
아키텍처란?
- 소프트웨어 아키텍트의 근본은 결국 프로그래머.
- 소프트웨어 아키텍트는 소프트웨어 시스템이 쉽게 개발, 배포, 운영, 유지보수되는 작업을 용이하게 해야 하며, 이를 위해 가능한 많은 선택지를 제공해야한다.
- 아키텍처의 주된 목적은 동작이 아닌 시스템의 생명주기를 지원하는 것.
- 좋은 아키텍처는 프로그래머의 생산성을 최대화한다.
개발
- 시스템 아키텍처는 시스템을 쉽게 개발할 수 있도록 뒷받침해야 한다.
- 개발 인력이 적은 팀의 경우 오히려 아키텍처적 제약이 개발에 방해를 줄 수 있지만, 그 규모가 커진다면 잘 설개가 되지 않을 경유 개발이 진척되지 않는다.
배포
- 소프트웨어 아키텍처는 시스템을 단 한 번에 쉽게 배포할 수 있도록 만들어야 한다.
운영
- 아키텍처가 시스템 운영에 미치는 영향은 개발, 배포, 유지보수 보다는 덜하다.
- 운영에서 겪는 대다수의 어려움은 대부분 하드웨어를 더 투입해서 해결.
- 비용적 관점에서 운영보다는 개발, 배포, 유지보수 쪽에 더 중점을 두는 것이 현명하다.
- 좋은 소프트웨어 아키텍처는 시스템을 운영하는 데 필요한 요구를 알려준다.
- 시스템 아키텍처는 유스케이스, 기능, 시스템의 필수 행위를 일급 엔티티로 격상시키고, 이들 요소가 개발자에게 주요 목표로 인식되도록 해야 한다.
- 이를 통해 시스템을 이해하기 쉬워지며, 개발과 유지보수에 큰 도움이 된다.
유지보수
- 유지보수는 소프트웨어 시스템에서 비용이 가장 많이 든다.
- 기존 코드를 유지보수 하려면 탐사를 해야되며 이로 인한 위험 부담이 있다.
- 신중하게 아키텍처를 만들면 해당 비용을 크게 줄일 수 있으며, 의도치 않은 장애가 발생할 위험을 크게 줄일 수 있다.
선택사항 열어 두기
소프트웨어를 부드럽게 유지하려면 중요치 않은 세부사항을 열어 둬야한다.
소프트웨어는 정책과 세부사항으로 구분이 가능
- 정책 : 모든 업무 규칙과 업무 절차를 구체화하는 요소, 시스템의 진정한 가치가 살아 있는 곳이다.
- 세부사항 : 사람, 외부 시스템, 프로그래머가 정책과 소통할 때 필요한 요소이지만 정책이 가진 행위에는 영향을 미치지 않는 것. 예시로 입출력 장치, 데이터베이스, 웹 시스템, 서버, 프레임워크, 통신 프로토콜 등이 있다.
아키텍트의 목표는 시스템에서 정책을 가장 핵심적인 요소로 식별하고, 세부사항은 정책에 무관하게 만들 수 있는 시스템을 구축하는 것.
장치 독립성
- 프로그래밍 초창기에는 코드를 장치 종속적으로 짰다.
- 하지만 관리해야 될 데이터의 양이 많이지고 데이터의 무결성이 중요해짐.
- 데이터 무결성을 위해서 장치 독립성을 생각해 냈다.
결론
- 좋은 아키텍트는 세부사항을 정책으로부터 신중하게 가려내고, 정책이 세부사항과 결합되지 않도록 엄격하게 분리.
- 좋은 아키텍트는 세부사항에 대한 결정을 가능한 오랫동안 미룰 수 있는 방향으로 정책을 설계.
독립성
좋은 아키텍처는 아래의 것들을 지원해야 한다.
1. 시스템의 유스케이스
2. 시스템의 운영
3. 시스템의 개발
4. 시스템의 배포
유스 케이스
- 시스템의 의도를 지원해야 한다.
- 시스템의 유스케이스가 시스템 구조 자체에서 한눈에 드러나야 한다.
운영
- 아키텍처는 더 실질적이며 덜 피상적인 역할을 맡는다.
- 시스템의 유스케이스에 기반을 해 알맞은 서비스 방식을 채택해야한다.
개발
- 콘웨이 법칙 : 시스템을 설계하는 조직이라면 어디든지 그 조직의 의사소통 구조와 동일한 구조의 설계를 만들어 낼 것이다.
다양한 조직에서 어떤 시스템을 개발해아 한다면 각 팀이 독립적으로 행동하기 편한 아키텍처를 구축해야한다.
배포
- 아키텍처는 배포 용이성을 결정하는 데 중요한 역할을 한다.
- 좋은 아키텍처라면 시스템이 빌드된 후 즉각 배포할 수 있도록 지원해야 한다.
- 시스템을 컴포넌트 단위로 적절하게 분할하고 격리 시켜야 한다.
- 마스터 컴포넌트는 시스템 전체를 하나로 묶고, 각 컴포넌트를 올바르게 구동하고 통합하고 관리해야 한다.
선택사항 열어 놓기
- 컴포넌트 구조와 관련된 관심사들 사이에서 균형을 맞추고 각 관심사를 모두 만족시키는 것은 쉽지 않다.
