
Introduction
- Transfomer는 2017년 Attention is all you need 라는 제목의 논문에서 발표된 모델로, (제목을 보면 알 수 있듯) Attention을 활용한 모델이다.
- Transformer 모델은 기존의 RNN, LSTM, Seq2seq 등을 이용한 태스크보다 더 좋은 성능을 보였고, 지금도 이를 변형한 수많은 모델들이 개발되고 있다.
(앞으로는 그냥 트랜스포머라고 적겠다)
Seq2seq VS 트랜스포머
ㅊ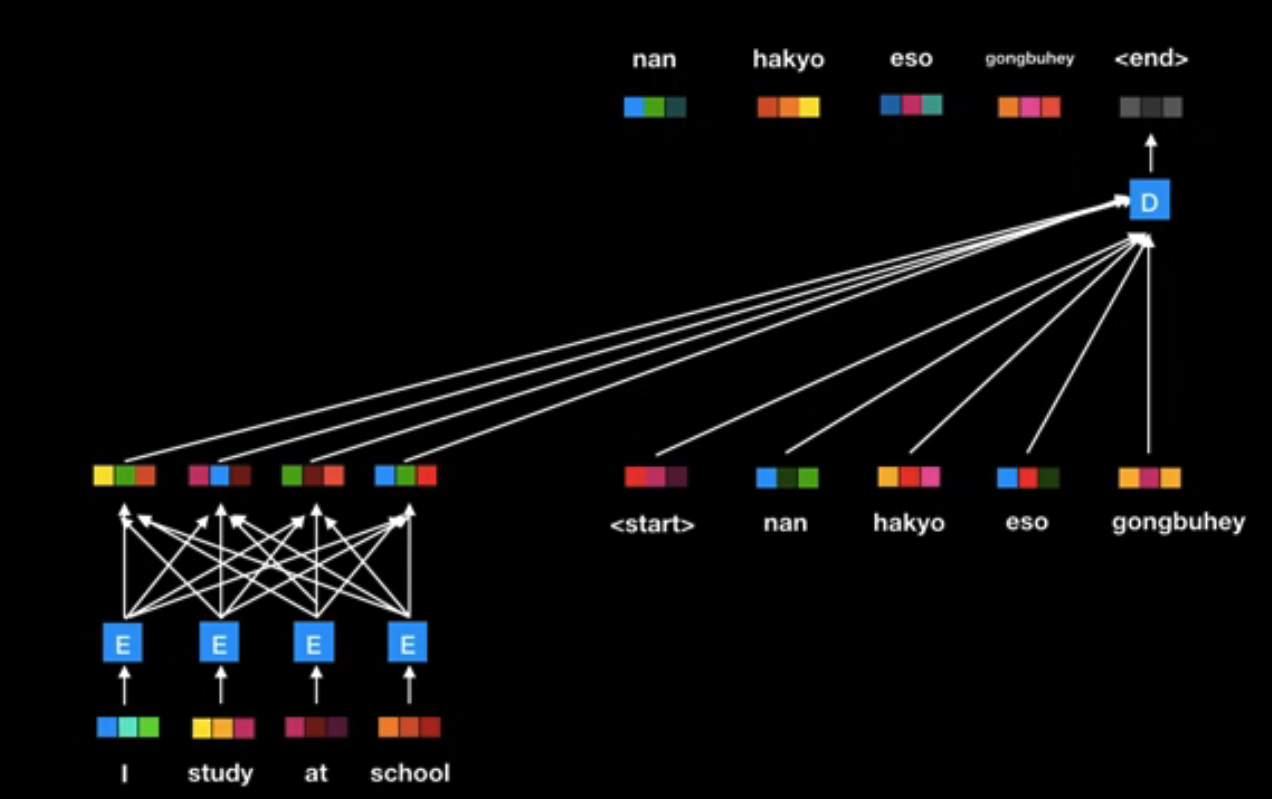
- 트랜스포머 역시 기존의 Seq2seq 모델과 같은 인코더-디코더 구조로 구성되어있는데,
- Seq2seq의 방식과는 달리 어텐션 메커니즘을 사용해 입력 문장의 특정 토큰에 집중할 수 있도록 했고
- 순차적으로 처리하는 것이 아닌 병렬처리를 지원한다.
