
데이터 전처리, 통계, 시각화 등을 위한 라이브러리
Table of Contents
- Series
- DataFrame
- concat, drop, merge
- Series 연산
- pivot
- 데이터 읽어오기
- 통계, 결측치 확인
판다스(pandas)
- 엑셀의 워크시트처럼 다양한 데이터 형식을 배열로 사용할 수 있음
- 1차원 자료구조인 series, 2차원 자료구조인 Dataframe, 3차원 자료구조인 Panel 지원
- 결측 데이터 처리, 데이터 추가와 삭제, 정렬과 조작 등..
- 파이썬 리스트, 딕셔너리, 넘파이 배열을 데이터 프레임으로 변환 가능
- 판다스로 csv,엑셀 파일 등을 열 수 있음
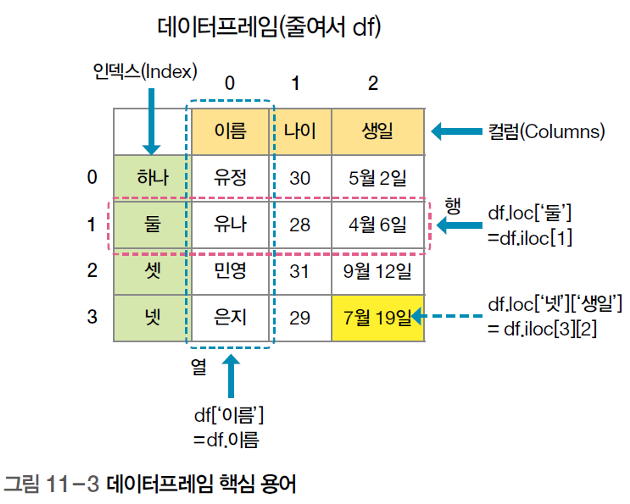
시리즈
- 행 또는 열 하나만 추출한 것
- 인덱스와 데이터로 이루어짐
import numpy as np
import pandas as pd
series = pd.Series([1,3,4,np.nan,6,8]) #np.nan은 nan과 동일, nan이 있을 경우 실수형
series
data1 = [10,20,30,40,50]
print(data1)
data2 = ['1반','2반','3반','4반','5반']
print(data2)sr1 = pd.Series(data1) #리스트를 이용하여 시리즈 생성
sr1sr2 = pd.Series(data2) #리스트를 이용하여 시리즈 생성
sr2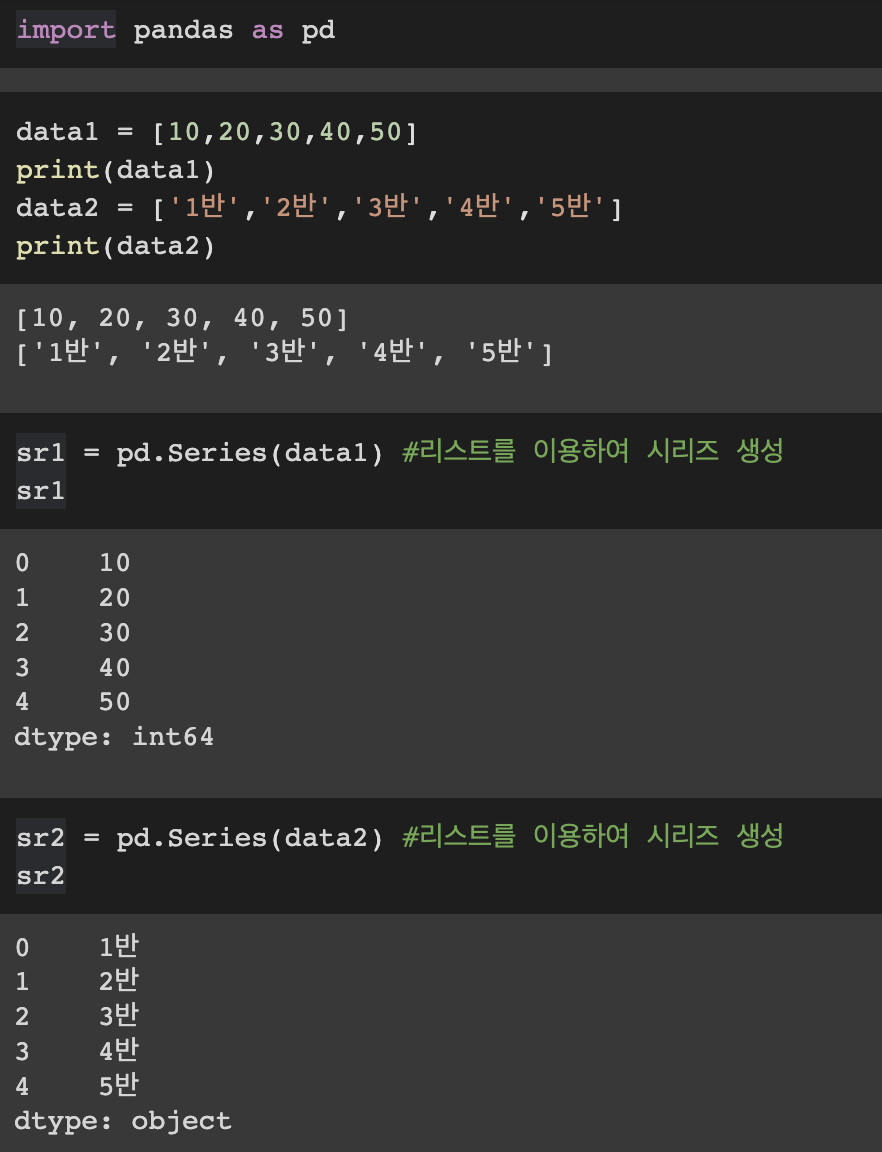
sr3 = pd.Series([101,102,103,104,105]) #리스트를 이용하여 시리즈 생성
sr3sr4 = pd.Series(['월','화','수','목','금']) #리스트를 이용하여 시리즈 생성