- 좋은 아키텍처는 선택사항을 열어 두어 향후 시스템에 변경이 필요할 때 어떤 방향으로든 쉽게 변경할 수 있도록 한다.
계층 결합 분리
시스템의 다른 규칙들을 서로 분리하고 독립적으로 변경할 수 있도록 해야 한다.
유스케이스 결합 분리
- 유스케이스는 시스템을 분할하는 자연스러운 방법임과 동시에 시스템의 수평적인 계층을 가로지르도록 자른, 수직으로 좁다란 조각.
- 시스템의 맨 아래 계층까지 수직으로 내려가며 유스케이스들이 각 계층에서 서로 겹치지 않게 해야 한다.
- 시스템에서 서로 다른 이유로 변경되는 요소들의 결합을 분리하면 기존 요소에 지장을 주지 않고 새로운 유스케이스를 추가하는 것이 가능.
결합 분리 모드
- 서비스에 기반한 아키텍처를 서비스 지향 아키텍처라고 부른다.
- 때때로 컴포넌트를 서비스 수준까지도 분리해야 한다.
개발 독립성과 배포 독립성
- 유스케이스가 분리가 되면 개발과 배포를 독립적으로 실행할 수 있다.
중복
- 진짜 중복 : 한 인스턴스가 변경되면, 동일한 변경을 그 인스턴스의 모든 복사본에 반드시 적용 필요
- 우발적 중복 : 중복으로 보이는 두 코드 영역이 각자의 경로로 발전하면 진짜 중복으로 볼 수 없다.
유스케이스를 수직으로 분리할 때 비슷한 유스케이스를 통합하고 싶은 유혹이 있지만, 진짜 중복인지 잘 확인해봐야 한다.
분리
분리에는 소스 수준, 배포 수준, 서비스 수준 분리가 있다.
1. 소스 수준 분리 : 소스 코드 모듈 사이의 의존성 제어. 모든 컴포넌트가 같은 주소 공간에서 실행되고, 서로 통신할 때는 함수 호출을 사용(모놀리딕 구조)
2. 베포 수준 분리 : 배포 가능한 단위들 사이의 의존성 제어. 많은 컴포넌트가 같은 주소 공간에 상주하나 어떤 컴포넌트는 동일한 프로세서의 다른 프로세스에 상주하고 프로세스 간 통신을 진행.
3. 서비스 수준 분리 : 모든 실행 가능한 단위는 소스와 바이너리 변경에 서로 독립적이게 된다.(MSA)
일반적으로 서비스 수준에서의 분리가 가장 이상적.
하지만 좋은 아키텍처는 이러한 분리 또는 나중에 결합을 진행해야 되는 상황에서 유동적으로 대처할 수 있게 해줘야 한다.
결론
시스템의 결합 분리 모드는 시간이 지나면서 바뀌기 쉬우며, 뛰어난 아키텍트라면 이러한 변경을 예측하여 반영할 수 있도록 해야한다.
경계 : 선 긋기
- 소프트웨어 아키텍처는 경계라는 선을 긋는 기술.
- 경계는 소프트웨어 요소를 분리하고, 경계를 기준으로 독립적이여야 한다.
- 아키텍트의 목표는 시스템을 만들고 유지하는 데 드는 인적 자원을 최소화하는 것인데, 결합 과정에서 효율성이 떨어질 가능성이 있다.
- 유스케이스와 아무런 관련이 없는 결정에 따른 이른 결합이 효율성 저하를 이르킬 가능성이 높다.
어떻게 선을 그을까?
GUI, 업무규칙, 데이터 베이스는 서로 관련이 없으므로 경계가 있어야 한다.
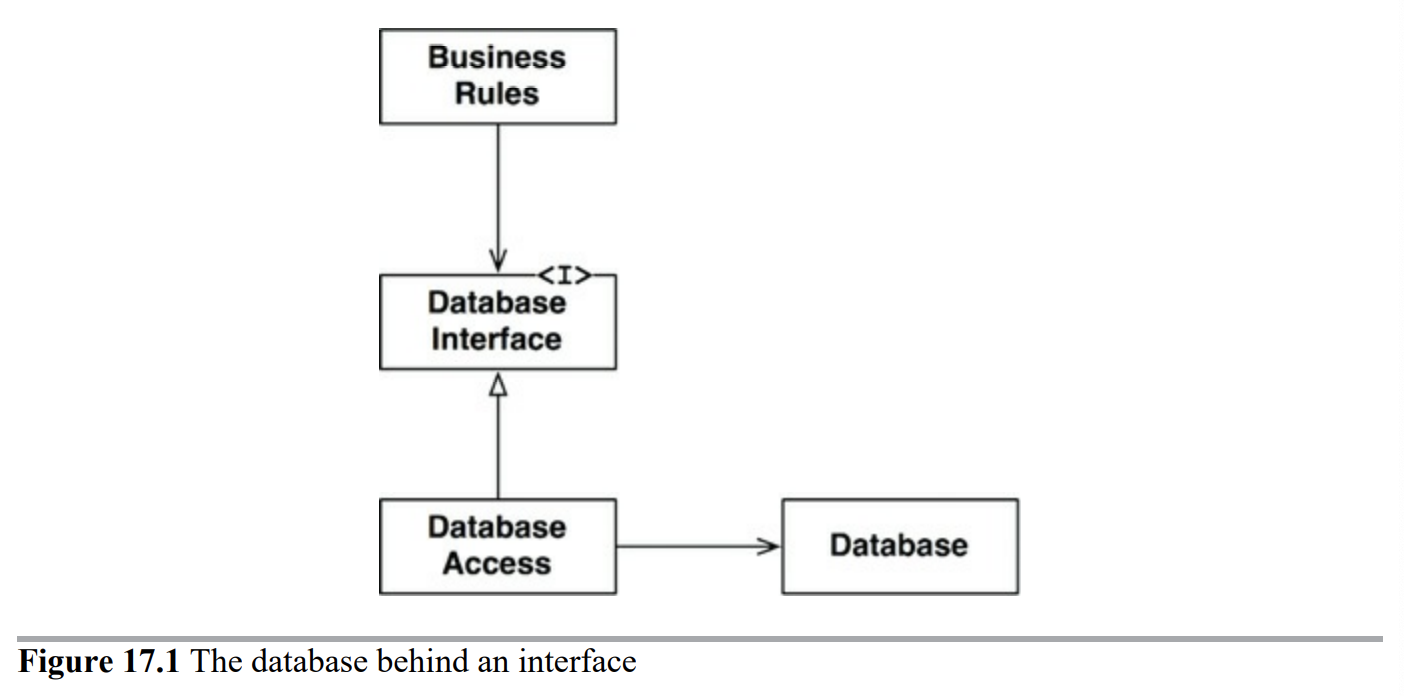
