
지금까지 encoder 쪽의 대부분의 개념들에 대해서 얘기했다.
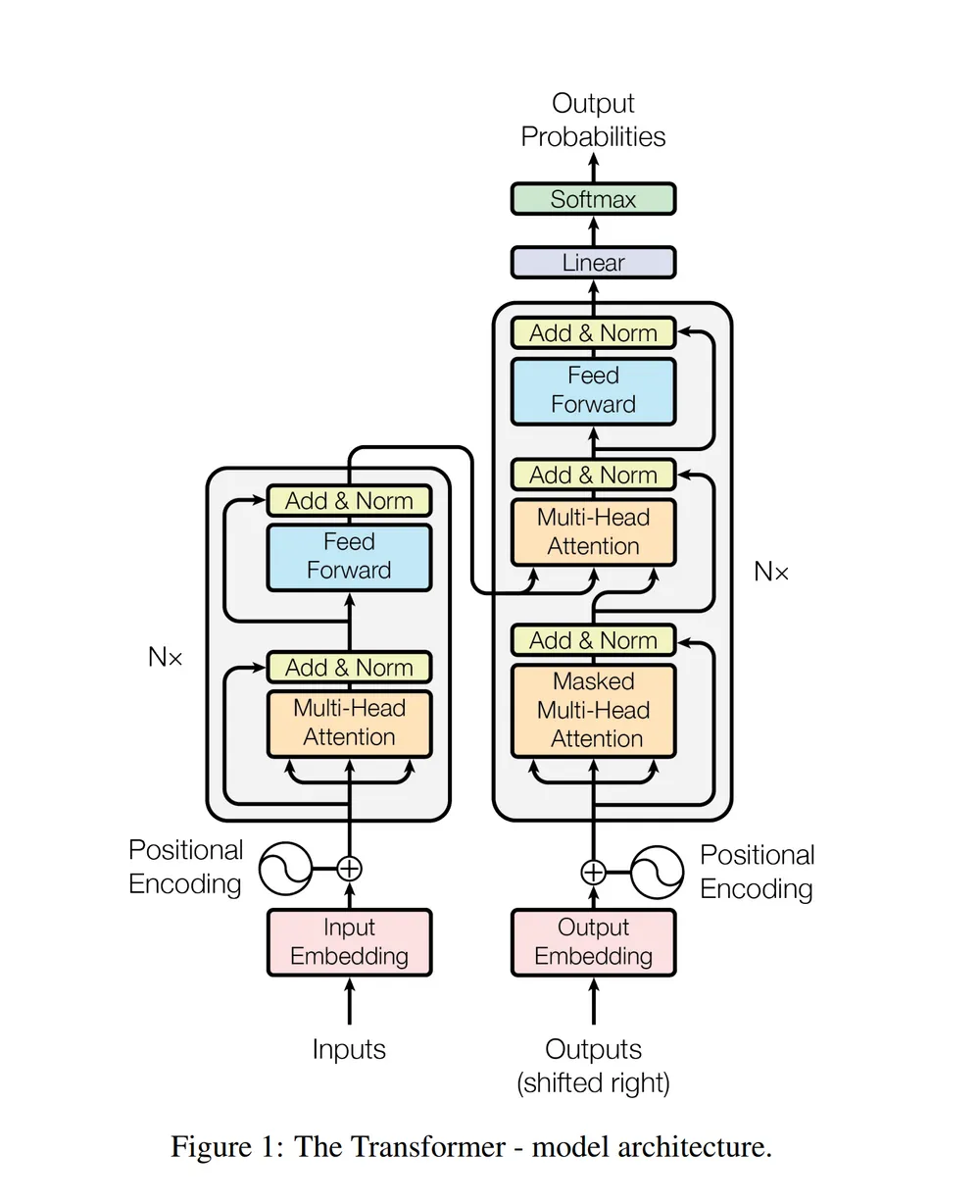
디코더는 인코더와 마찬가지로 6개의 스택으로 이주어지고,
각 디코더는 Masked Multi-head attention mechanism, Multi-head attention mechanism, feed-forward neural network로 나누어진다.
첫번째 인코더와 마찬가지로, 첫번째 디코더 역시 위치 정보와 output sequence의 위치정보와 임베딩을 입력으로 받는다.
디코더의 구조에서는 Masked Multi-Head Attention을 제외하고는 앞서 다룬 내용이므로, 다루지 않은 내용만 살펴보자.
Masked Multi-Head Attention
- 기존의 encoder-decoder 모델들은 순차적으로 입력을 전달받았는데, 트랜스포머는 전체 입력값을 전달받게 된다.
- 예를 들어 세 번째 단어를 예측할 때 네 번째 단어를 이미 알고 있다면, 올바른 순서로 문장을 생성하는 것이 불가능해진다. 그래서 다음 단어를 예측할 때 미래의 단어를 참조하지 않도록 하기 위해서 masking을 이용한다.