sr4sr5= pd.Series(data1, index = [1000,1001,1002,1003,1004]) #인덱스 이용하여 시리즈 생성
sr5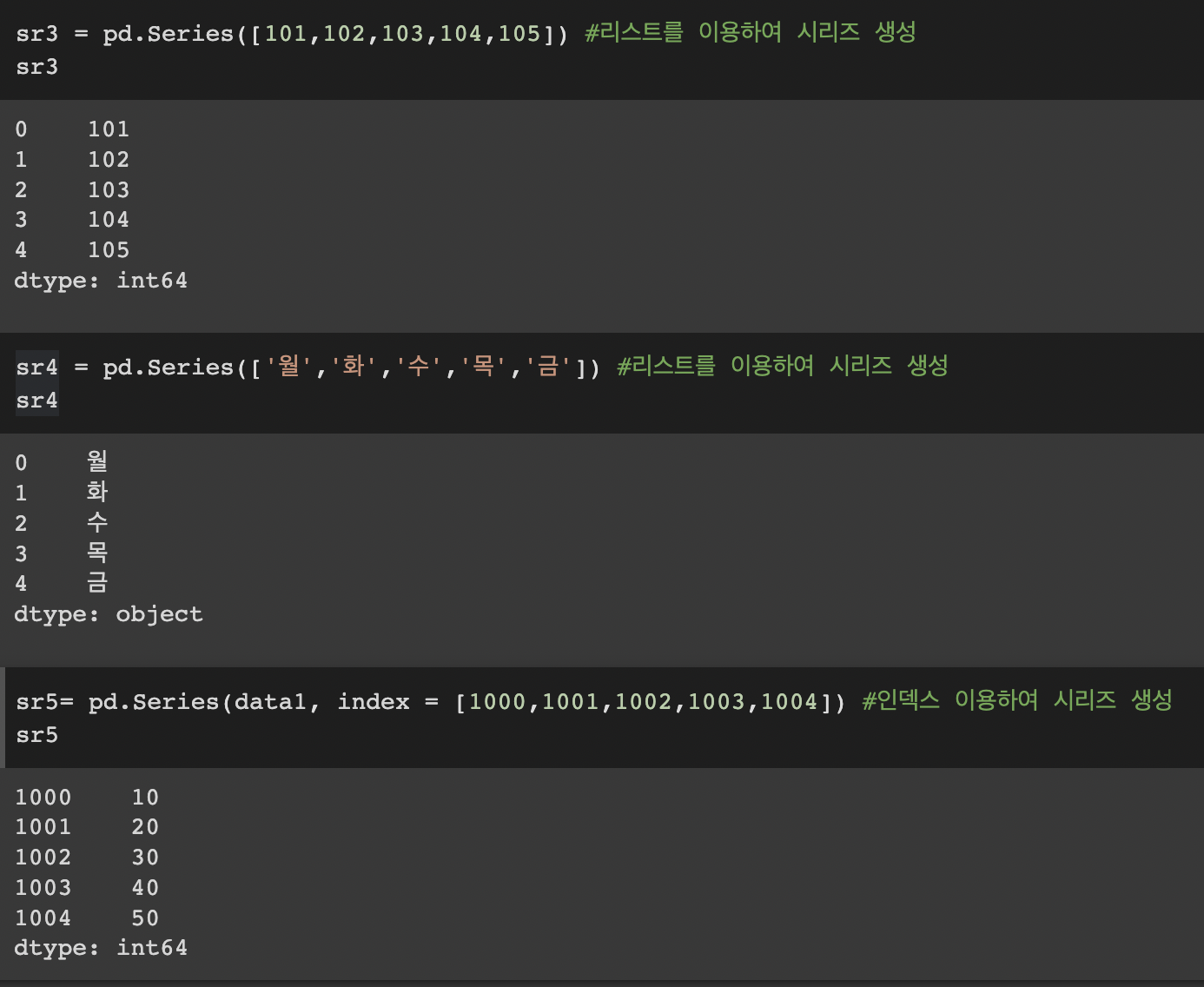
sr6= pd.Series(data1, index = data2) #인덱스 이용하여 시리즈 생성
sr6sr7 = pd.Series(data2, index = data1) #인덱스 이용하여 시리즈 생성
sr7sr8 = pd.Series(data2, index = data1) #인덱스 이용하여 시리즈 생성
sr8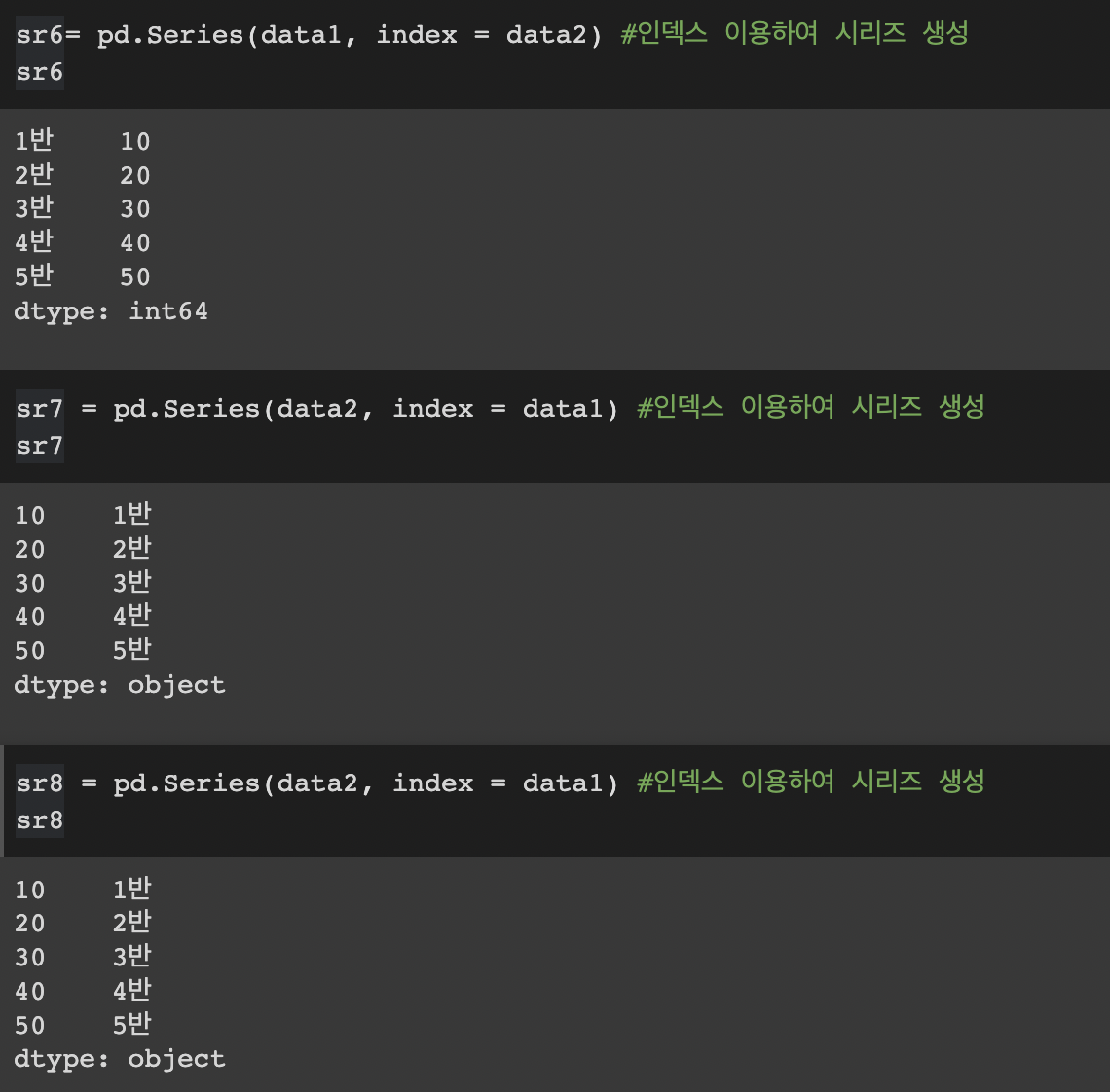
sr2[2] #시리즈 인덱싱sr8[0:4] #시리즈 슬라이싱sr8.index #인덱스 구하기sr8.values #시리즈 값 구하기sr1 + sr3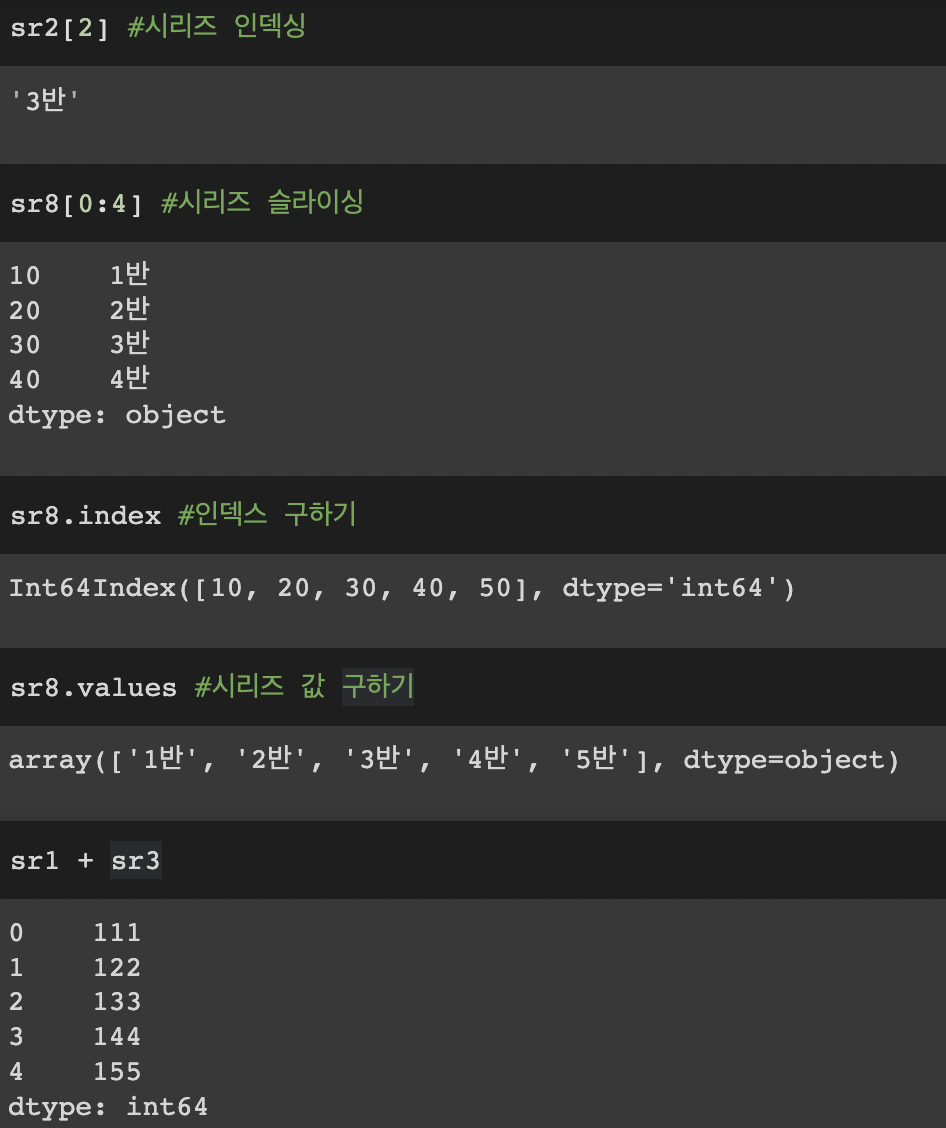
데이터프레임
data = {'name': ['kim','lee','son','jang'],
'hak' :['21','18','18','19'],
'score' : ['3.0','4.3','3.5','4.0']}
df1 = pd.DataFrame(data)
df1df2 = pd.DataFrame(data, index=['얼간이1','얼간이2','얼간이3','얼간이4'])
df2print(df2.index) #인덱스 확인
print(df2.columns) #컬럼 확인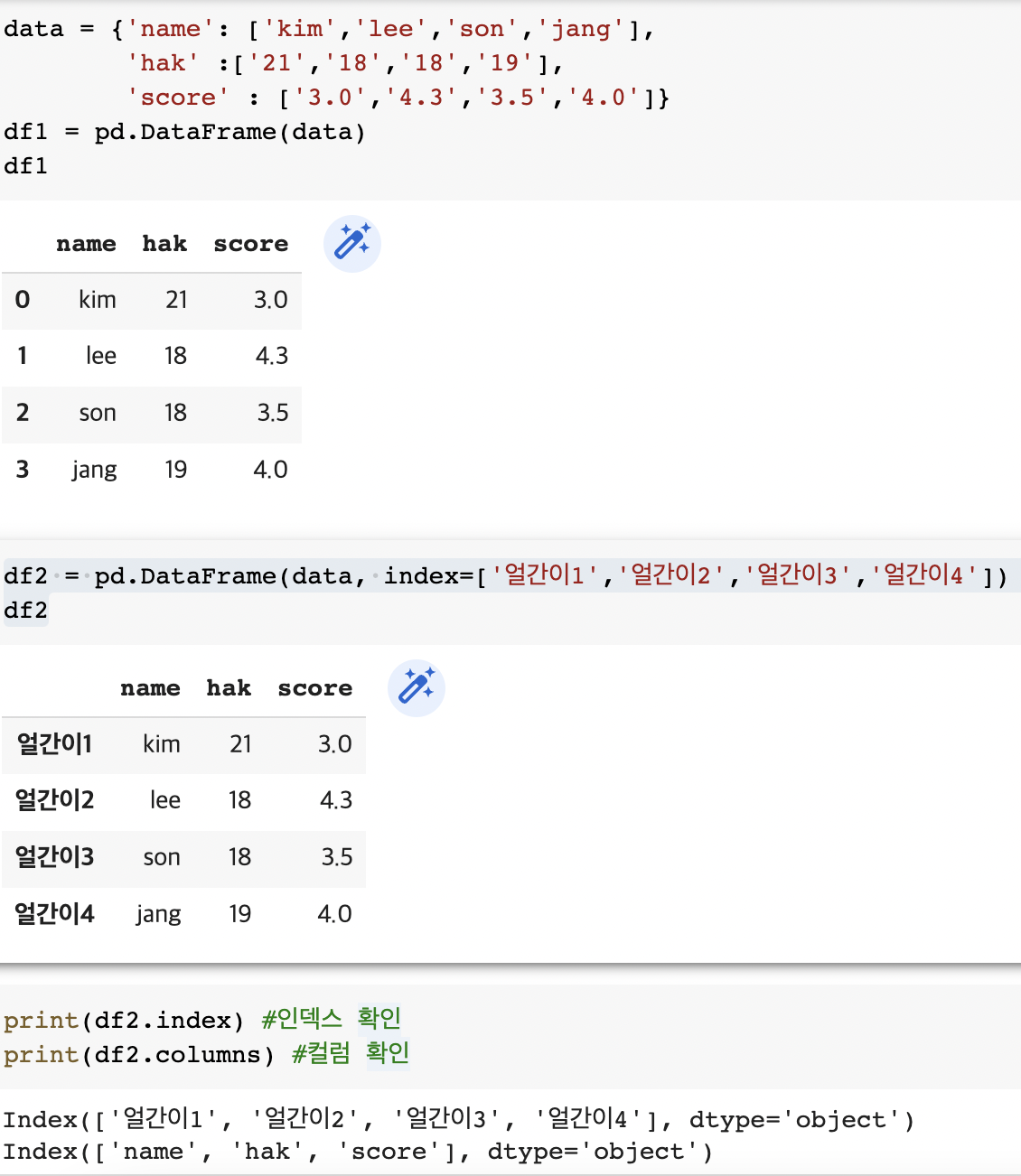
idiot_name = df2['name'] #열 추출
idiot_nameidiot_2 = df2.loc['얼간이2'] #행 추출
idiot_2print(df2.loc['얼간이2','score'])
print(df2.loc['얼간이2']['score'])
print(df2.iloc[1][2])
print(df2.iloc[1,2])