위 그림과 같이 Database Access라는 Database Interface의 구현체를 통해 DB에 접근하도록 해야한다(Spring Data Jpa가 인터페이스로 구현 된 이유가 이런 이유).
BusinessRules를 중점으로 GUI와 데이터베이스가 BusinessRules를 바라보는 형식의 설계를 해야한다.
이를 통해 GUI와 데이터베이스가 변경이 되더라도 업무규칙이 깨질일이 발생하지 않는다.
결론
- 소프트웨어 아키텍처에서 경계선을 그리면서 먼저 시스템을 컴포넌트 단위로 분할.
- 컴포넌트 사이의 화살표가 핵심 업무를 향하도록 배치.
- 의존성 화살표는 저수준 세부사항에서 고수준의 추상화로 향하도록 배치.
경계 해부학
시스템 아키텍처는 일련의 소프트웨어 컴포넌트와 그 컴포넌트들을 분리하는 경계에 의해 정의.
경계 횡단하기
- 경계 한쪽에 있는 기능에서 반대편 기능을 호출하여 데이터를 전달하는 일.
- 소스 코드 모듈에서 하나가 변경되면 이에 의존한 다른 소스코드 모듈도 변경해야 하기 떄문에 소스 코드 의존성 관리를 잘하는 것이 핵심적이다.
단일체
- 데이터가 단일 프로세서에서 같은 주소 공간을 공유하며 나름의 규칙에 따라 분리 되어 있는 형태.
- 하나의 jar 파일 안에 묶인 자바 클래스 파일이 대표 예시.
- 배포 관점에서 단일체의 경계가 들어나지 않지만, 그렇다고 존재하지 않는 것은 아니다.
- 의존성의 역전을 통해 고수준 컴포넌트를 저수준 컴포넌트로 부터 보호 할 수 있다.
- 컴포넌트 간 통신이 빠르고 값이 싸다는 장점이 있다.
배포형 컴포넌트
- 아키텍처의 경계가 물리적으로 드러난 경우.
- 배포 과정만 다를 뿐 단일ㄹ체와 동일하다.
- 모든 함수가 동일한 프로세서와 주소 공간에 위치하며, 컴포넌트의 의존성 관리와 분리 전략도 동일.
- 컴포넌트의 경계를 가로지르는 통신은 함수 호출에 지나지 않아 비용이 싸다.
스레드
- 스레드는 아키텍처의 경계도 아니고 배포 단위도 아니며 실행 계획과 순서를 체계화하는 방법.
로컬 프로세스
- 강한 물리적인 경계.
- 여러 프로세스들이 돌깁된 주소 공간에서 실행이 되고, 메모리 보호를 통해 프로세스들이 메모리를 공유하지 못한다.
- 소켓, 메일박스, 메시지 큐와 같은 통신 기능을 이용해 서로 통신.
- 로컬 프로세스의 의존성 화살표도 고수준 컴포넌트를 향해야 하는 것은 동일.
- 하지만 컴포넌트 간 통신은 비용이 비교적 높은 편이기 때문에 주의 필요.
서비스
- 가장 강한 물리적인 경계.
- 서비스 경계를 지나는 통신은 함수 호출에 비해 매우 느리다. 따라서 빈번하게 통신하는 일을 피해야 한다.
- 고수준 프로세스가 저수준 프로세스의 정보를 포함해서는 안된다.
결론
한 시스템 안에서도 통신이 빈번한 로컬 경계와 지연을 중요하게 고려해야 하는 경계가 혼합되어 있음을 의미.
정책과 수준
- 소프트웨어 시스템은 정책을 기술한 것.
- 하나의 정책은 이 정책을 서술하는 여러 개의 조그만 정책들로 쪼개는 것이 가능.