- Masked Multi-Head Attention은 현재 시점 이후의 단어들에 대해 마스크를 적용하여, 해당 단어들의 attention score를 무한대로 설정하여 무시하게 한다. 이를 통해 모델은 오직 현재 시점 이전의 단어들만을 참고하게 된다.
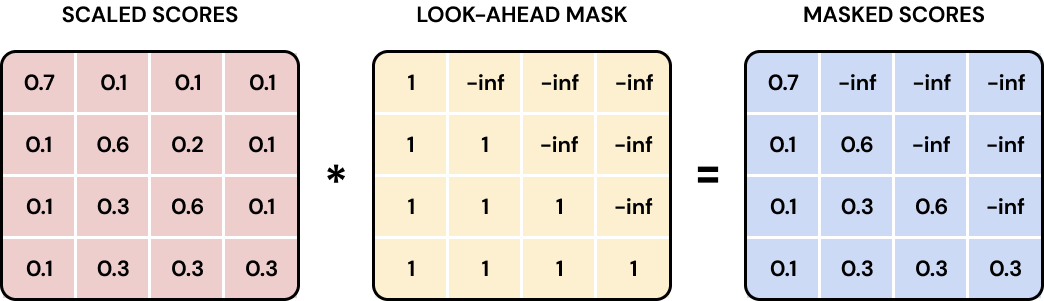
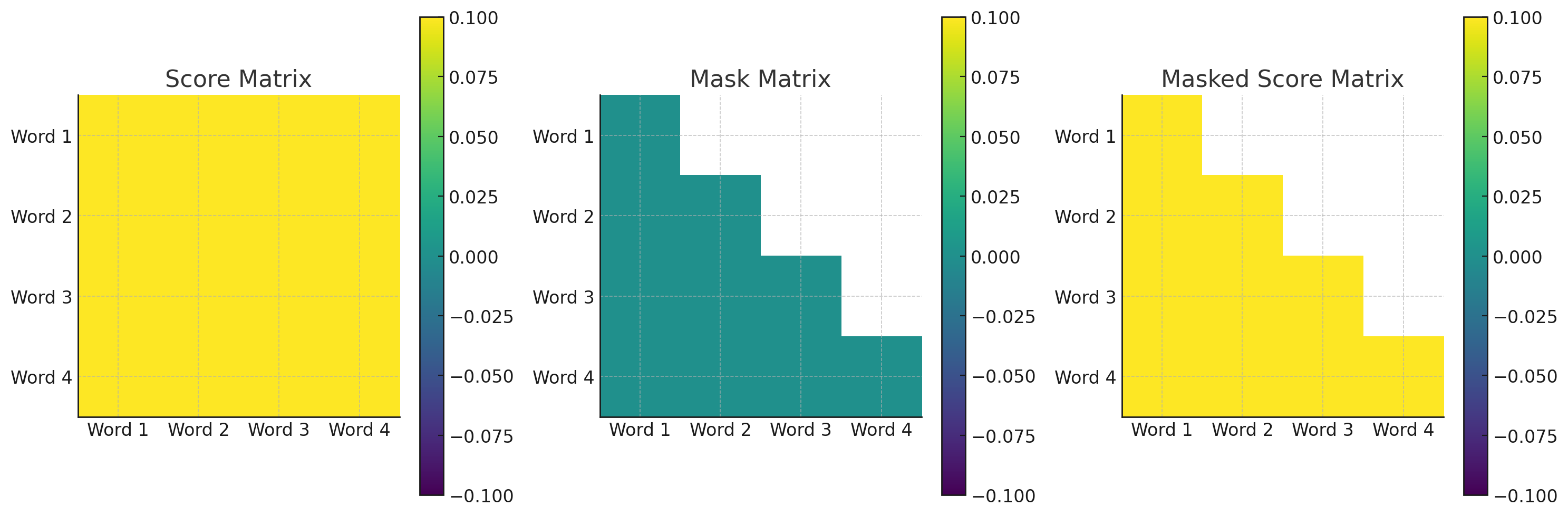
- 이 때 마스킹 행렬 M은 상삼각행렬과 같다. 미래의 단어에 대해 아주 작은 값을 설정하여, softmax 계산 시 해당 값이 0에 가까워지게 한다.