df2['age'] = [23,23,24,23] #열 추가
df2depart = pd.Series(['it','Engineering','Jap','it'], index = ['얼간이1','얼간이3','얼간이2','얼간이4'])
df2['depart'] = depart
df2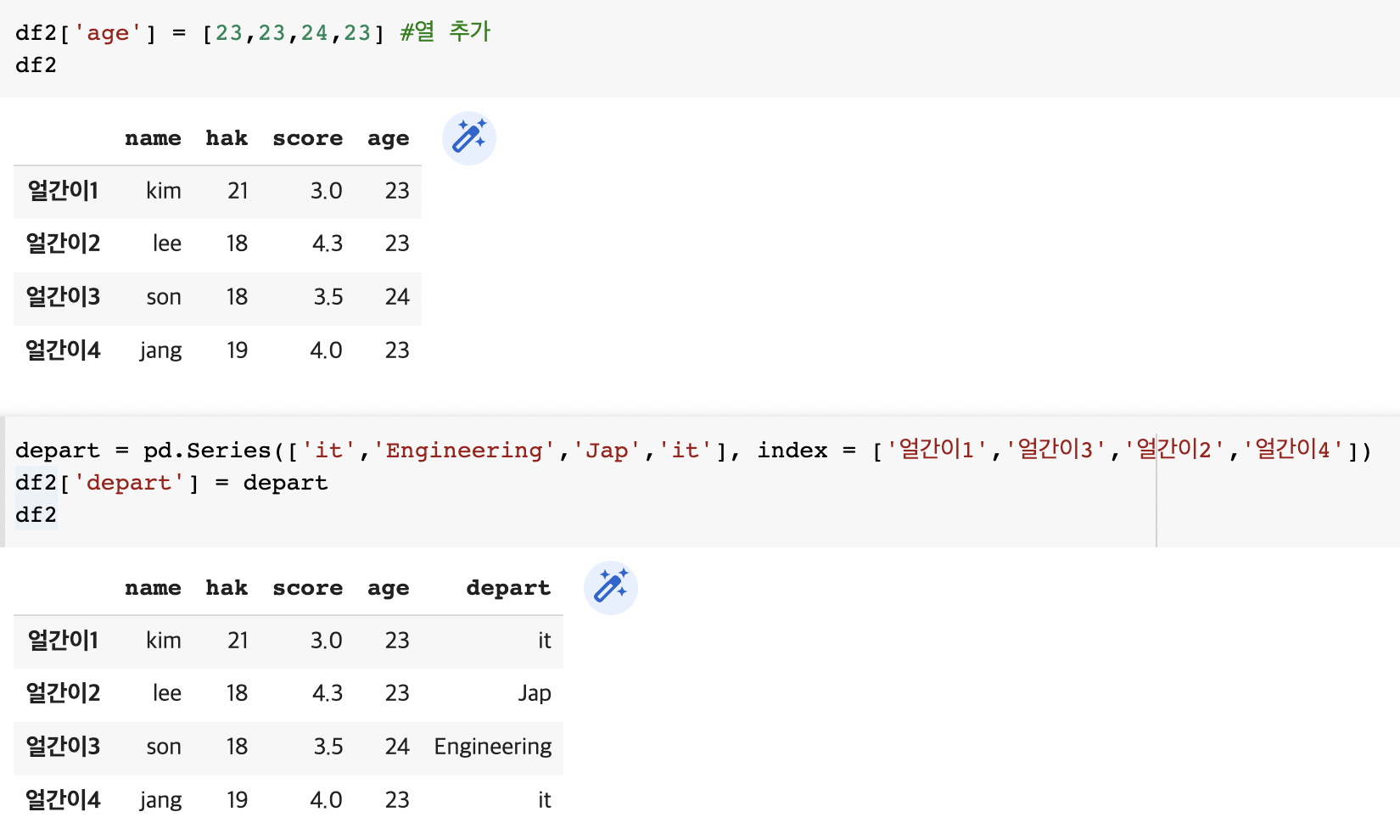
df2.loc['얼간이5'] = ['lee',19,2.5,23,'adult'] #행 추가
df2df2.loc['얼간이6'] = {'name' : 'lee', 'age' : '25'} #행 추가
df2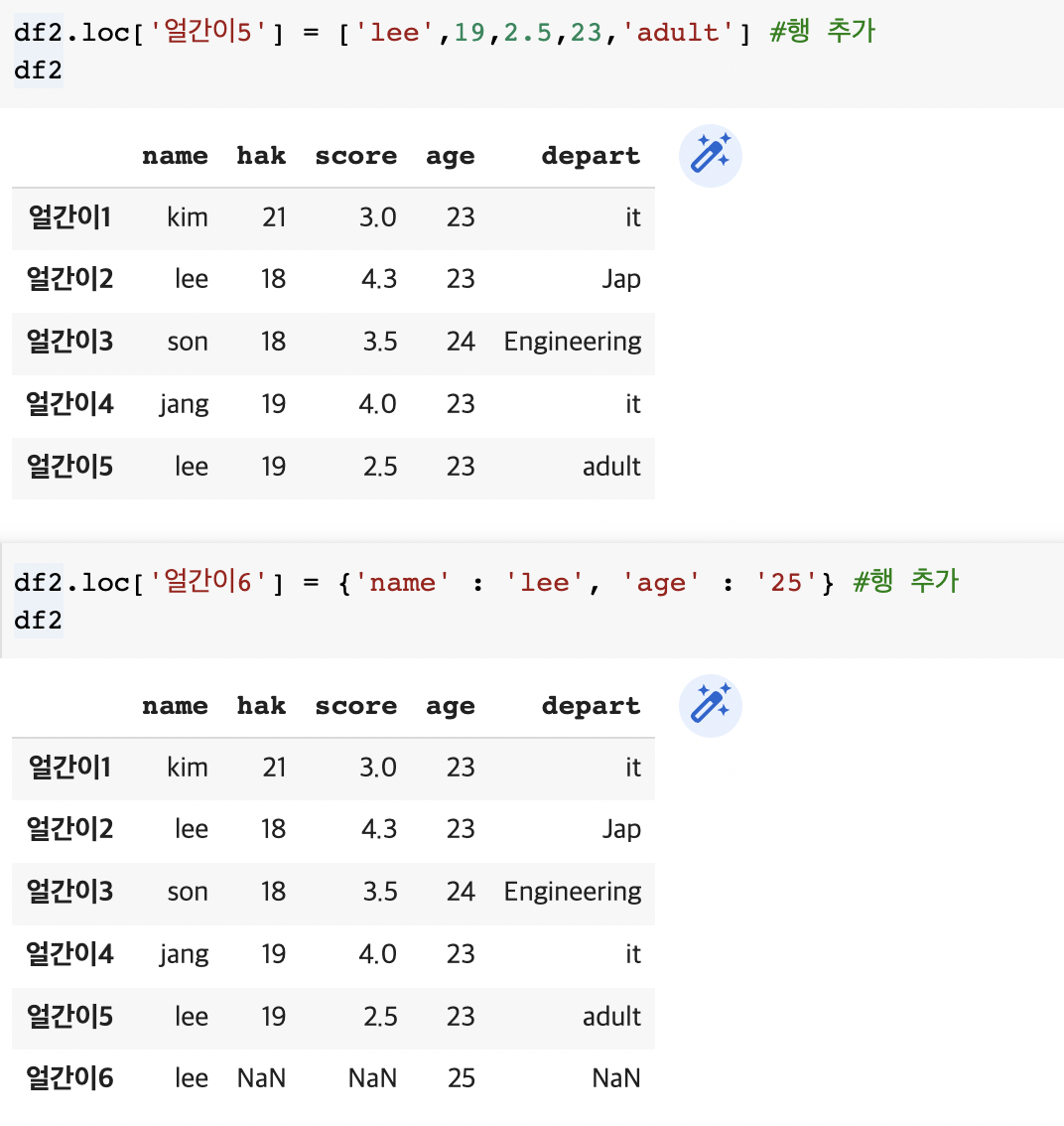
new_data = {'name' : ['lee','song'], 'sex' : ['man','man']}
new_df = pd.DataFrame(new_data, index = ['얼간이7','얼간이8'])
new_dfdf2 = pd.concat([df2,new_df])
df2
concat, drop, merge
df_1 = pd.DataFrame({'A' : ['a10','a11','a12'],
'B' : ['b10','b11','b12'],
'C' : ['c10','c11','c12']},
index = ['가','나','다'])
df_2 = pd.DataFrame({'B' : ['b23','b24','b25'],
'C' : ['c23','c24','c25'],
'D' : ['d23','d24','d25']},
index = ['다','라','마'])df2 = df2.drop(['얼간이8'], axis = 0) #행 삭제
df2df2 = df2.drop(['sex'],axis=1) #열 삭제
df2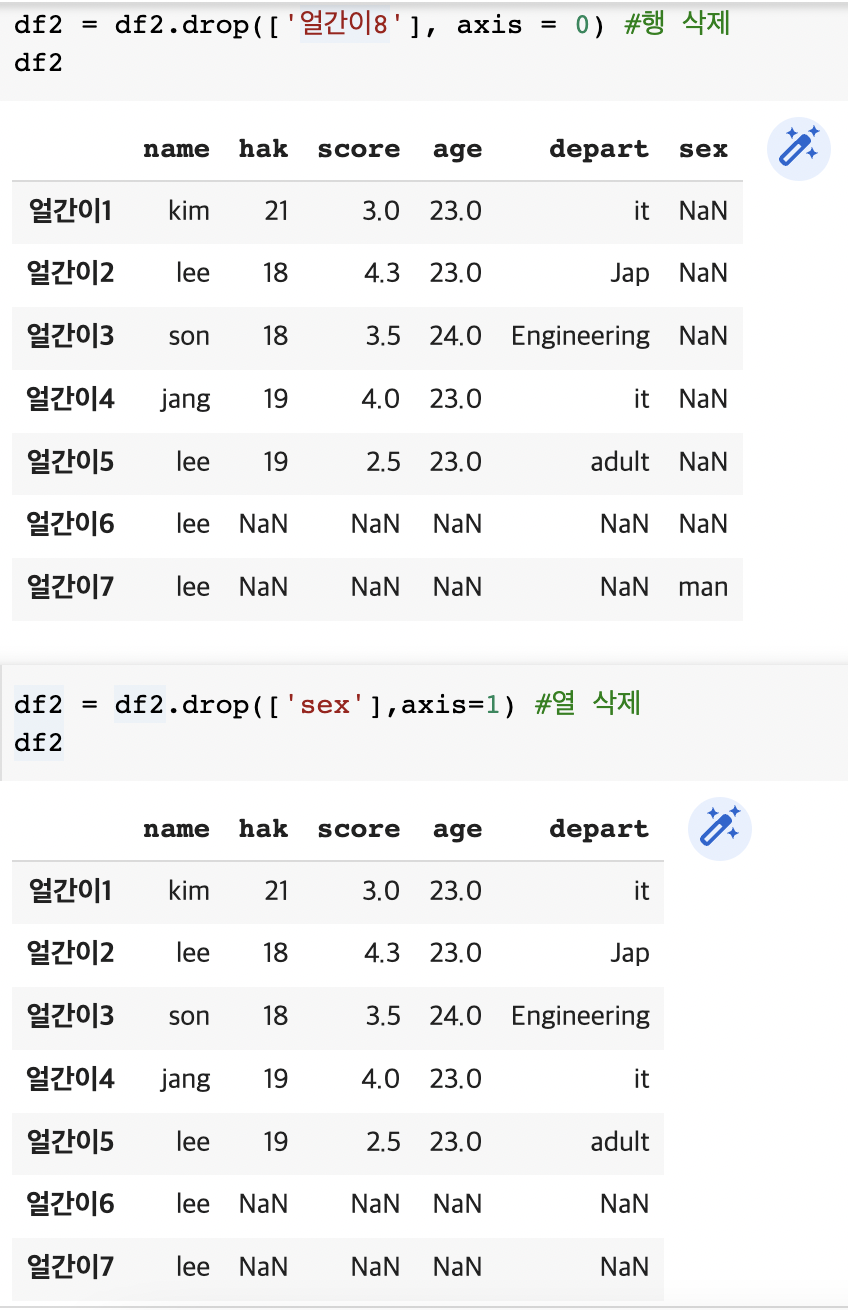