- 소프트웨어 아키텍처를 개발하는 기술에는 이러한 정책을 분리하고, 변경에 따라 재편하는 것.
- 좋은 아키텍처라면 의존성 방향이 저수준 컴포넌트가 고수준 컴포넌트에 의존하는 방식으로 설계가 돼있어야 한다.
수준
- 입력과 출력까지의 거리.
- 입력과 출력을 다루는 정책은 시스템 최하위에 위치하고, 입력과 출력으로 부터 멀어지면 고수준의 정책.
- 의존성 방향이 고수준 정책을 바라보게 한다면 저수준에서 변경이 생겨도 고수준에는 영향을 적게 준다.
업무 규칙
- 업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차(컴퓨터가 실행하든 수동으로 하든 본질은 같음).
- 핵심 업무 규칙은 일반적으로 데이터가 필요하며, 이런 데이터가 핵심 업무 데이터.
- 핵심 규칙과 핵심 데이터는 본질적으로 결합되어 있기 때문에 객체로 만들기 좋은 후보이고 이들을 엔티티로 부른다.
엔티티
- 컴퓨터 시스템 내부의 객체로서, 핵심 업무 데이터를 기반드오 동작하는 일련의 조그만 핵심 업무 규칙을 구체화.
- 엔티티 객체는 핵심 업무 데이터를 포함하거나 핵심 업무 데이터에 쉽게 접근 가능.
- 핵심 업무 데이터와 핵심 업무 규칙을 하나로 묶어서 별도의 소프트웨어 모듈로 만들어야 한다.
유스케이스
- 자동화된 시스템이 사용되는 방법을 설명.
- 애플리케이션에 특화된 업무 규칙을 설명.
- 엔티티 내부의 핵심 업무 규칙을 어떻게, 그리고 언제 호출할지를 명시하는 규칙을 담는다.
- 유스케이스는 사용자 인터페이스를 기술하지 않기 때문에 유스케이스만 봐서 이 애플리케이션의 세부사항을 알기는 힘들다.
- 시스템에서 데이터가 들어오고 나가는 방식은 유스케이스와 무관.
- 엔티티는 자신을 제어하는 유스케이스에 대해 아무것도 알지 못한다.
- 유스케이스는 단일 애플리케이션에 특화되어 있으며, 시스템의 입력과 출력에 가깝게 위치.
요청 및 응답 모델
- 유스케이스는 단순한 요청 데이터 구조를 입력으로 받아들이고, 단순한 응답 데이터 구조를 출력으로 반환하며 데이터 구조는 어떤 것에도 의존하지 않는다.
- 의존성을 분리하지 않을 경우 코드에 수많은 떠돌이 데이터가 만들어지고, 조건문이 추가될 가능성이 있다.
결론
- 업무 규칙은 핵심적은 기능.
- 업무 규칙은 수익을 내고 비용을 줄이는 코드를 수반.
- 업무 규칙은 사용자 인터페이스나 데이터베이스와 같은 저수준의 관심사로 오염되어서는 안된다.
- 업무 규칙을 표현하는 코드는 반드시 시스템의 심장부에 위치해야 하고, 시스템에서 가장 독립적이며 가장 많이 재사용할 수 있는 코드.
소리치는 아키텍처
아키텍처의 테마
- 건설 도면이 해당 건축물의 유스케이스에 대해 소리치는 것 처럼, 소프트웨어 애플리케이션의 아키텍처도 애플리케이션의 유스케이스에 대해 소리쳐야 한다.
- 프레임워크는 도구일 뿐, 아키텍처가 준수해야 할 대상이 아니다.
- 아키텍처를 프레임워크 중심으로 만들어버리면 유스케이스 중심이 되는 아키텍처는 나올 수 없다.
아키텍처의 목적
- 좋은 아키텍처는 유스케이스를 중심에 두기 떄문에, 프레임워크나 도구, 환경에 구애받지 않고 유스케이스를 지원하는 구조를 기술 할 수 있다.
- 좋은 아키텍처는 지엽적인 관심사에 대한 결합은 분리시킨다.
하지만 웹은?
애플리케이션이 웹으로 전달할지 앱으로 전달할지도 나중에 선택할 문제이며 미루어야할 결정사항 중 하나.
프레임워크는 도구일 뿐, 삶의 방식은 아니다
- 프레임워크는 강력하고 유용할 수 있으나, 프레밍워크가 모든 것을 하게해서는 안된다.
- 프레임워크가 아키텍처의 중심을 차지하는 일을 막을 수 있는 전략을 개발해야 한다.
테스트하기 쉬운 아키텍처
- 유스케이스를 최우선으로 하고, 프레임워크와 적당한 거리를 둔다면 유스케이스 전부에 대해 단위 테스트를 할 수 있어야 한다.
- 테스트는 웹 서버, 데이터베이스의 유무와 상관 없이 진해잉 가능해야 한다.
- 엔티티는 반드시 오래된 방식의 간단한 객체여야 한다.
- 유스케이스 객체가 엔티티 객체를 조작해야 한다.
- 프레임워크로 인한 어려움을 겪지 않고도 반드시 테스트를 진행할 수 있으야 한다.
