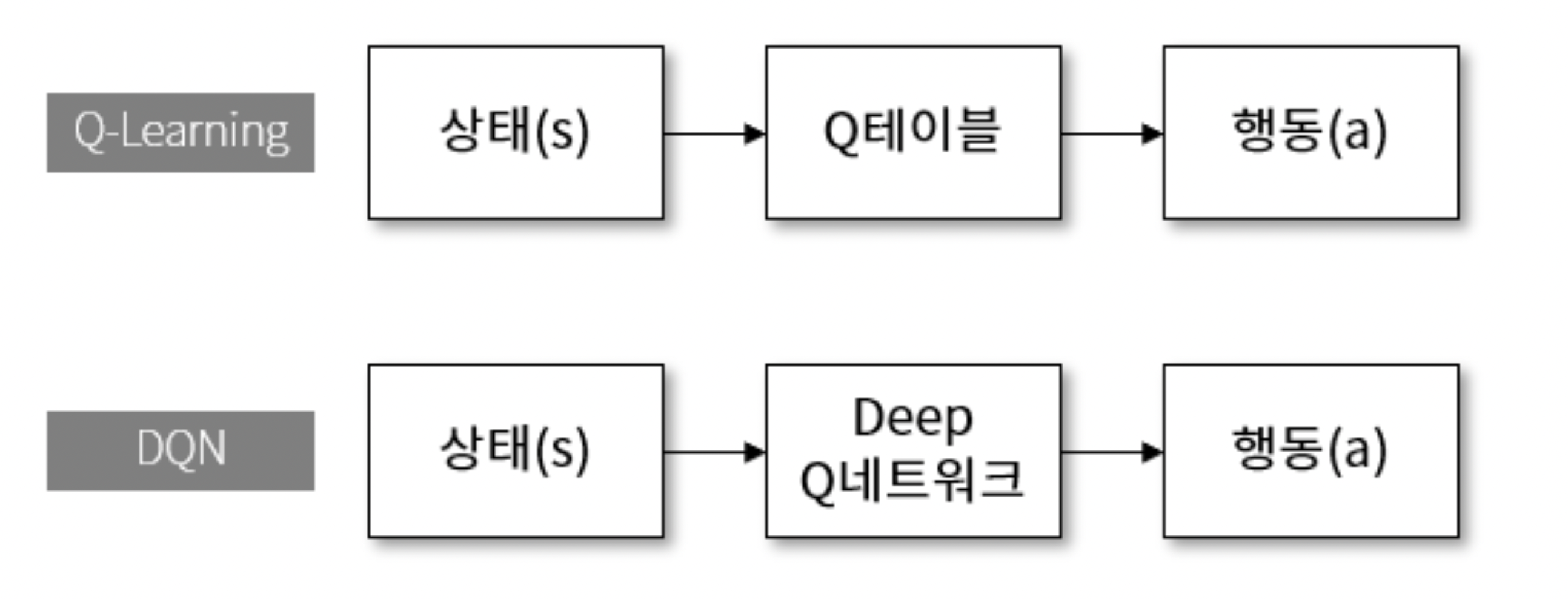
- 단점 : Discrete한 경우 밖에 적용이 되지 않음
=> 보안한 방식이 DDPG(Deep Deterministic Policy Gradient
+) 네이쳐지 참고하기
Actor-Critic Algorithm(in PPO)
- Actor와 Critic신경망이 따로 존재

Actor: 리워드가 높은데, 낮은 logP가 될 수 없도록 조절
- 역할 : State을 받아 Action을 뽑아주는 역할
- 손실함수 = - (리워드 * logP)에서 logP조절
- 리워드는 상관하지 않고 오직 logP만 조절
- logP가 중요
Critic : 현재가치가 예상이익에서 멀어지지 못하도록 조절
- 역할 : state를 넣고 Value를 뽑아주는 역할
- 각 상태의 예상이익은 Episode별로 계산되어 고정
- 손실함수 = (예상이익 - 현재가치)^2
- 예상이익은 건들이지 않고, 현재가치만 조절
- Critic Value가 중요
최종 손실 함수
- 최종 손실함수 = Actor손실함수 + Critic손실함수
- 따라서 Total loss를 줄일 수 있도록 학습.
- 최적의 Probability와 critic value를 구할 수 있는 방향으로 학습을 하게됨.
DDPG (Deep Deterministic Policy Gradient) 정의
- DDPG는 구글 딥마인드에서 만든 모델로 DQN을 개선한 Model-Free Reinforce Learning 중 하나의 학습 방법으로 replay buffer를 추가한 off-policy algorithm입니다. DDPG는 오로지 Continous Action Space에서 만 활용이 가능하며 Deep Q-learning 방식을 continuous action space에 적용한 학습 방법으로 볼 수 있습니다.