- 축이 1이면 테이블의 열을 늘리고, 축이 1이면 테이블의 열을 늘림
- join의 인자가 outer이면 합집합, inner면 교집합으로 생성
pd.concat([df_1,df_2], axis = 0, join = 'outer')
pd.concat([df_1,df_2], axis = 1, join = 'outer')
pd.concat([df_1,df_2], axis = 0, join = 'inner')
pd.concat([df_1,df_2], axis = 1, join = 'inner')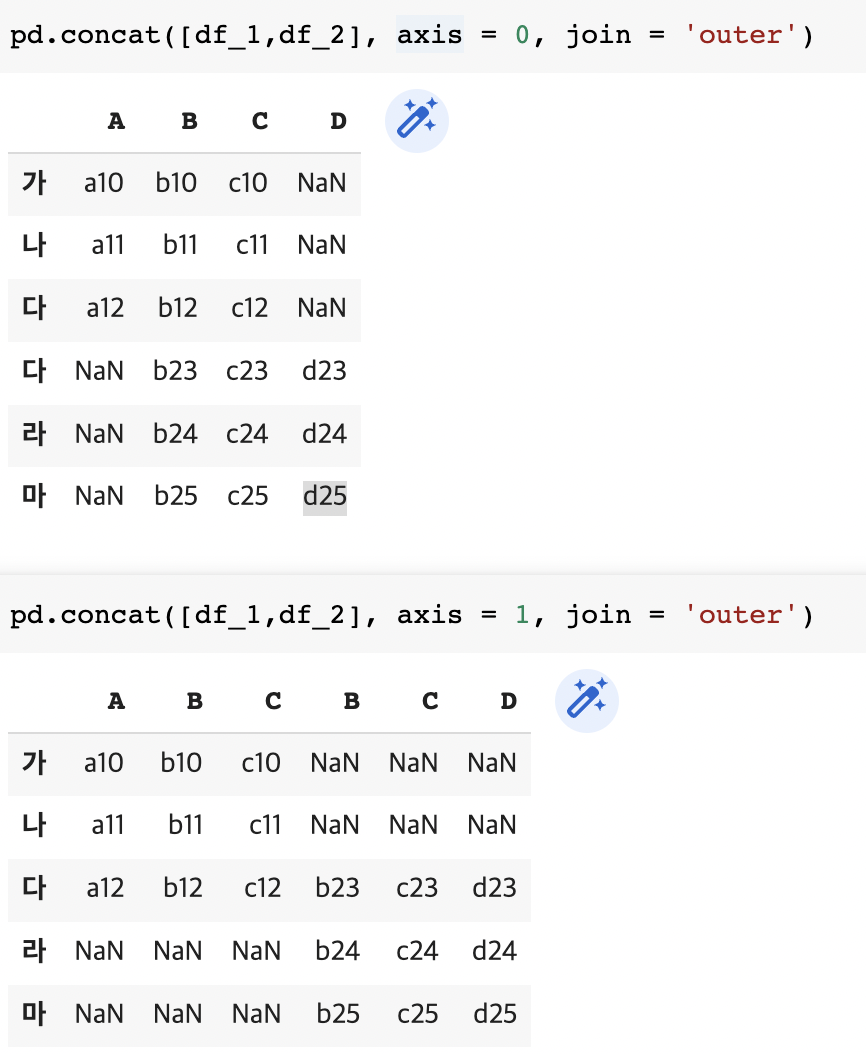

df_3 = df_1.merge(df_2, how = 'outer', on = 'B') #결합의 방식은 left,right,outer,inner
df_3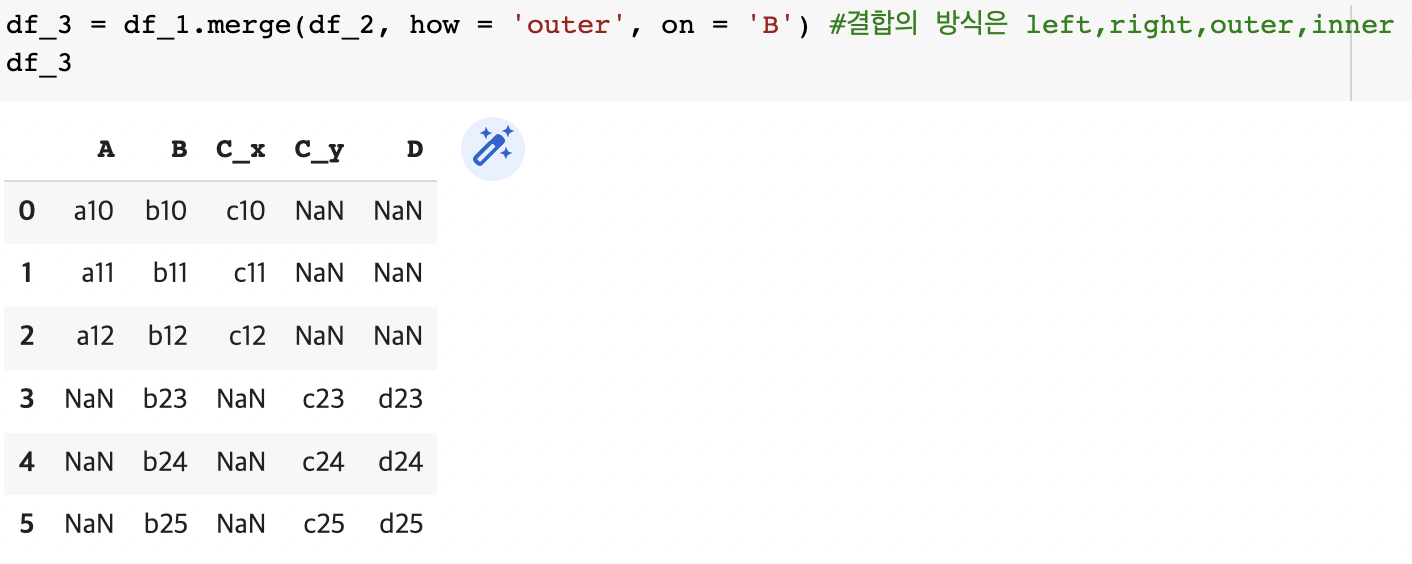
df_1.merge(df_2,how = 'outer',left_index= True, right_index = True)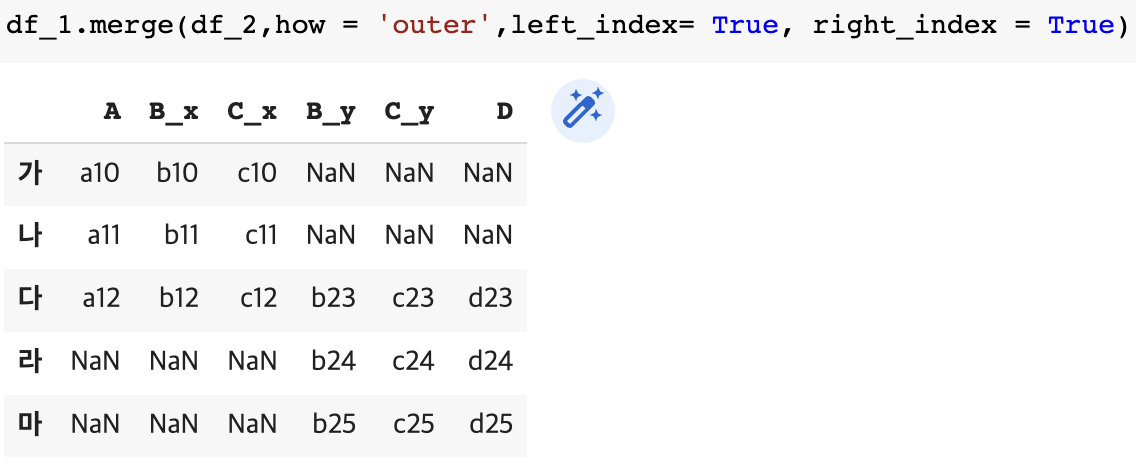
df_1.merge(df_2, how = 'left', on = 'B')
df_1.merge(df_2, how = 'right', on = 'B')
df_1.merge(df_2, how = 'outer', on = 'B')
df_1.merge(df_2, how = 'inner', on = 'B')
df2 = df2.drop(['age','depart'],axis = 1) #여러 열 삭제
df2 df2 = df2.drop(['얼간이6','얼간이7']) #여러 행 삭제
df2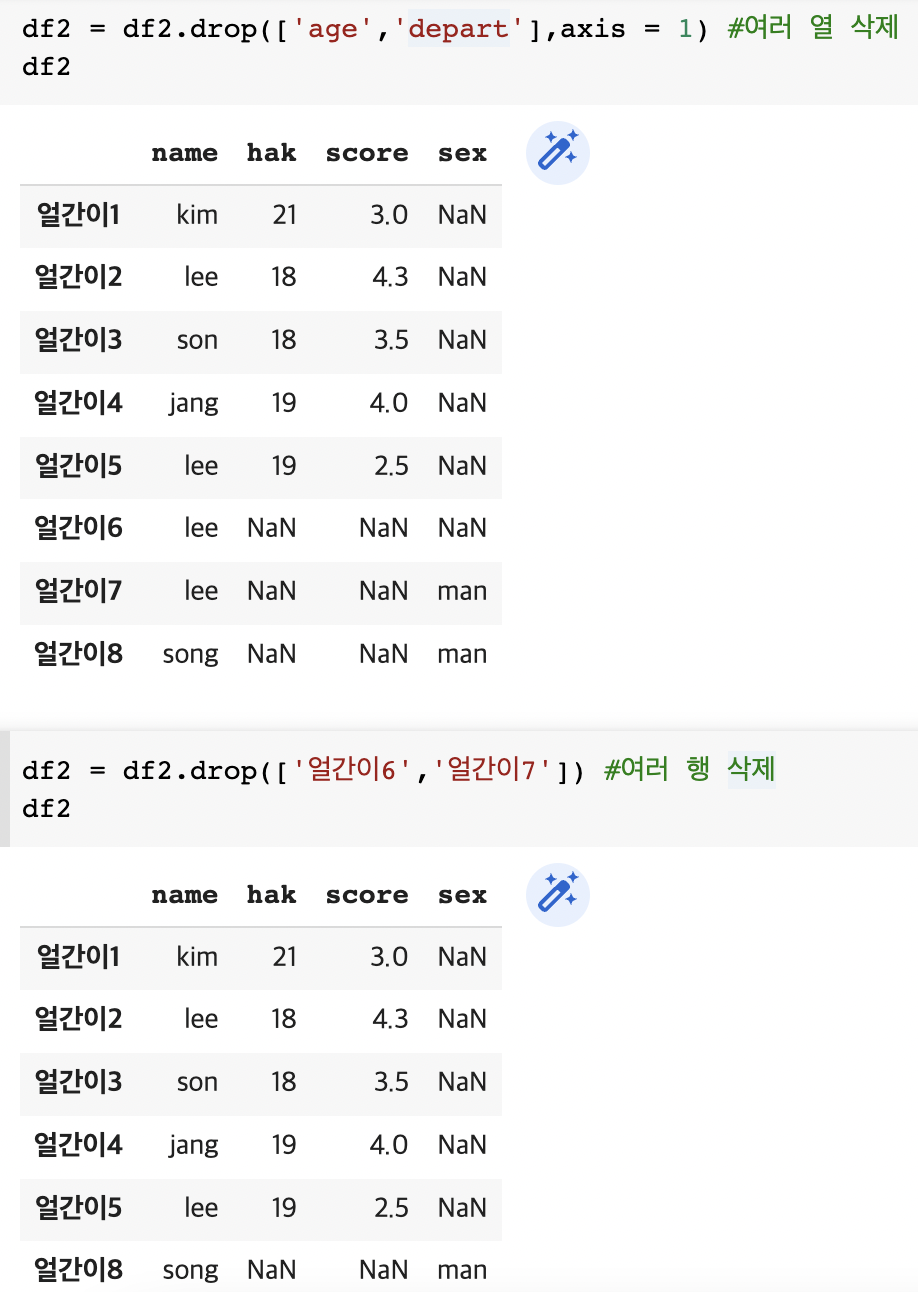
시리즈 연산
sr1 = pd.Series([21,18,18,19], index =['kim','lee','son','jang'])
