git : choco9966/T-academy-Recommendation의 내용을 정리한 것입니다.
추천시스템 목표 : 어떤 사용자(user)에게 어떤 상품(item)을 어떻게 추천할 것인가
- 방법 1 : 다른 사람들과 같이 본 상품 추천
- 방법 2 : 유사한 상품 추천
추천시스템은 아래와 같이 발전해왔다.
연관상품 추천, Apriori 알고리즘
협업 필터링 : SVD
Spark를 이용한 빅데이터 : FP-Growth, Matrix Factorization
딥러닝을 이용한 추천시스템 : 협업필터링 + 딥러닝, Item2Vec, Doc2Vec, YouTube Recommendation, Wide & Deep Model
개인화 추천시스템 : Factorization Machine, Hierarchical RNN, 강화학습 + Re-Ranking, 딥러닝
위의 발전 순서 중 과거의 추천시스템을 정리해보려한다.
연관상품 추천, Apriori 알고리즘
연관분석 ( Association Analysis )
상품과 상품사이에 어떤 연관이 있는지 Rule(알고리즘)을 찾기
- 같이 구매하는 빈도 수
- A item을 구매하는 사람이 B item을 구매하는가?
평가 지표
1. Support ( 지지도 ) : A -> B일 때, support(A) = P(A)
2. lift ( 향상도 )
3. confidence ( 신뢰도 )
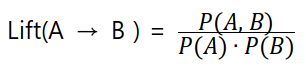
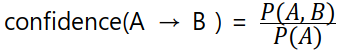
규칙 생성
가능한 모든 경우의 수를 탐색해서 지지도, 신뢰도, 향상도가 높은 규칙들을 찾아내는 방식
상품이 4개일 때, 전체 경우의 수는
4C1 + 4C2 + 4C3 + 4C4 = 4 + 6 + 4 + 1 = 15
단점
- item의 증가에 따라 Rule의 수가 급격하게 증가(ex. num(itme)=100, 1.26*10^30 )
Apriori 알고리즘
연관분석에서 item set의 증가를 줄이기 위한 방법으로 빈번하지 않은 itemset을 삭제하여 Rule의 수를 줄인다.
장점
- 원리가 간단하여 쉽게 이해할 수 있고 의미를 파악할 수 있다.
- 유의한 연관성을 갖는 구매패턴을 찾아준다.
아래의 가정에 기반한다.
빈번한 itemset은 하위 itemset 또한 빈번할 것이다.
빈번하지 않은 itemset은 하위 itemset 또한 빈번하지 않다.
support({2, 3}) > support({0,2,3}), support({1,2,3})
알고리즘 (방법)
1. K개의 item을 가지고 단일항목집단 생성(one-item frequent set)
2. 단일항목집단에서 설정된 성능(support, lift, confidence 중 1가지 이상)의 최소값 이상의 항목만 선택
3. 2에서 선택된 항목만을 대상으로 2개항목집단 생성
4. 2개항목집단에서 최소 성능값 이상의 항목만 선택
5. 위의 과정을 k개의 k-item frequent set을 생성할 때까지 반복

예시(5 item)
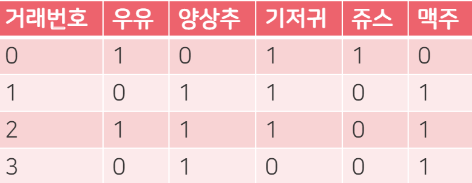
- one-item frequent set : 우유, 양상추, 기저귀, 쥬스, 맥주 (5가지)
- 최소 지지도(support)가 0.5일 때, 최소 지지도 이상의 항목만 선택
P(우유) : 0.5
P(양상추) : 0.75
P(기저귀) : 0.75
P(쥬스) : 0.25
P(맥주) : 0.75 - 2-item frequent set(2개 집단 생성) : {우유, 양상추}, {우유, 기저귀}, {우유, 맥주}, {양상추, 기저귀}, {양상추, 맥주}, {기저귀, 맥주} (6가지)
- 최소 지지도 이상의 항목만 선택
P({우유, 양상추}) : 0.25
P({우유, 기저귀}) : 0.5
P({우유, 맥주}) : 0.25
P({양상추, 기저귀}) : 0.5
P({양상추, 맥주}) : 0.75
P({기저귀, 맥주}) : 0.5 - 위의 과정을 k개의 k-item frequernt set을 생성할 때까지 반복
P({양상추, 기저귀, 맥주}) : 0.5
P({우유, 기저귀,맥주}) : 불가능. 제거된 항목에 있다.
단점
- 데이터가 클 경우 (item이 많을 경우) 속도가 느리고 연산량이 많다.