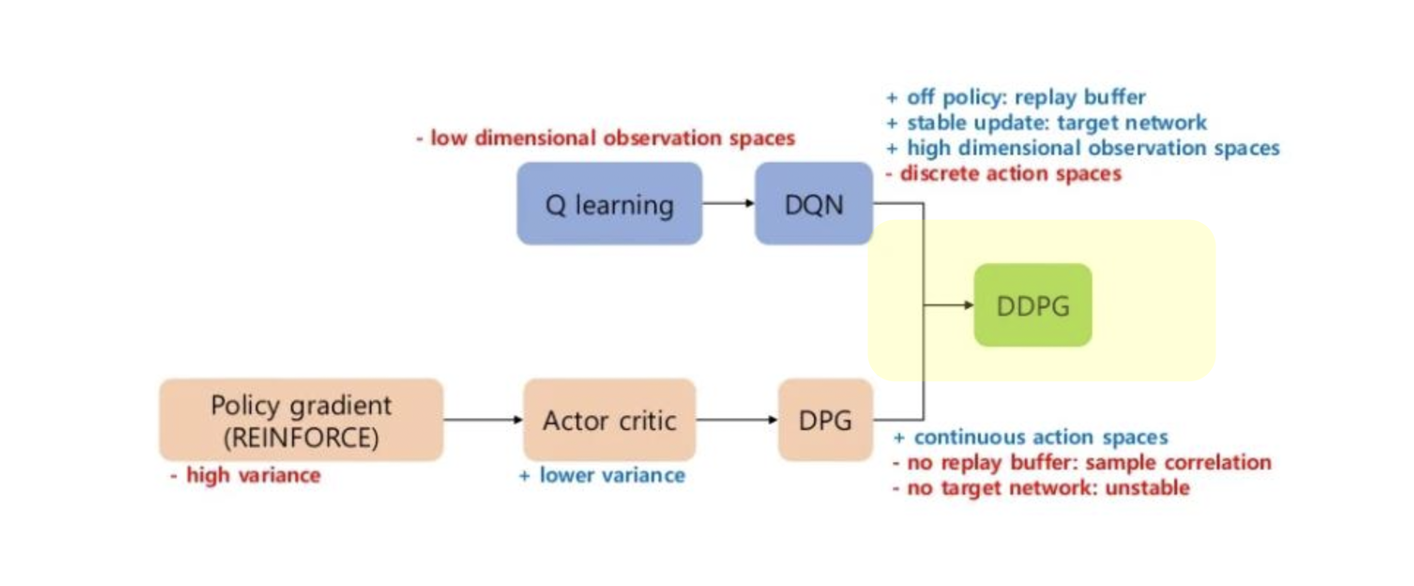
=> 모형 : 마치 DPG(Deterministic Learning) + DQN(Deep Q-learning Network)를 합성한 형태.
=> 장점도 Deep Q-learning처럼 신경망을 이용한 장점과, DPG의 Continuous Space에 대한 학습을 할 수 있도록 하는 효과를 만들어낸다.
DDPG의 핵심 3가지
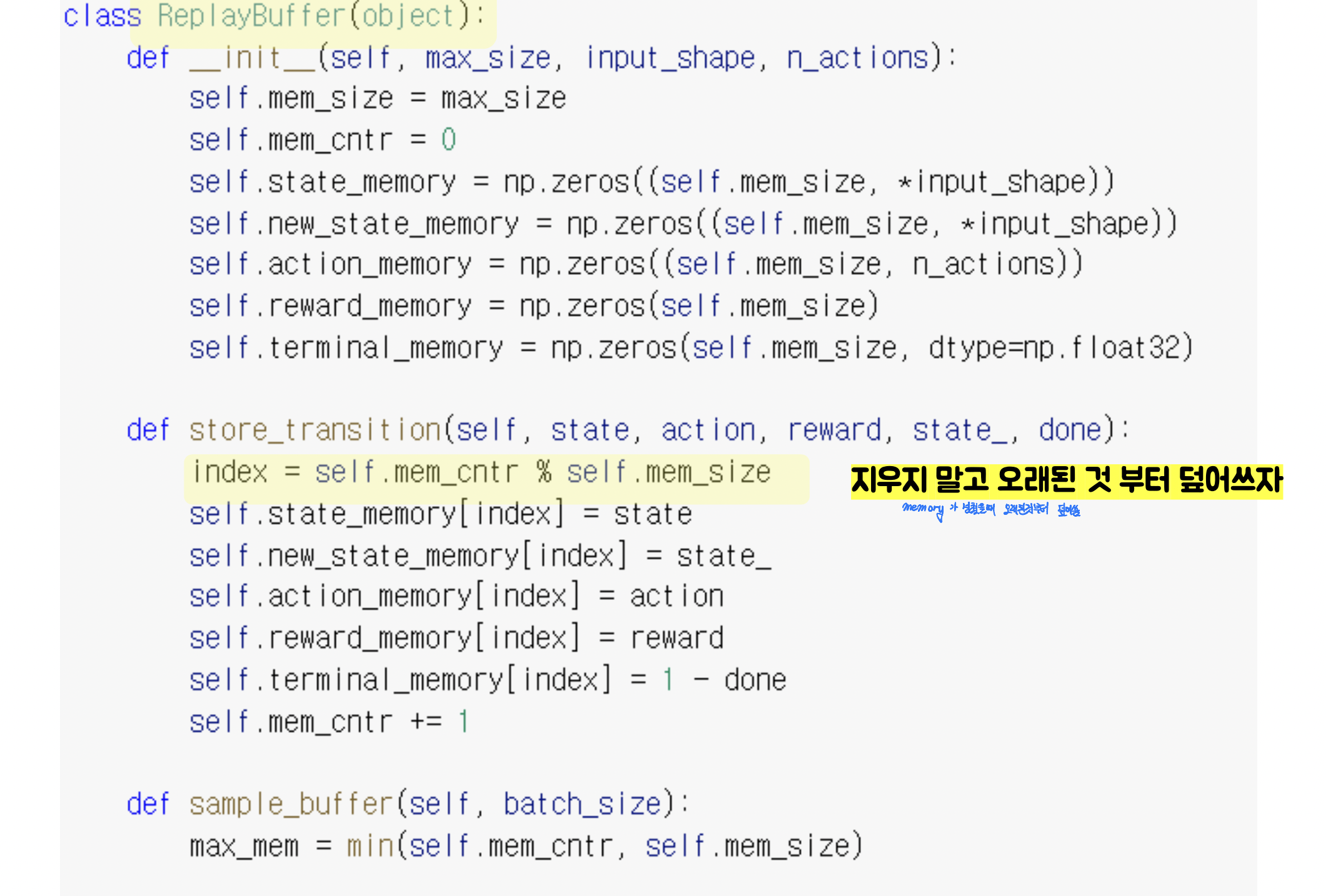
1. Replay Buffer
- 기존 학습 방식에는 학습하는 순서가 어느 정도 정해져 있기 때문에 Exploration의 랜덤성과 균일성이 떨어지는데, replay buffer에 모든 내용을 step에 저장하고 실제 학습은 replay buffer에서 random하게 뽑아쓰는 방식을 택하여 이와 같은 문제점을 해결하여 agent 학습 성능을 높여주었다. (단, buffer는 clear되지 않으며 buffer를 키우고 오래된 데이터에 덮어쓰는 방식으로 학습이 진행됩니다. )
=> Exploration이 정해진 방식으로 탐색되는 고질적인 문제를 벗어나는 핵심 기법!

2. Target network
1. Actor Critic을 사용
2. 고정된 정답지인 Actor-critic을 또 같고 있음 (총 2+2 = 4 개의 신경망 사용)
3. 고정된 정답지를 서서히 업데이트
Loss function
-> Critic은 정답지와 자신의 예측치를 줄이는 방식으로
-> Actor는 Critic의 감정값을 극대화하는 방식으로 학습
3. Action noise
- Exploration을 잘하기 위해 Action noise를 추가해주는데, 이는 action에다가 random값을 더 해주는 것이다. OU process를 이용하여 ε-Greedy 방식으로 값이 나올 수 있도록 하는 것이다.