sr2 = pd.Series([2,4,3.5,4], index =['kim','lee','son','jang'])
sr12 = sr1+sr2
sr12sr1 = pd.Series([21,18,18,19], index =['kim','lee','son','jang'])
sr2 = pd.Series([2,4,3.5,4], index =['kim','lee','son','song'])
sr12 = sr1+sr2
sr12
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
df데이터 구조를 변경하는 pivot
df.pivot(index='foo', columns='bar', values='baz')
df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])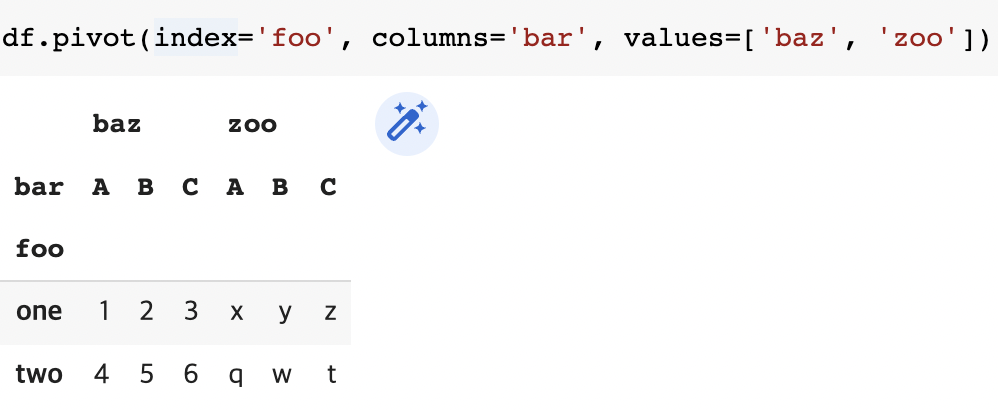
데이터 읽어오기
import csv
f = open('/content/test.csv')
data = csv.reader(f) #reader 함수를 이용하여 읽음
for row in data:
print(row)
f.close()import csv
f = open('/content/test.csv')
data = csv.reader(f) #reader 함수를 이용하여 읽음
header = next(data) #헤더 제거할 때 next()함수
for row in data:
print(row)
f.close()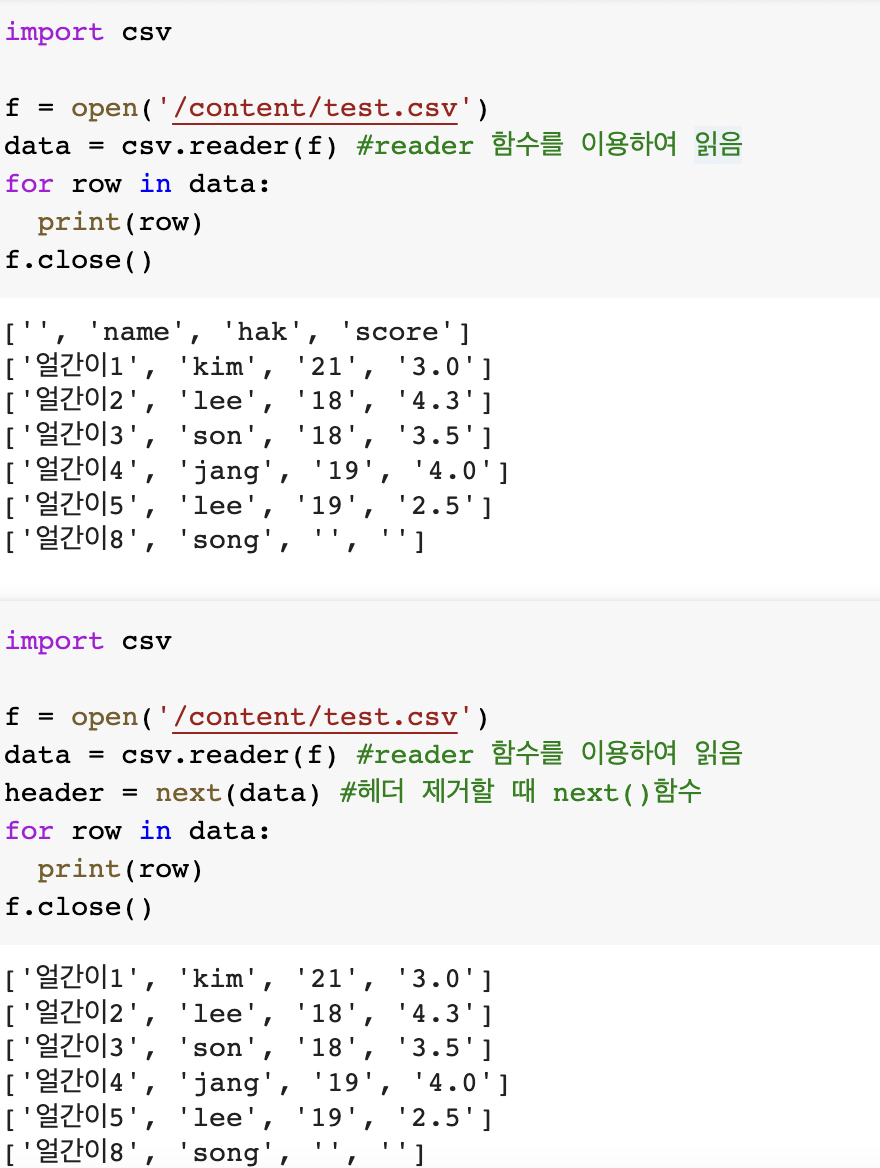
import csv
f = open('/content/weather.csv', encoding='UTF-8', errors='ignore')
data = csv.reader(f)
header = next(data)