High level look
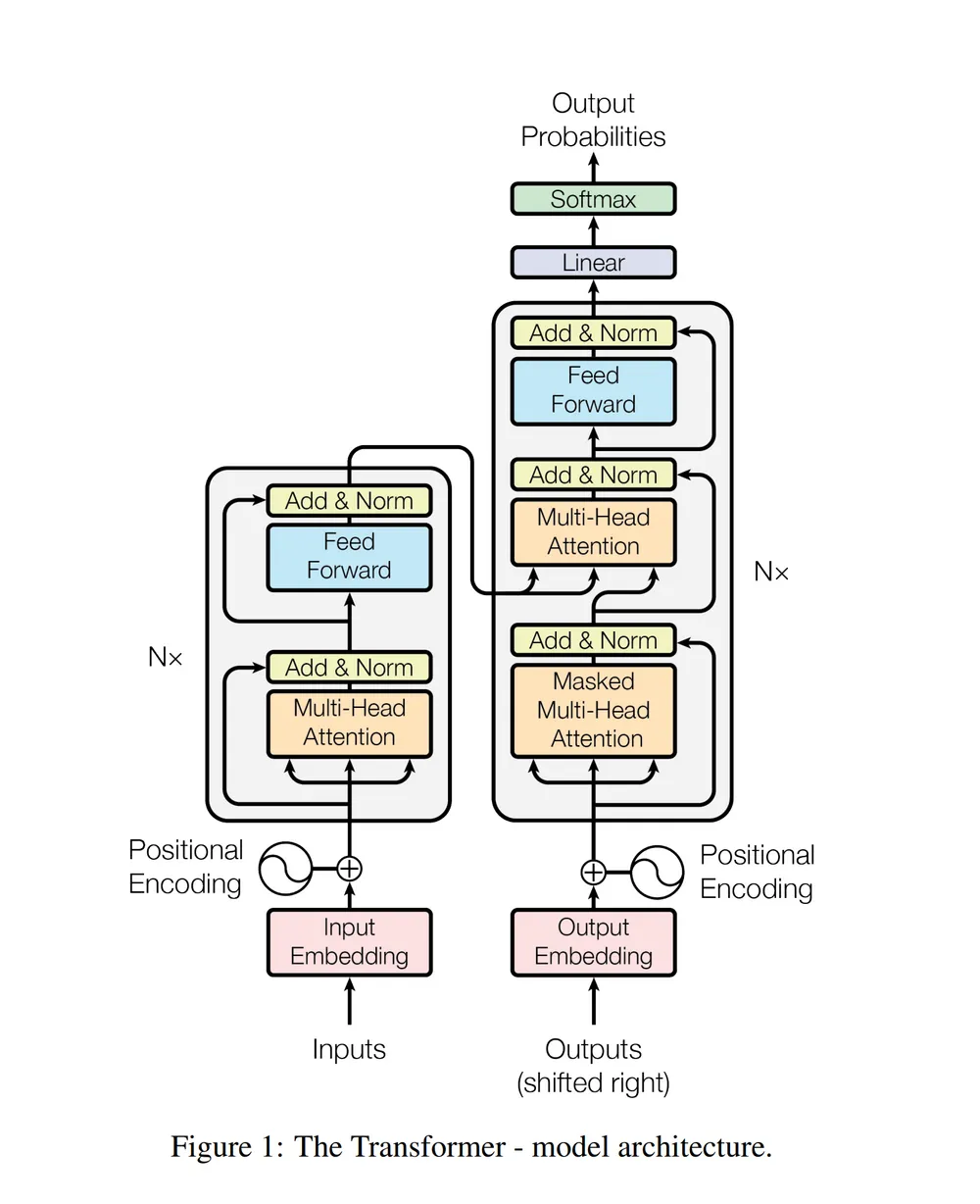
- 트랜스포머의 구조는 위와 같은데, 이를 이해하기 위해 조금 더 개괄적인 관점으로 보도록 하자.

- 기계 번역의 관점에서, 모델은 문장을 입력으로 받아 다른 언어로 된 번역을 출력으로 뱉을 것이다.
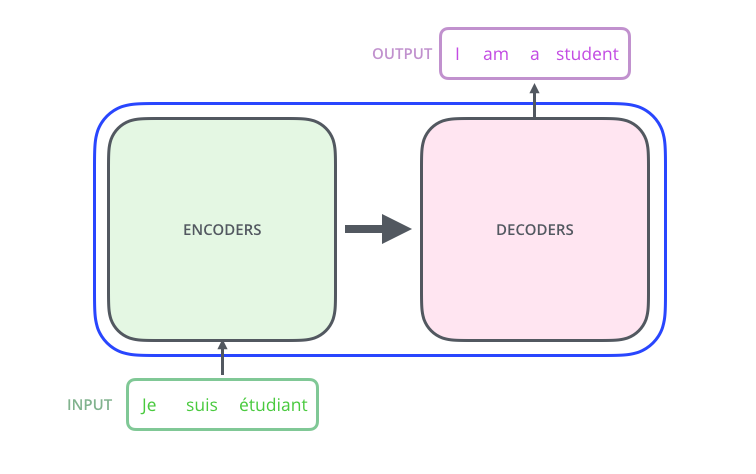
- 그 모델은 위와 같이 encoding 부분, decoding 부분, 그리고 그 사이를 이어주는 connection으로 존재한다.