OU Process란? Ornstein–Uhlenbeck process라고 하며 물리, 수학과 관련 되는 stochastic process로 Gaussian process, a Markov process와 같은 방식으로 해당 하는 값에 noise를 부여하는 것이다.
PPO와 비교
| 항목 | PPO | DDPG |
|---|---|---|
| Policy | Stochastic | deterministic |
| on/off | on-policy | off-policy |
- 이해하기 쉽고(바로 action출력), 초반부터 퍼포먼스가 우수함(Exploration 성능이 높음)
On-Policy Vs Off-Policy
- On-policy : 학습하는 policy와 행동하는 policy가 반드시 같아야만 학습이 가능한 강화학습 알고리즘.
on-policy의 경우 이론상 1번이라도 학습을 해서 policy improvement를 시킨 순간, 그 policy가 했던 과거의 experience들은 모두 사용이 불가능하다. 즉 매우 데이터 효율성이 떨어진다. 한 번 exploration해서 얻은 experience를 학습하고나면 그냥은 재사용이 불가능하다.(Importance sampling등을 해야만 재사용가능 함.)
- Off-policy : 학습하는 policy와 행동하는 policy가 반드시 같지 않아도 학습이 가능한 알고리즘.
off-policy는 현재 학습하는 policy가 과거에 했던 experience도 학습에 사용이 가능하고, 심지어는 해당 policy가 아니라 예를 들어 사람이 한 데이터로부터도 학습을 시킬 수가 있다. 과거 데이터로만 학습하는 경우는 offline RL이라고도 부른다.