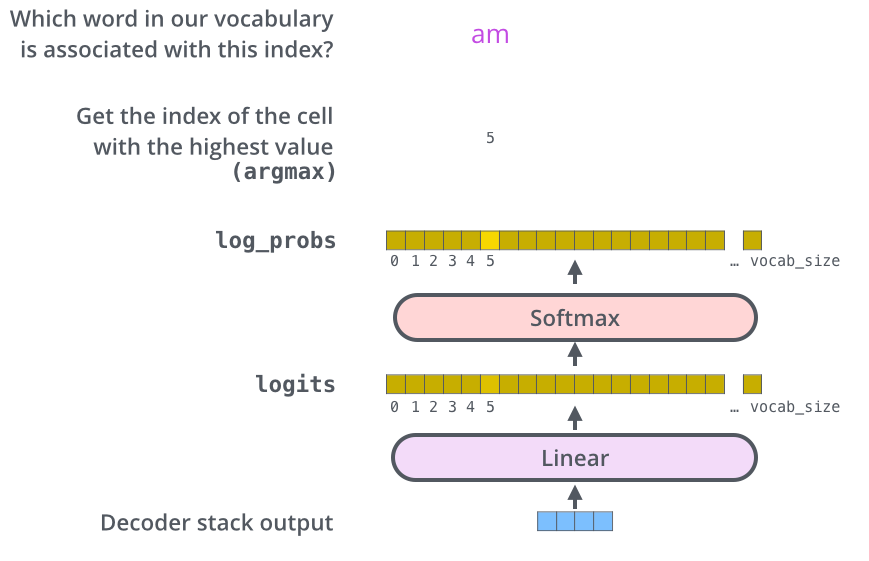
linear & softmax
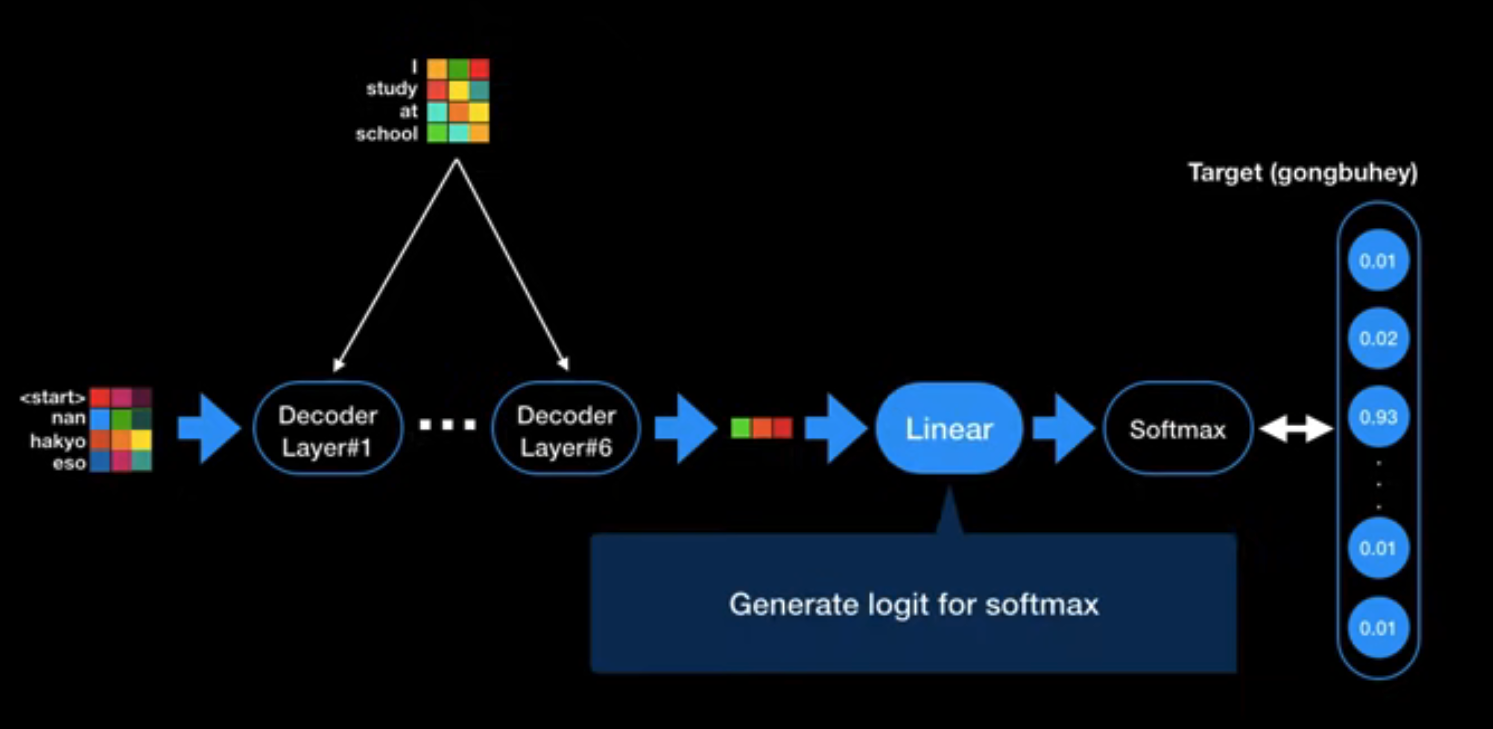
- 모든 encoder와 decoder block을 거쳐서 벡터가 나온다. 이 벡터를 실제 단어로 출력하기 위해 linear와 softmax layer를 차례대로 거친다.
- linear layer는 디코더의 마지막 레이어의 출력을 받아서 logit vector로 변환한다.
- softmax layer는 linear layer에서 나온 logit vector를 각 token이 위치할 확률로 바꿔줌
Reference

github blog 쓰다가 관리하기 귀찮아서 돌아왔다