for row in data:
print(row[3], end=',')
f.close()UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 0: invalid start byte 에러가 발생하여 코드에 encoding='UTF-8', errors='ignore' 추가
import csv
f = open('/content/weather.csv', encoding='UTF-8', errors='ignore')
data = csv.reader(f)
header = next(data)
max_wind = 0.0
for row in data:
if row[3] == '': #평균풍속 데이터가 없으면
wind = 0 #0으로 처리
else:
wind = float(row[3]) #평균풍속 데이터를 실수로 변환
if max_wind < wind : #최대 풍속을 갱신하는지 검사
max_wind = wind #현재까지 최대 풍속보다 크면 새로 기록
print('10년간 최대 풍속은 ',max_wind, 'm/s')
import pandas as pd
df = pd.read_csv('/content/countries.csv')
dfdf = pd.read_csv('/content/countries.csv',index_col=0)
df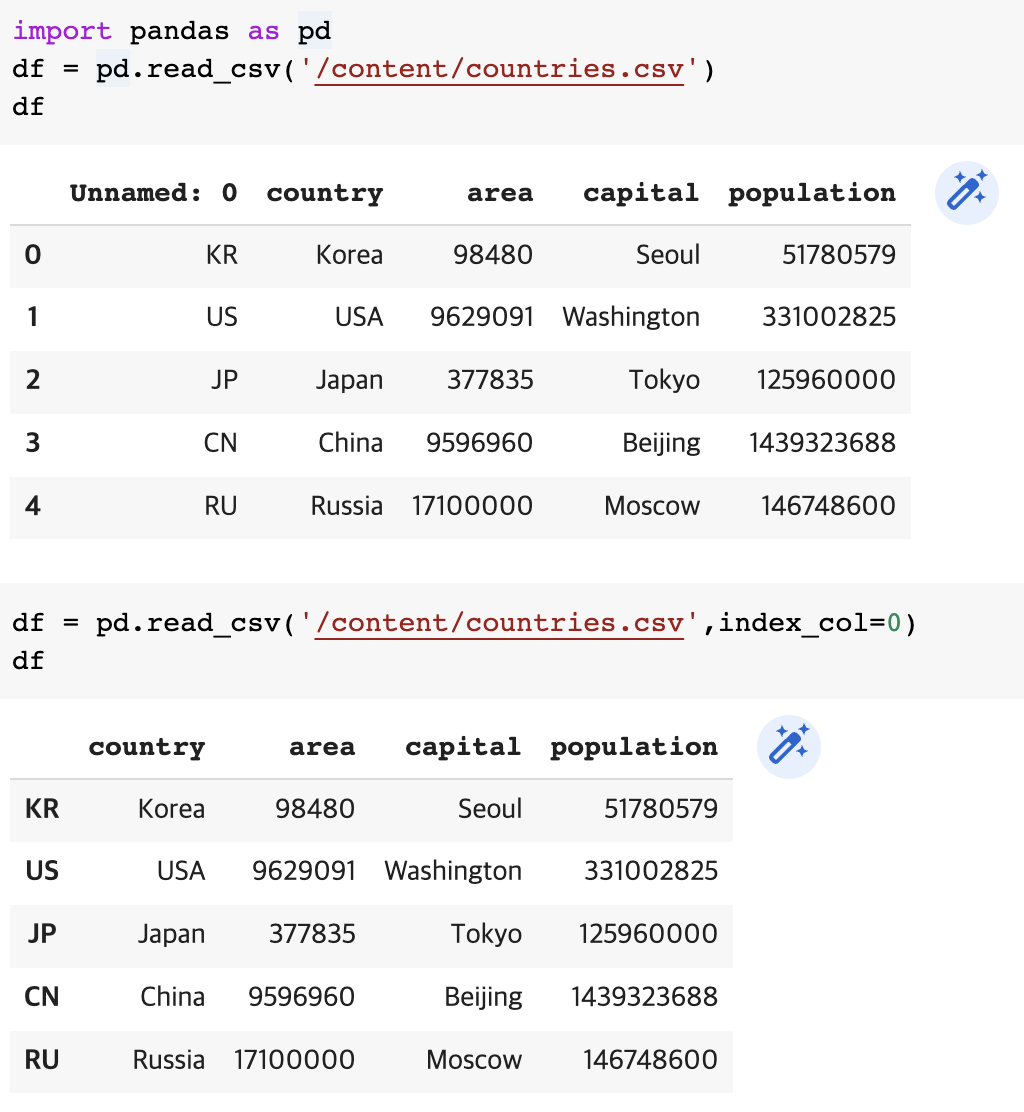
특정 열만 출력
df_index = pd.read_csv('/content/countries.csv',index_col=0)
df_no_index = pd.read_csv('/content/countries.csv')
print(df_index['population'])
print(df_no_index['population'])df_index = pd.read_csv('/content/countries.csv',index_col=0)