- 실제 사용시에 많은 연관상품들이 나타나는 단점이 있다.
code (mlxtend 패키지)
import mlxtend
import numpy as np
from mlxtend.preprocessing import TransactionEncoder
data = np.array([
['우유', '기저귀', '쥬스'],
['양상추', '기저귀', '맥주'],
['우유', '양상추', '기저귀', '맥주'],
['양상추', '맥주']
])
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
%%time
from mlxtend.frequent_patterns import apriori
apriori(df, min_support=0.5, use_colnames=True)Spark를 이용한 빅데이터 : FP-Growth
FP-Growth 알고리즘
장점
- 속도가 느리다는 단점을 개선한 알고리즘(FP Tree라는 구조를 사용). 2번의 탐색만 필요로 함.
- 후보 Itemset을 생성할 필요 없이 진행 가능
알고리즘 (방법)
- 모든 거래를 확인하여 각 item마다의 성능(support, lift, confidence 중 1가지 이상) 계산, 최소 성능 이상의 item만 선택
- 모든 거래에서 빈도가 높은 아이템 순서대로 정렬
- 부모 노드를 중심으로 거래를 자식노드로 추가해주면서 tree 생성
- 새로운 아이템이 나올 경우에는 부모노드부터 시작하고, 아니면 기존의 노드에서 확장
- 모든 거래에 대해 위의 과정 반복하여 FP-TREE를 만들고 최소 성능 이상의 패턴만을 추출
예시(5 item)
1. 모든 거래를 확인 : 우유, 양상추, 기저귀, 쥬스, 맥주 (5가지)
2. 최소 지지도(support)가 0.5일 때, 최소 지지도 이상의 항목만 선택, 정렬
P(우유)=0.5, P(양상추)=0.75, P(기저귀)=0.75, ~~P(쥬스)=0.25~~, P(맥주)=0.75
0 : 우유, 기저귀,
쥬스=> 기저귀, 우유
1 : 양상추, 기저귀, 맥주 => 양상추, 기저귀, 맥주
2 : 우유, 양상추, 기저귀, 맥주 => 양상추, 기저귀, 맥주, 우유
3 : 양상추, 맥주 => 양상추, 맥주
- 부모 노드를 중심으로 거래를 자식노드로 추가해주면서 tree 생성
0번거래 추가(기저귀, 우유)

- 새로운 아이템이 나올 경우에는 부모노드부터 시작하고, 아니면 기존의 노드에서 확장
1번거래 추가(양상추, 기저귀, 맥주) : 새로운 item
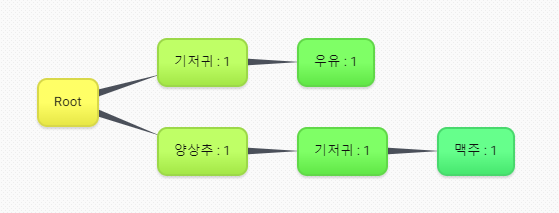
2번거래 추가(양상추, 기저귀, 맥주, 우유) : 기존 노드에서 확장
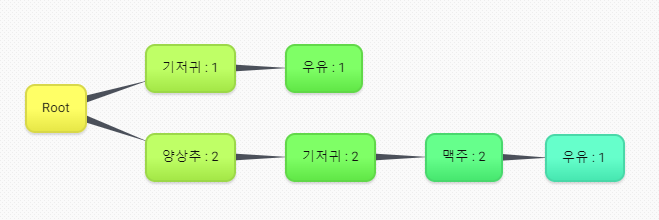
3번거래 추가(양상추, 맥주) : 기존 노드에서 확장
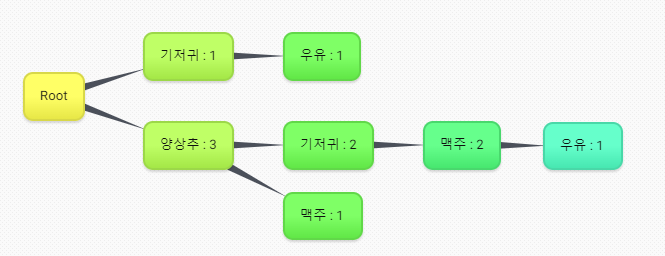
- 모든 거래에 대해 위의 과정 반복하여 FP-TREE를 만들고 최소 성능 이상의 패턴만을 추출
단점
- item간의 연관성을 찾기가 어려움
- Apriori 알고리즘에 비해 설계가 어려움
- 대용량의 데이터셋에서 메모리를 효율적으로 사용하지 않음
- 지지도의 계산이 FP-Tree가 만들어지고 나서야 가능함
code (mlxtend 패키지)
import mlxtend
import numpy as np
from mlxtend.preprocessing import TransactionEncoder
data = np.array([
['우유', '기저귀', '쥬스'],
['양상추', '기저귀', '맥주'],
['우유', '양상추', '기저귀', '맥주'],
['양상추', '맥주']
])
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 여기부터 다르다.
%%time
from mlxtend.frequent_patterns import fpgrowth
fpgrowth(df, min_support=0.5, use_colnames=True)과거에 사용된 추천시스템 알고리즘인 연관상품 추천, Apriori 알고리즘, FP-Growth의 알고리즘을 보았다.
다음에는 컨텐츠 기반 추천 모델 개념을 볼 것이다.(역시나 위의 git을 참조해서)