결론
- 아키텍처는 시스템을 이야기해야 하며, 시스템에 적용한 프레임워크에 대해 이야기해서는 안 된다.
- 새로 합류한 프로그래머도 시스템이 어떻게 전달될지 알지 못한 상태에서도 시스템의 모든 유스케이스를 이해할 수 있어야 한다.
클린 아키텍처
- 육각형 아키텍처, DCI, BCE 모두 세부적인 면에서 차이가 있더라도, 관심사 분리를 하려는 본질은 같다.
- 해당 아키텍처는 시스템이 다음과 같은 특징을 지니도록 한다.
- 프레임워크의 독립성 : 시스템은 프레임워크에 의존하지 않으며, 프레임워크가 지닌 제약사항 안으로 시스템을 욱여 넣도록 강제하지 않는다.
- 테스트 용이성 : 업무 규칙은 UI, 데이터베이스, 웹 서버 등 여타 외부 요소가 없이도 테스트할 수 있다.
- UI 독립성 : 시스템의 나머지 부분을 변경하지 않고도 UI를 쉽게 변경할 수 있다.
- 데이터베이스 독립성 : 업무 규칙은 데이터베이스에 결합도지 않는다.
- 모든 외부 에이전시에 대한 독립성 : 업무 규칙은 외부 세계와의 인터페이스에 대해 전혀 알지 못한다.
의존성 규칙
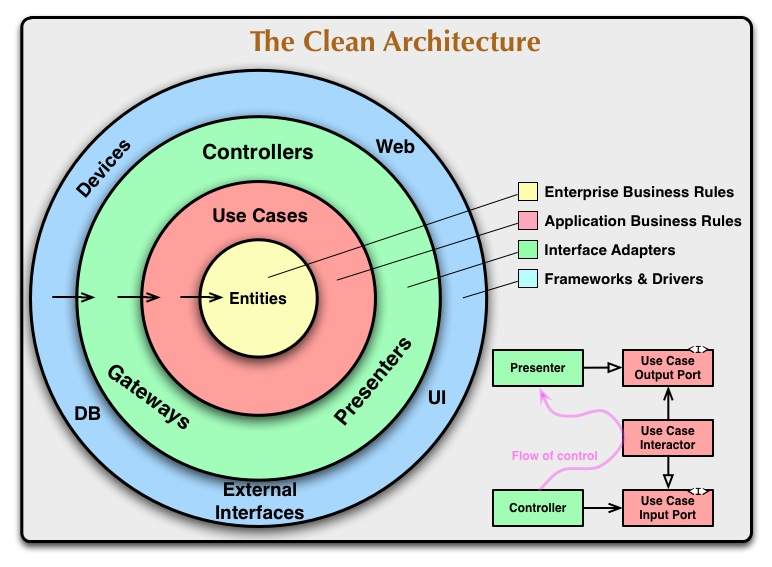
- 원 안으로 들어갈수록 고수준의 소프트웨어.
- 원 밖은 메커니즘, 안은 정책.
- 소스 코드의 의존성은 반드시 안쪽으로, 고수준의 정책을 향해야 한다.
- 원 내부에서는 원 밖의 그 어떤것도 언급해서는 안됨.
엔티티
- 핵심 업무 규칙을 캡슐화.
- 메서드를 가지는 객체이거나 일련의 데이터 구조와 함수의 집합일 수 도 있다.
- 엔티티는 재사용이 가능한 자원이여야 한다.
- 외부에서의 변경이 엔티티 계층에 영향을 줘서는 안된다.
유스케이스
- 애플리케이션에 특화된 업무 규칙을 포함.
- 엔티티로 들어오고 나가는 데이터 흐름을 조정하며, 엔티티가 자신의 핵심 업무 규칙을 사용해서 유스케이스의 목적을 달성하도록 이끈다.
- 애플리케이션이 변경이 되면 유스케이스에 영향을 줄 수 있다.
인터페이스 어댑터
- 유스케이스와 엔티티에게 가장 편리한 형식에서 데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식으로 변환.
- 프레젠터, 뷰, 컨트롤러는 모두 이 계층에 속한다.
프레임 워크와 드라이버
- 데이터베이스나 웹 프레임워크 같은 도구들로 구성.
- 원 안쪽과 토신하기 위한 코드 외에는 더 작성할 코드가 많지 않다.
- 세부사항이 위치하는 곳.
필요에 따라서 원이 더 있을 수 있으나, 바깥쪽 원으로 갈 수록 저서준의 구체적인 세부사항이 담겨야 되고, 안쪽으로 갈 수록 추상화되고 더 높은 수준의 정책들을 캡슐화 해야한다는 것은 동일.
결론
- 소프트웨어를 계층으로 분리하고 의존성 규칙을 준수한다면 테스트하기 쉬운 시스템을 만들 수 있다.
- 시스템 외부 요소가 구식이 되어 교체가 필요할때에도 쉽게 교체를 할 수 있다.
프레젠터와 험블 객체
험블 객체 패턴
- 행위들을 두 개의 모듈 또는 클래스로 나누는 디자인 패턴
- 험블 객체에는 테스트 하기 어려운 행위를 험블 객체에 옮긴다.
- 나머지 모듈에는 험블 객체에 속하지 않은, 테스트하기 쉬운 행위를 옮긴다.