print(df_index[['area','population']])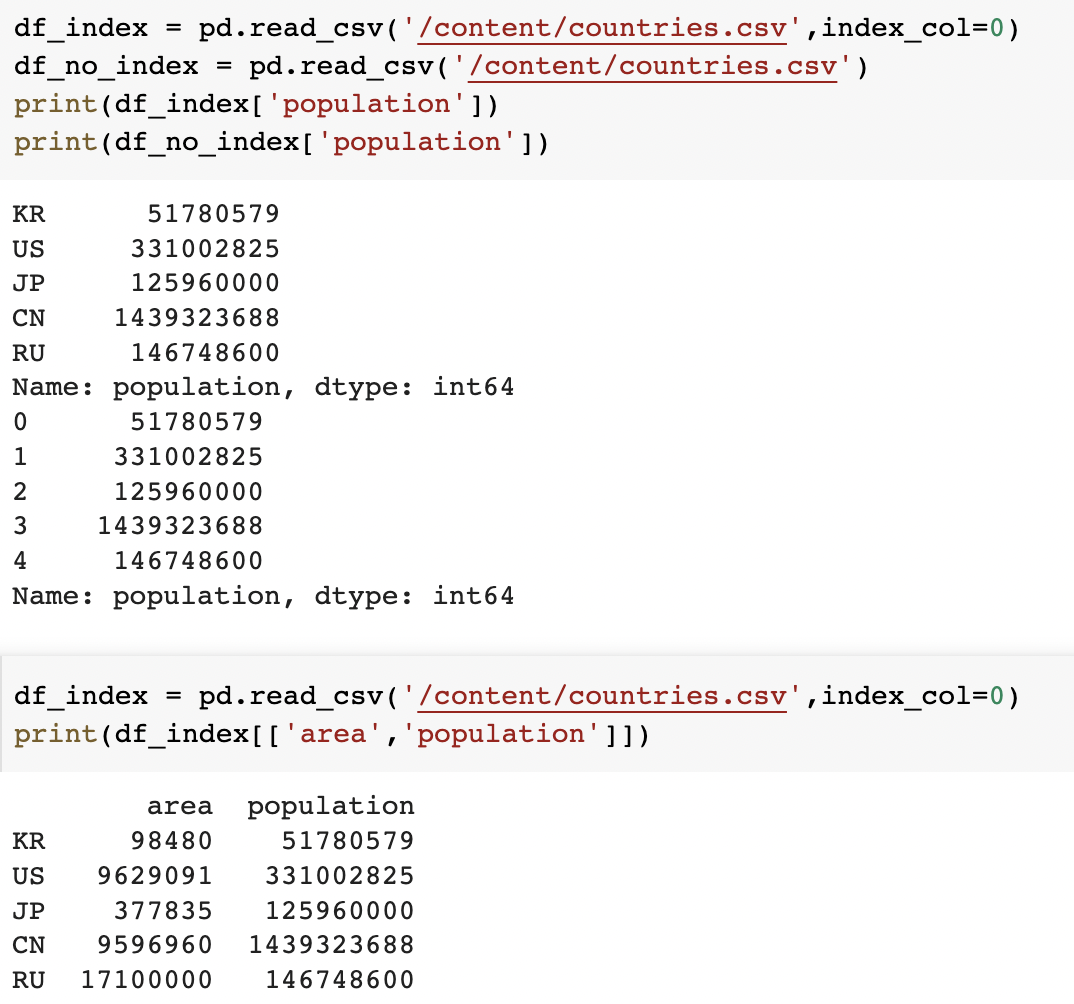
새로운 열 생성
df_index = pd.read_csv('/content/countries.csv',index_col=0)
df_index['density'] = df_index['population']/df_index['area']
print(df_index)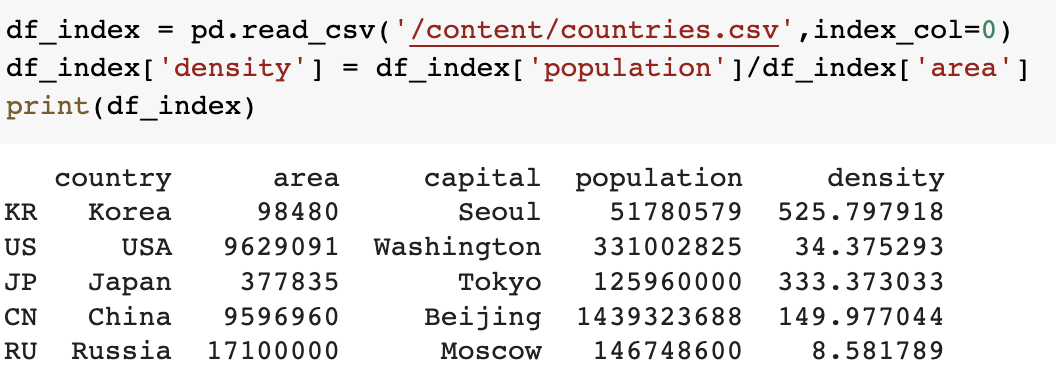
통계,결측치 확인
데이터를 간단히 분석하기 위해 describe() 함수 호출
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 0: invalid start byte 에러가 발생하여 코드에 encoding='cp949' 추가
import pandas as pd
f = pd.read_csv('/content/weather.csv',index_col=0, encoding='cp949')
print(f.describe())
print('평균 분석-----')
print(f.mean())
print('표준편차 분석-----')
print(f.std())
import pandas as pd
f = pd.read_csv('/content/weather.csv',index_col=0, encoding='cp949')
print(f.count())
print(f['최대풍속'].count())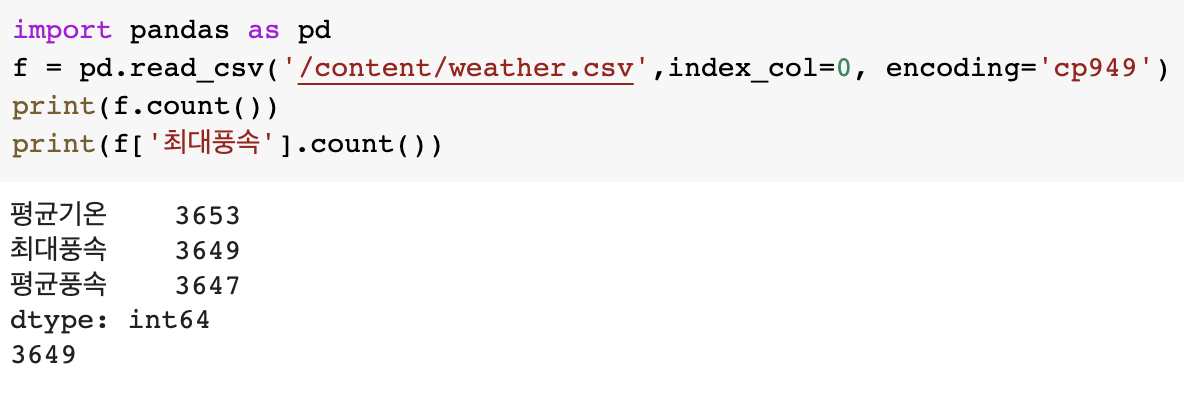
f[['최대풍속','평균풍속']].count()f[['최대풍속','평균풍속']].mean()f.mean()[['최대풍속','평균풍속']]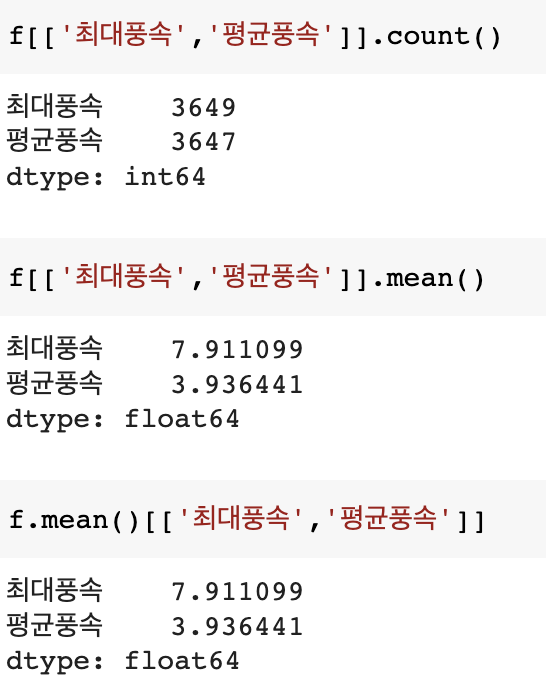
