VA-VAE는 Autoencoder 구조에서 codebook을 더한 구조입니다. codebook이란 이산 데이터로 매핑되는 집합으로, 연속적인 데이터를 이산 데이터로 변환합니다. CodeBook을 기본적으로 vector를 요소로 가지는 리스트 입니다. input이 Encoder를 지나 출력으로 어떠한 vector가 나오면, codebook의 모든 vector들 간 distance를 계산합니다. 그 다음 Codebook의 vector들 중에서 encoder의 출력vector와 가장 거리가 짧은 vector를 찾습니다. 그리고 그 벡터를 decode에 넣어 학습을 진행합니다.
그림으로 쉽게 알려드리겠습니다.
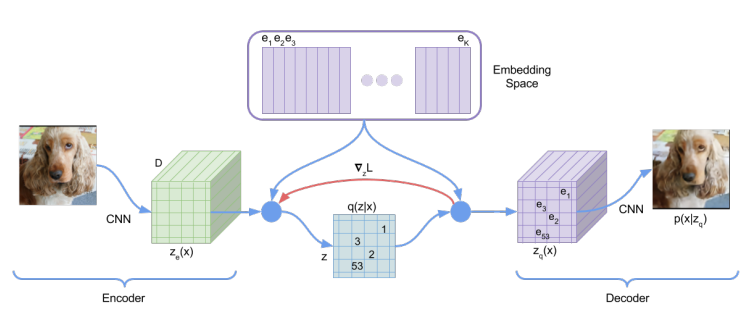
강아지 이미지를 encoder에 넣어 vector 가 출력되신 것을 볼 수가 있습니다. 이때 나온 출력 와 codebook의 vector들 간 거리를 계산해봅니다.
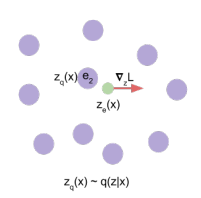
codebook의 vector들과 계산해본 결과 가 가장 가까운 것을 확인하였고 대신 를 decoder에 넣어 학습을 진행합니다.
Codebook 안에 vector의 수를 제한하면 다양한 이미지 생성에 영향을 줄 수 있다는 의문이 생길 수 있습니다. 그렇지만 encoder의 출력은 하나의 vector가 아닌 64X64X1 같은 vector가 출력 되도록 encoder를 설계할 수 있고, 이때 각 grid는 위에서 했던 과정을 거쳐 codebook의 vector들 중 가장 가까운 vector 변환 될 것 입니다. 때문에 만약 codebook의 list의 크기가 512라면 만큼의 이미지들을 생성 할 수 있습니다. 밑에 그림을 보시면 도 쉽게 이해 할 수 있습니다.
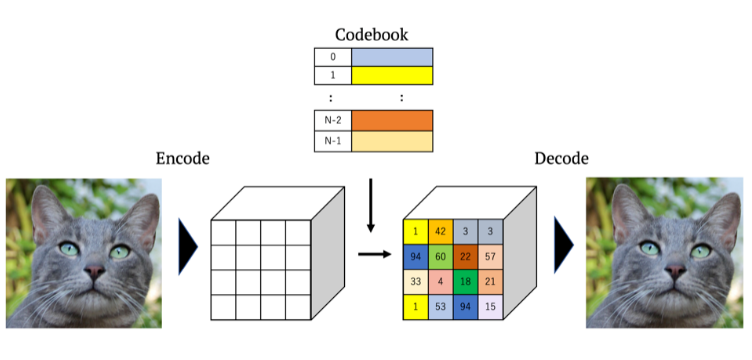
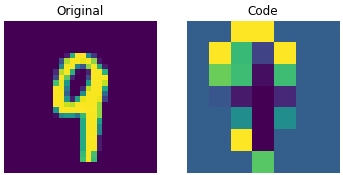
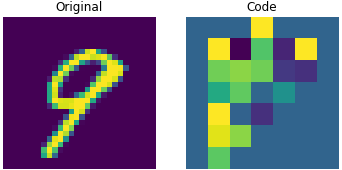
밑에 그림은 이미지 사진을 encoder에 넣었을 때 codebook의 벡터들로 대체된 모습을 보실 수 있습니다
loss funtion
첫번째 항(Reconstruction Loss) :
Decoder와 encoder를 최적화하는 부분
두번째 항(Codebook alignment loss) :
출력은 encoder 출력인 ze(x)와 가장 가장 가까운 codebook 내 vector e_i가 z_e(x)와 더 가까워지도록 한다.(코드북 벡터가 encoder의 출력 z(x)로 이동하게끔한다)
세번째 항 (Codebook commitment loss)
임베딩space은 무한하기 때문에 ei는 encoder parameter만큼 빠르게 학습되지 않을 수 있다. Encoder가 임베딩과 출력이 grow할 수 있도록 한다.
내가 궁금했던 점
straight-through estimator란? (Chatgpt 대답..)
straight-through estimator는 양자화된 표현을 사용하여 forward pass를 진행하고, backward pass에서는 그래디언트 역전파를 위해 양자화된 표현을 거친 값 대신 원래 연속적인 값에 대한 그래디언트를 전달하는 방법입니다. 즉, forward pass에서는 양자화된 표현을 사용하여 계산하고, backward pass에서는 원래 연속적인 값에 대한 그래디언트를 전달하여 역전파를 수행합니다.
이를 통해 straight-through estimator는 양자화된 표현을 효과적으로 학습하면서도 원래 연속적인 값에 대한 그래디언트를 전달하여 모델을 업데이트할 수 있게 합니다. 이는 VQ-VAE에서의 양자화 과정과 그래디언트 역전파를 조화롭게 결합하는 데 사용되는 중요한 기법입니다.
Reference
https://nrhan.tistory.com/entry/VQ-VAE%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4