프레젠터와 뷰
뷰
- 험블 객체이고 테스트하기 어렵다.
- 이 객체에 포함된 코드는 간단하게 유지.
- 데이터를 이동은 하지만 데이터를 직접 처리하지는 않는다.
프레젠터
- 테스트하기 쉬운 객체.
- 애플리케이션으로부터 데이터를 받아 화면에 표현할 수 있는 포맷으로 만드는 역할.
테스트와 아키텍처
험블 객체 패턴은 테스트가 용이하기 때문에 아키텍처에 경계가 생기는 좋은 패턴.
데이터베이스 게이트웨이
- 유스케이스 인터랙터와 데이터베이스 사이에 위치.
- 데이터베이스에서 수행되는 CRUD 관련 메서드를 포함.
- 유스케이스는 SQL을 허용하지 않기 떄문에 필요한 매서드를 제공하는 게이트웨이 인터페이스를 호출하고 그 인터페이스의 구현체는 데이터베이스 계층에 위치(이때 구현체는 험블객체).
데이터 매퍼
- 객체는 사용자의 입장에서 public 매서드만 볼 수 있기 떄문에 단순 오퍼레이션의 집합.
- 데이터 구조는 함축된 행위를 가지지 않는 public 데이터 변수의 집합이며 관계형 데이터베이스 테이블로부터 가져온 데이터를 데이터 구조에 맞게 담아준다.
- ORM 시스템은 데이터베이스 계층에 위치하며, 게이트웨이 인터페이스와 데이터베이스 사이에서 일종의 또 다른 험블 객체 경계를 형성
서비스 리스너
외부로 데이터를 전송하는 경우
애플리케이션은 데이터를 간단한 데이터 구조 형태로 로드한 후, 이 데이터 구조를 경계를 가로질러서 특정 모듈로 전달 -> 데이터를 적절한 포맷으로 만들어서 외부 서비스로 전송.
외부로부터 데이터를 수신하는 경우
서비스 리스너가 서비스 인터페이스로부터 데이터 수신하고 데이터를 애플리케이션에서 사용할 수 있게 간단한 데이터 구조로 포맷을 변경 -> 서비스 경계를 가로질러서 내부로 전달.
결론
- 각 아키텍처 경계마다 경계 가까이 숨어 있는 험블 객체 패턴이 있다.
- 경계를 넘나드는 통신은 데이터 구조를 수반하는 경우가 많고, 테스트가 쉬운것과 테스트가 쉽지 않은 케이스가 모두 존재.
- 아키텍처 경계에서 험블 객체 패턴을 사용하면 전체 시스템의 테스트 용이성을 크게 높일 수 있다.
부분적 경계
- 아키텍처 경계를 완벽하게 만드는 데는 비용이 많이 든다.
- 아직 필요한지 확신이 들지 않을때 부분적 경계를 사용해 보는 것도 좋다.
아래 3가지 방법으로 부분적 경계 구현 가능
- 마지막 단계를 건너뛰기
- 부분적 경계는 독립적으로 컴파일하고 배포할 수 있는 컴포넌트를 만들기 위한 작업을 모두 수행한 후, 단일 컴포넌트에 그대로 모아만 두면 된다.
- 다수의 컴포넌트를 관리하는 작업은 하지 않아도 된다.
- 일차원적인 경계
전략패턴을 통해서 미래에 필요할 아키텍처 경계를 위한 공간을 둔다
- 단점) 준비해돠도 근면성실/제대로 훈련 되있지 않으면 비밀 통로가 뚫린다.
퍼사드
단점) 의존성 역전 희생, 비밀 통로 발생 가능성 높음
결론
- 각각의 접근법은 나름의 장점, 비용을 가짐.
- 각각 접근법은 실제 구체화 되지 않으면 경계로써 가치가 없음.
- 완벽하게 경계를 나눌지, 대강 나눠놓기만 할지 정하는 것도 아키텍트 역량이다.
계층과 경계
단순한 게임을 만들때도 시스템 컴포넌트는 생각보다 많고, 이 컴포넌트 사이에서 의존성 규칙이 준수 될 수 있도록 제대로 된 설계를 할 필요가 있다.
클린 아키텍처
다양한 요구사항을 통해 몰랐던 변경의 축이 생길 수 있고 변경의 축에 의해 정의되는 아키텍처 경계가 잠재되어 있다.
흐름 횡단하기
시스템이 복잡해질수록 컴포넌트 구조는 더 많은 흐름으로 분리가 된다.
흐름 분리하기
- 결국 모든 흐름이 상단의 단일 컴포넌트에서 서로 만난다고 생각 할 수 있는데 현실은 그렇지 않고 흐름에 따라서 적절한 분리를 잘해야 한다.
결론
- 아키텍처의 경계가 어디에나 존재할 수 있고, 아키텍트는 경계가 언제 필요한지를 신중하게 파악해내야 한다.
- 경계를 설정하는 것고 추후에 추과하는 것에는 비용이 많이 든다.
- 아키텍트는 미래를 예층해 어디에 경계를 뒤야 할지, 완벽하게 구현할 경계와 부분적으로 구분할 경계는 무엇인지 결정해야 한다.
메인 컴포넌트
나머지 컴포넌트를 생성,조정, 관리한는 컴포넌트를 메인 컴포넌트라 한다.
