T2M-GPT: Generating Human Motion from Texutal Description with Discrete Representations
Human Motion
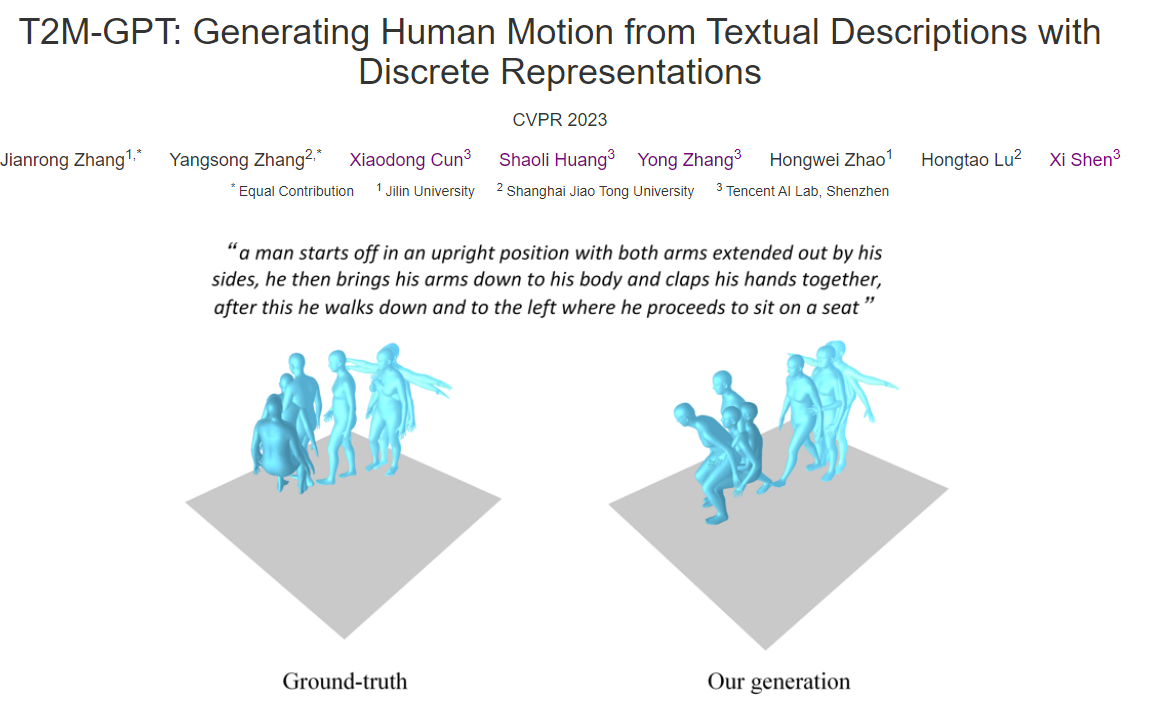
#Abstract
텍스트 설명으로부터 인간의 동작을 생성하기 위해 VQ-VAE와 GPT를 기반으로 생성 Framework 조사.
일반적으로 사용되는 training recepes(EAM와 Code Reset) CNN기반 VQ-VAE를 사용하여 고품질의 이산표현을 얻을 수있음을 보여줌.
GPT에서 훈련 중간에 간단한 corruption(손상) 전략을 도입하여 train-test discrepancy(불일치)를 완하시키는 것이 가능하는 것을 설명하고 이러한 방법은 최근 diffusion 기반 접근법을 포함한 다른 접근법보다 우수한 성능을 보인다고한다.
예를 들어 현재 가장 큰 Dataset인 HumanML3D에서 생성된 모션과 텍스트 간의 일관성(R-Precision)에서 비슷한 성능을 보이지만, FID 0.116으로 MotionDiffuse의 0.630보다 우수한 결과가 나옴.
EMA란?
Exponential Moving Average의 약자로, 이동 평균을 사용하여 모델 파라미터를 업데이트 하는 기술.
안정성과 일반화 능력을 향상시키는데 도움이 됨.
FID란?
Frechet Inception Distance(프레쳇 인셉션 거리)
생성된 이미지의 분포와 원래 이미지의 분포가 어느정도 비슷한지 측정하는 지표
(작을 수록 실제 이미지에 가까운 이미지가 생성)
#Introduction
텍스트 설명으롭부터 동작을 생성한느 것은 게임 산업, 영화 제작 및 로봇 애니메이션 등 다양한 분야에서 사용될 수 있다. 예를 들어, 게임 산업에서 새로운에 접근하는 일반적인 방법은 비썬 motion captiion을 수행하는 것이기 때문에 텍스트 설명으로부터 자동으로 동작을 생성하여 의미있는 동작 데이터를 생산 할 수 있다면 시간과 비용이 절약할 수 있다
motion과 text는 서로 다른 modalities를 가지기 때문에 자연어로 motion 생성은 매우 어렵다. model은 언어 공간에서 동작 공간으로 정확한 매핑을 학습해야합니다. 이를 위해 많은 연구들이 Auto Encoder 및 VAE를 사용하여 언어와 동작의 공동 임베딩을 학습하도록 제안한다. MotionClip은 동작공간을 CLIP 공간에 맞추고, ACTOR 및 TEMOES 는 각각 Acton to Motion a그리고 text to Motion을 위한 Transforemr 기반 VAE를 제안합니다. 좋은 성능을 보이는 연구들이 있지만, text설명이 길고 복잡해지면 품질 좋은 동작을 생성하는 것에 제한이 있다. Guo 및 TM2T는 더 어려운 텍스트 설명으로부터 동작을 생성하기 위해 노력하였지만, 두 접근 방식 모두 직관적이지 않고, text to motion을 생성을 위해 세단계가 필요하며, 때로는 텍스트와 일치하는 고품질의 동작을 생성하지 못 할 수도 있다. 최근에 이미지 생성의 인상적은 결과를 보여준 diffusion-based model이 나왔고 이것을 이용한 MDM 그리고 MotionDiffuse 등 같은 모션생성 모델이 소개 되었다, 그러나 classic한 접근방식인 VQ-VQE와 비교하여 diffusion 기반 접근 방식의 성능이 크지 않음을 발견했다. 이 연구에서는 생성을 위한 이산 표현 학습의 최근 발전에 영감을 받아 VQ-VAE 및 GPT를 기반으로 간단하고 classic한 프레임워크를 조사하여 text-to-motion 생성에 적용한다.
텍스트 설명으로부터 동작을 생성하기 위해 두 단계 표현을 제안한다. 1단계에는 표준 1D 합성곱 신경망을 사용하여 동작 시퀸스를 이산 코드 인덱스로 매핑하고 2단계에서는 pretrained text model로 부터 code indices를 생성하기 위해 standard GPT 같은 모델을 학습한다. VQ-VQE의 학습은 code collapse 문제가 발생할 수 있기 때문에 이를 해결하기 위해 효과적인 방법 EMA 및 Code Reset 두가 standard recipes를 학습중에 활용했다. 이 연구는 quantization 전략에 대한 분석을 제공하는데, GPT의 경우 다음 토큰 예측은 학습과 추론사이에 불일치를 가져온다. 이것을 완하하기 위해 sequence를 simply corrupt하였고 또한 데이터셋 크기가 모델성능에 영향을 준다는 것을 탐구하였고, 이 모델을 더큰 데이터셋으로 개선될 가능성이 더 크다고 제안한다.
(그다음 문장들은 MotionDiffuse모다 성능이 더좋음을 설명)
Motion VQ-VAE
VQ-VAE에 대해서 간단하게 설명하는 글을 하나 올렸습니다.
T2M-GPT