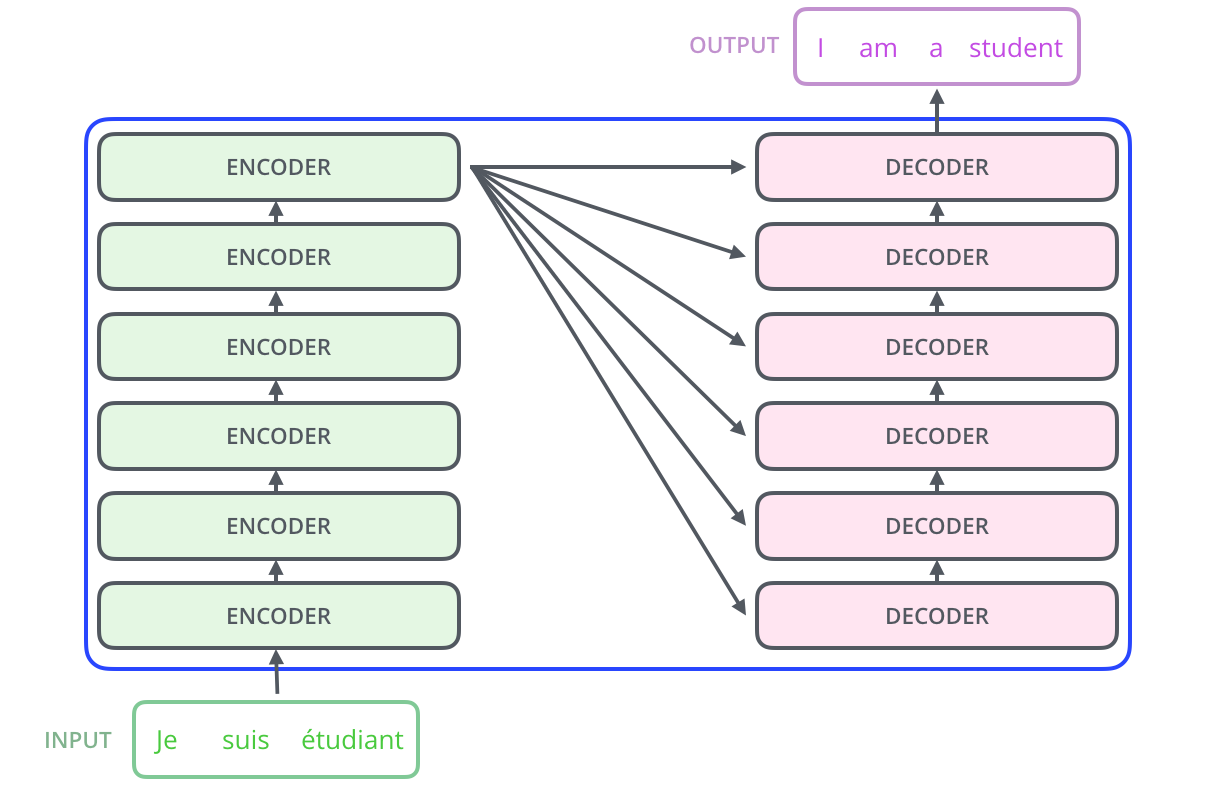
- encoding component는 인코더의 스택인데 본 논문에서는 6개를 쌓았다.(특별한 의미는 없다.)
- decoding component는 encoding 부분과 동일한 개수만큼의 decoder 을 쌓은 것이다.(마찬가지로 본 논문에서는 6개를 쌓았다)
-
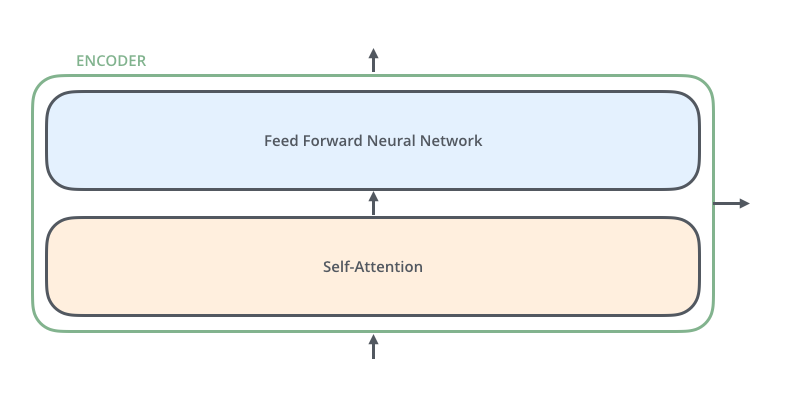
하나의 인코더에는 위 그림과 같이 두 개의 sub-layer으로 구성되어 있다.
-
input이 들어오면 self-attention layer를 통과하며 input의 모든 다른 단어들과의 관계를 살펴보고
-
self-attention layer를 통과하여 나온 출력은 다시 feed-forward 신경망으로 들어간다.
-
하나의 디코더에도 마찬가지로 위의 두 sub-layer와, 그 사이에 encoder-decoder attention이 포함되는데,
-
encoder-decoder attention이란 decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해 준다.
이제, 논문에서 제시했던 트랜스포머 내부 구조 사진 순서대로 알아보도록 하겠다.
Reference
Jay Alammar 블로그 매우 직관적인 시각자료와 함께 상세한 설명을 제공하니 꼭 읽어보시길.
Harvard NLP
위키피디아

github blog 쓰다가 관리하기 귀찮아서 돌아왔다