궁극적인 세부사항
- 메인 컴포넌트는 궁극적인 세부사항, 가장 낮은 수준의 정책이다.
- DI는 이 메인 컴포넌트에서 이뤄져야 한다.
- 가장 바깥원에 위치하는 지저분한 저수준 모듈
- 고수준 시스템이 필요로 하는 모든것을 로드한 뒤 제어권을 고수준 시스템에 넘김
결론
메인 컴포넌트는 애플리케이션의 플러그인이다.
크고 작은 모든 서비스들
서비스 아키텍처
서비스를 사용하는 것을 아키텍처라 볼 수는 없다.
-
아키텍처 : 의존성 규칙을 준수하고 고수준 정책을 저수준의 세부사항으로 분리하는 경계에 의해 정의된다.
-
서비스 : 단순히 앱 행위(도메인)을 분리한 거는 그냥 값비싼 함수 호출에 불과하다.
-
중요한 요소는 경계를 넘나드는 함수 호출 들이다.
-
서비스도 동일하게 플랫폼 경계를 가로지르는 함수 호출 에 대해서 관심을 가져야 한다.
서비스의 이점?
셜합 분리의 오류
- 시스템을 서비스들로 분리하면서 서비스 사이의 결합이 확실히 분리 될것이라 생각하지만, 프로세서 내 또는 네트워크 상 공유 자원 떄문에 결합될 가능성이 존재.
- 데이터 레코드에 새로운 필드를 추가할때 레코드를 그대로 사용하고 있다면 관련된 서비스들을 전부 수정해야 한다.
- 인터페이스가 잘 정의되어 있으면 되나, 이게 완벽히 될 것이라고 생각하는 것이 비현실적
개발 및 배포 독립성의 오륲
전담팀이 서비스를 소유하고 운영하니까 독립적인 개발/배포 가능할 것이라 생각하지만 현실은 다르다.
1. 모노리틱이나 컴포넌트 기반으로도 할 수 있음(msa가 유일한 선택지 아님)
2. 데이터나 행위에 대해서 결합되 있다면 개발/배포/운영을 조정해야함
야옹이 문제
어떤 서비스가 결합이 되어 독립적이지 않을때, 새로운 서비스를 추가하려 하면 전부를 바꿔야 하는데 이를 횡단 관심사가 지닌 문제라고 한다.
객체가 구출하다
컴포넌트 기반 아키텍처에서는 이 문제를 다형적으로 확장할 수 있는 클래스 집합을 생성해서 신규피처를 처리하도록 함.
컴포넌트 기반 서비스
- 서비스도 SOLID 원칙대로 설계할 수 있으며 컴포넌트 구조를 갖출 수도 있다.
- 이를 통해 서비스 내의 기존 컴포넌트들을 변경하지 않고도 새로운 컴포넌트를 추가할 수 있다.
- 새로 추가되는 시능은 개방 폐쇄 원칙을 준수하게 된다.
횡단 관심사
- 아키텍처 경계는 서비스 사이에 있지 않다.
- 서비스들을 관통하기 때문에 서비스를 컴포넌트 단위로 분할해야 한다.
결론
서비스는 유용한 측면도 있지만 그 자체적으로 아키텍처의 중요한 요소는 아니다.
테스트 경계
테스트도 시스템의 일부이며 아키텍처에도 관여한다.
시스템 컴포넌트인 테스트
- 테스트는 태생적으로 의존성 규칙을 따르며 가장 바깥쪽 원이다.
- 원 안쪽에 있는 컴포넌트 그 어떤것도 테스트에 의존하지 않으며 테스트는 항상 원 안쪽으로 의존.
- 테스트는 독립적으로 배포가 가능해야 하며, 컴포넌트 중 가장 고립되어 있다.
테스트를 고려한 설계
- 테스트도 시스템의 일부라고 생각해야 한다.
- 시스템에 강하게 결합된 테스트는 "깨지기 쉬운 테스트"이다.
- 깨지지 않는 테스트를 위해서는 테스트를 고려하여 설계해야 한다.
테스트 API
- 테스트에 특화된 API 만들면 좋다.
- 테스트 구조를 앱 구조로부터 결합을 분리하는게 목표이다.
구조적 결합
- 테스트 결합 중에서 가장 강하며, 가장 은밀하게 퍼져 나가는 유형.
- 상용 클래스나 메서드 중 하나라도 변경되면 테스트도 변경되어야 함 -> 테스트가 꺠지기 쉬워지기 떄문에 상용 코드가 뻣뻣해진다.
- 이때 테스트 API를 통해 앱 구조를 테스트로 부터 숨김 -> 앱 구조 리팩토링해도 테스트 는 안바꿔되고 테스트를 리팩터링 해도 상용 코드에는 영향을 주지 않는다.
보안
- 테스트 API가 지닌 강력한 힘을 운영 시스템에 배포하면 위험에 처할 수 있다.
- 테스트 API 자체와 테스트 API 중 위험한 부분의 구현부는 독맂벅으로 배포할 수 있는 컴포넌트로 분리해야 한다.
결론
테스트도 아키텍처에 포함되니 잘 설계 해야한다.
