컨텐츠 기반 추천시스템은 사용자가 이전에 구매한 상품중에서 좋아하는 상품들과 유사한 상품들을 추천하는 방법으로 Item을 벡터 형태로 표현하여 컴퓨터가 벡터끼리의 거리를 유사도로 인식하게 하는 방법이다.
TF-IDF
단어 빈도(TF)와 전체 문서에서 특정 단어가 얼마나 자주 등장하는지를 의미하는 역문서 빈도(DF)를 통해 "다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 단어"를 찾아내 문서 내 단어의 가중치를 계산하는 방법
문서의 핵심어 추출, 문서들 사이의 유사도 계산, 검색 결과의 중요도를 정하는 작업등에 활용할 수 있다.
장점
직관적인 해석이 가능하다.
TF(d, t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
DF(t) : 특정 단어 t가 등장한 문서의 수
IDF(d, t) : DF(t)에 반비례하는 수
n은 문서 수, t는 단어
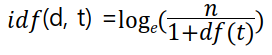
예시

문서내 단어의 TF값, DF값 계산
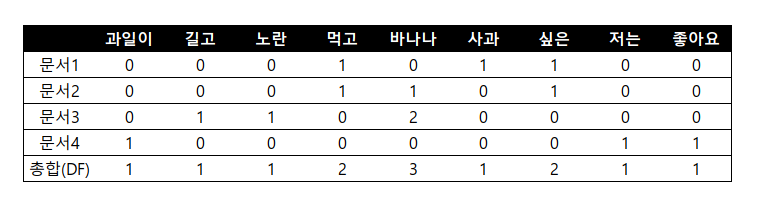
단어의 IDF값 계산

단어간 TF * IDF

문서간의 유사도 : cos similarity 사용하여 계산
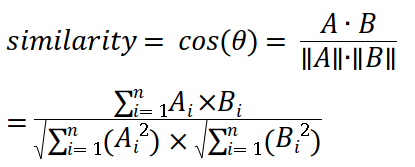
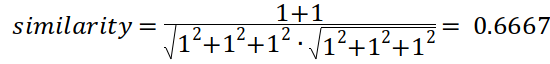
단점
높은 차원을 가지고 매우 sparse한 형태의 데이터이기 때문에 대규모 말뭉치를 다룰 때 메모리상의 문제가 발생한다.
code
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
# 각 문서에 나온 단어 Count
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
countvect = vect.fit_transform(docs)
countvect_df = pd.DataFrame(countvect.toarray(), columns = sorted(vect.vocabulary_))
countvect_df.index = ['문서1', '문서2', '문서3', '문서4']
# TF-IDF 계산
from sklearn.feature_extraction.text import TfidfVectorizer
tfidv = TfidfVectorizer(use_idf=True, smooth_idf=False, norm=None).fit(docs)
tfidv_df = pd.DataFrame(tfidv.transform(docs).toarray(), columns = sorted(tfidv.vocabulary_))
# 문서 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(tfidv_df, tfidv_df)Word2Vec
단어간 유사도를 반영하여 단어를 벡터로 바꿔주는 임베딩 방법론
추천시스템에서 단어를 구매 상품으로 바꿔 구매한 패턴에 Word2Vec을 적용하면 유사한 상품을 찾을 수 있다.
장점
one-hot vector의 sparse matrix가 가지는 단점을 해소하기 위해 저차원의 공간에 벡터로 매핑한다.
저차원의 학습된 단어의 의미를 분산하여 표현하기 때문에 단어간 유사도를 계산할 수 있다.
가정
"비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다"의 가정을 통해 학습을 진행한다.
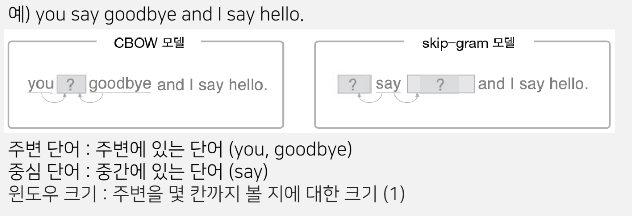
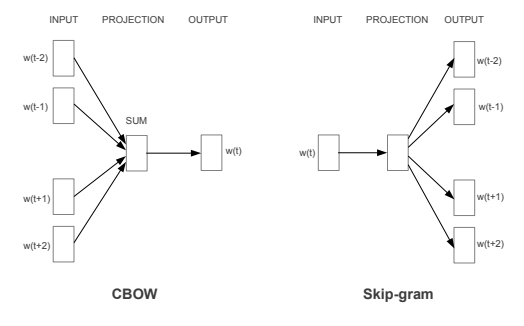
CBOW와 Skip-Gram
CBOW : 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
Skip-Gram : 중간에 있는 단어로 주변 단어들을 예측하는 방법
장점
- 자신의 평점만을 가지고 추천시스템을 만들 수 있다.(협업필터링은 다른 사용자의 평점이 필요하다.)
- item의 feature을 통해 추천을 하기 때문에 추천이 된 이유를 설명하기 용이하다.
- 사용자가 평점을 매기지 않은 Item이 들어올 경우에도 추천이 가능하다.
단점
- Item의 feature을 추출해야 하고, 이를 통해 추천하기 때문에 Feature을 추출하지 못하게 되면 정확도가 낮아질 수 있다. => Domain knowledge가 분석시에 필요할 수도 있다.
- 기존의 item과 유사한 item 위주로만 추천하기 때문에 새로운 장르의 item을 추천하기 어렵다.
- 새로운 사용자에 대해서 충분한 평점이 쌓이기 전까지는 추천하기 힘들다.
code
from gensim.models import Word2Vec
docs = ['you say goodbye and I say hello .']
sentences = [list(sentence.split(' ')) for sentence in docs]
model = Word2Vec(size=3, window=1, min_count=1, sg=1)
model.build_vocab(sentences)
model.wv.most_similar("say")