특정한 값에 기반하여 그룹핑(groupby함수)
import pandas as pd
f = pd.read_csv('/content/weather.csv', encoding='cp949')
f['month'] = pd.DatetimeIndex(f['일시']).month
means = f.groupby('month').mean()
print(means)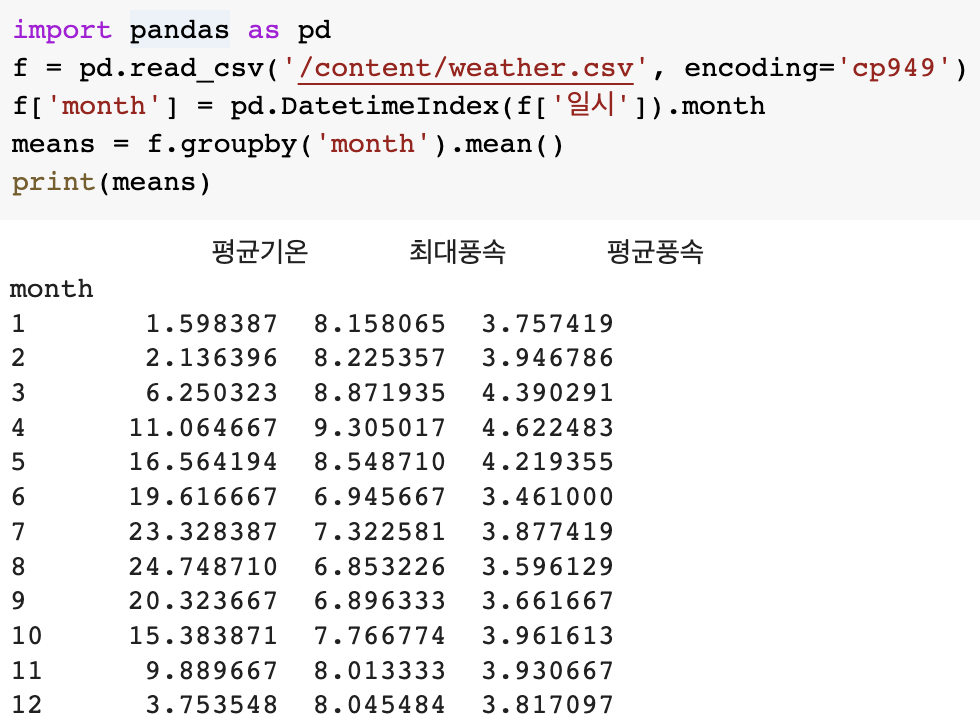
sum_data = f.groupby('month').sum()
print(sum_data)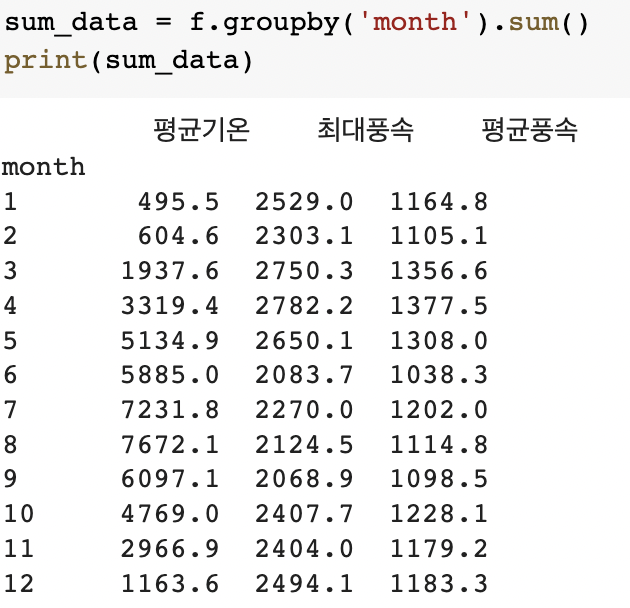
조건에 맞게 골라내는 필터링
f = pd.read_csv('/content/weather.csv', index_col = 0, encoding='cp949')
f['최대풍속'] >=10.0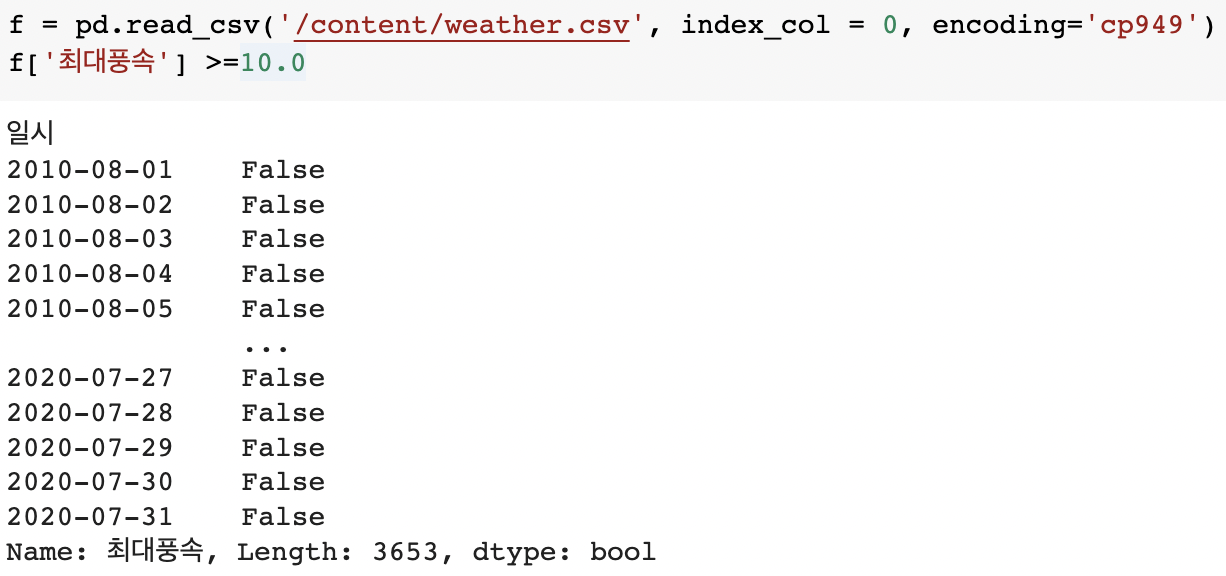
빠진 값을(결손값,nan) 찾고 삭제하는 isna()
missing_data = f[f['평균풍속'].isna()]
print(missing_data)f.dropna(axis=0, how='any', inplace=False)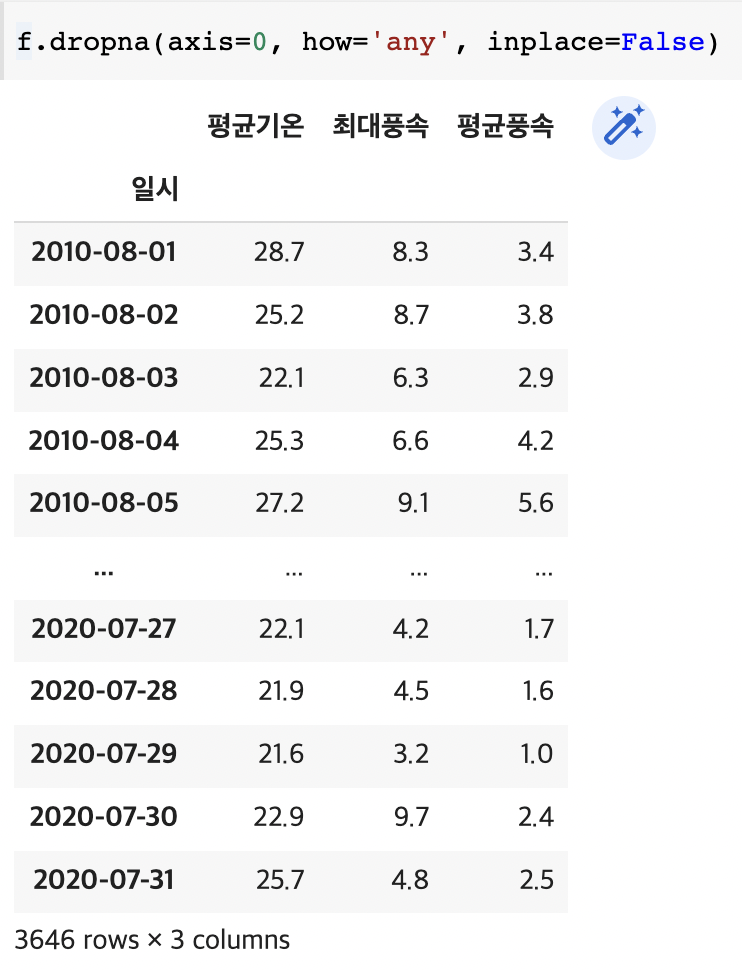

빠진 데이터를 매우는 fillna()
f = pd.read_csv('/content/weather.csv', index_col = 0, encoding='cp949')
f.fillna(0,inplace = True) #결손값을 0으로 채움
ff.fillna(f['평균풍속'].mean(),inplace = True) #결손값을 전체 데이터 평균으로 채움
f.loc['2012-02-11']

github blog 쓰다가 관리하기 귀찮아서 돌아왔다