클린 임베디드 아키텍처
소프트웨어는 닳지 않지만, 펌웨어와 하드웨어는 낡아 가므로 결국 소프트웨어도 수정해야 한다.
소프트웨어는 닳지 않지만, 펌웨어와 하드웨어에 대한 의존성을 관리하지 않으면 안으로부터 파괴될 수 있다.- 하드웨어는 계속적으로 발전하고 이를 염두에 두고 임베디드 코드를 구조화 할 수 있어야 한다.
- 하드웨어나 기술에 의존한 코드가 곧 펌웨어이고, 아키텍트는 펌웨어를 수없이 양산하는 일을 멈추고, 코드에게 유효 수명을 길게 늘릴 수 있도록 해야 한다.
엡-티튜드 테스트
- 임베디드 소프트웨어가 펌웨어로 변하는 이유 : 코드가 오랫동안 유용하게 남도록 구조화하는데 신경 쓰지 않고 동작하는데 신경을 쓰기 때문
켄트백의 소프트웨어를 구축하는 세가지 활동
- 먼저 동작하게 만들어라
- 올바르게 만들어라(코드를 가독성 있고 변경에 유연하게 만들기)
- 빠르게 만들어라(최적화 및 성능 개선)
대부분의 임베디드 시스템 소프트웨어는 1 3번에만 집중.
- 앱이 동작하도록 만드는 것을 나는 개발자용 앱-티튜드 테스트.
- 앱-티튜드 테스트를 통과하는 것과 클린 임베디드 아키텍처를 갖는 것은 별개
타깃-하드웨어 병목현상
- 임베디드가 지닌 특수한 문제 중 하나는 타깃-하드웨어 병목현상
타깃-하드웨어 병목현상
임베디드 코드가 클린 아키텍처 원칙과 실천법을 따르지 않고 작성된다면, 코드를 테스트할 수 있는 환경이 특정 타깃으로 국한되어 진척이 느려지는 현상클린 임베디드 아키텍처는 테스트하기 쉬운 임베디드 아키텍처다
몇 가지 아키텍처 원칙을 임베디드 소프트웨어와 펌웨어에 적용하여 타깃-하드웨어 병목현상을 줄이는 방법
계층
- 계층 : 소프트웨어 / 펌웨어 / 하드웨어
- 하드웨어는 시스템의 나머지 부분으로부터 반드시 분리되어야 한다.
- 소프트웨어와 펌웨어가 서로 섞이는 일은 안티 패턴이다.
- 이 안티 패턴을 보이는 코든느 변화에 저항하게 된다.
- 변경하기 어려울 뿐 아니라 변경하는 일 자체가 위험을 수반하여, 때로는 의도치 않은 결과를 불러온다.
하드웨어는 세부사항이다.
- 소프트웨어와 펌웨어 사이의 경계는 하드웨어 추상화 계층(HAL)
- HAL은 자신보다 위에 있는 소프트웨어를 위해 존재하므로, HAL의 API는 소프트웨어의 필요에 맞게 만들어져야 한다.
HAL 사용자에게 하드웨어 세부사항을 드러내지 말라
- HAL을 제대로 만들었다면, HAL은 타깃에 상관없이 테스트할 수 있는 경계층 또는 일련의 대체 지점을 제공한다.
프로세서는 세부사항이다
- 모든 소프트웨어는 반드시 프로세서에 독립적이야 함이 분명하지만, 모든 펌웨어가 그럴 수는 없다.
- 클린 임베디드 아키텍처라면 이들 장치 접근 레지스터를 직접 사용하는 코드는 소수의 순전히 펌웨어로만 한정시켜야 한다.
- 펌웨어 역시 프로세서 추상화 계층(PAL)을 통해 저수준 함수들을 격리 시킬 수 있고, 타깃 하드웨어에 관계 없이 테스트할 수 있고, 덜 딱딱해질 수 있다.
운영체제는 세부사항이다
- 작성한 코드의 수명을 늘리려면, 무조건 운영체제를 세부사항으로 취급하고 운영체제에 의존하는 일을 막아야 한다.
- 소프트웨어는 운영체제를 통해 운영 환경이 제공하는 서비스에 접근
- OS는 소프트웨어를 펌웨어로부터 분리하는 계층
- 클린 임베디드 아키텍처는 운영체제 추상화 계층(OSAL)을 통해 소프트웨어를 운영체제로부터 격리
- 소프트웨어가 OS에 의존하지 않고 OSAL에 의존하게 된다면 OS를 교체하는 것도 용이
- OSAL은 타깃과는 별개로 테스트할 수 있도록 해주는 경계층 또는 일련의 대체 지점을 제공
인터페이스를 통하고 대체 가능성을 높이는 방향으로 프로그래밍하라

- 모든 계층에서 심사를 분리시키고, 인터페이스를 활용하며, 대체 가능성을 높이는 방향으로 프로그래밍하도록 유도
- 클린 임베디드 아키텍처에서는 모듁들이 인터페이스를 통해 상호작용하기 때문에 각각의 계층 내부에서 테스트가 가능.
- 각 인터페이스는 경계층을 제공
결론
- 모든 코드가 펌웨어가 되도록 내버려두면 제품이 오래 살아남을 수 없게 된다.
- 클린 임베디드 아키텍천느 제품이 장기간 생명력을 유지하는 데 도움을 준다.
