*ElasticSearch 공식문서: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html?baymax=KR-ES-getting-started&elektra=landing-page
- ElasticSearch 개요 및 아키텍처
-
ElasticSerach란?
: 오픈소스 기반의 분산형 검색 및 분석 엔진임
: JSON 기반 RESTful API를 제공하여 다양한 애플리케이션과 쉽게 연동 가능함
: Apache Lucene을 기반으로 개발된 고성능 검색 엔진임
- Apache Lucene이란? : 고성능, 확장 가능한 오픈소스 검색 라이브러리로, Java 기반으로 개발되었음 - Apache Lucene의 주요 특징 1. 텍스트 색인 및 검색 : Lucene은 문서를 토큰화하고, 역색인 구조를 생성하여 빠른 검색이 가능하도록 함 2. 강력한 검색 기능 2-1. Full-Text Search (단어, 문장, 구문 검색) : 문서나 데이터에서 텍스트 기반으로 원하는 정보를 빠르게 검색하는 방법임 : 단순한 문자열 검색이 아니라, 자연어 처리 기법을 적용하여 보다 정확한 검색 결과를 제공함 : 특징 -> 단순한 문자열 검색과 차별화됨 -> 역색인 방식 사용 -> 토큰화 및 텍스트 분석 -> Ranking(가중치 부여) 및 검색 결과 정렬 2-2. Boolean Query (AND, OR, NOT 연산자 지원) : 여러 개의 검색 조건을 조합하여 더욱 정교한 검색을 수행할 수 있도록 하는 ElasticSearch의 기능임 : 특징 -> 다양한 검색 조건을 조합하여 정확한 검색 결과 제공 -> 복합적인 검색 로직 구현 가능 -> AND, OR, NOT과 같은 논리 연산을 활용하여 필터링 수행 2-3. Wildcard 검색 (?, * 와일드카드 사용 가능) : 특정 패턴에 일치하는 단어를 검색하는 방법으로, ElasticSearch에서 부분 일치 검색을 수행할 때 사용됨 : Wildcard 검색은 검색 성능에 영향을 줄 수 있으므로, 지나치게 광범위한 패턴을 사용하는 것은 권장되지 않음 : 특징 -> 특정 패턴을 포함하는 단어 검색 가능 -> SQL의 LIKE 검색보다 성능이 뛰어남 -> *와 ? 와일드카드 사용 가능 -> ElasticSearch는 기본적으로 대소문자를 구분 -> 대소문자를 구분하지 않으려면 lowercase 필터 필요 2-4. Proximity 검색 (두 단어 사이의 거리를 고려한 검색) : 검색어 간의 거리를 고려하여 검색 결과를 반환하는 방식임 : 두 개 이상의 단어가 특정 거리 내에 존재하는 경우에만 검색 결과를 반환함 2-5. Ranking (TF-IDF, BM25) (검색 결과의 중요도 평가) : 검색 결과에서 문서의 중요도를 평가하여, 사용자가 원하는 정보를 우선적으로 제공하는 기능임 3. 역색인 방식 사용 : 역색인은 단어와 해당 단어가 포함된 문서 ID 목록을 매핑하는 데이터 구조임 4. 유연한 문서 구조 : Lucene은 문서 기반 저장 방식을 사용하며, 각 문서는 필드로 구성됨 : 필드는 여러 유형(String, Integer, Date 등)을 지원 5. 확장 가능성 : 대량의 데이터를 효율적으로 색인 가능 : 멀티스레딩 지원, 빠른 검색 속도 유지 -
ElasticSearch 활용 사례
: 로그 및 모니터링 데이터 분석 (ELK Stack)
: 웹사이트 검색 시스템 (전자상거래, 문서 검색 등)
: 빅데이터 분석 및 머신러닝 기반 데이터 처리
-
ElasticSearch 주요 기능
: 강력한 Full-Text 검색 지원
: 분산 아키텍처를 통한 수평 확장 지원
: 다양한 쿼리 언어(Query DSL) 및 집계 기능 제공
: 실시간 데이터 색인 및 분석 가능
-
ElasticSearch 아키텍처
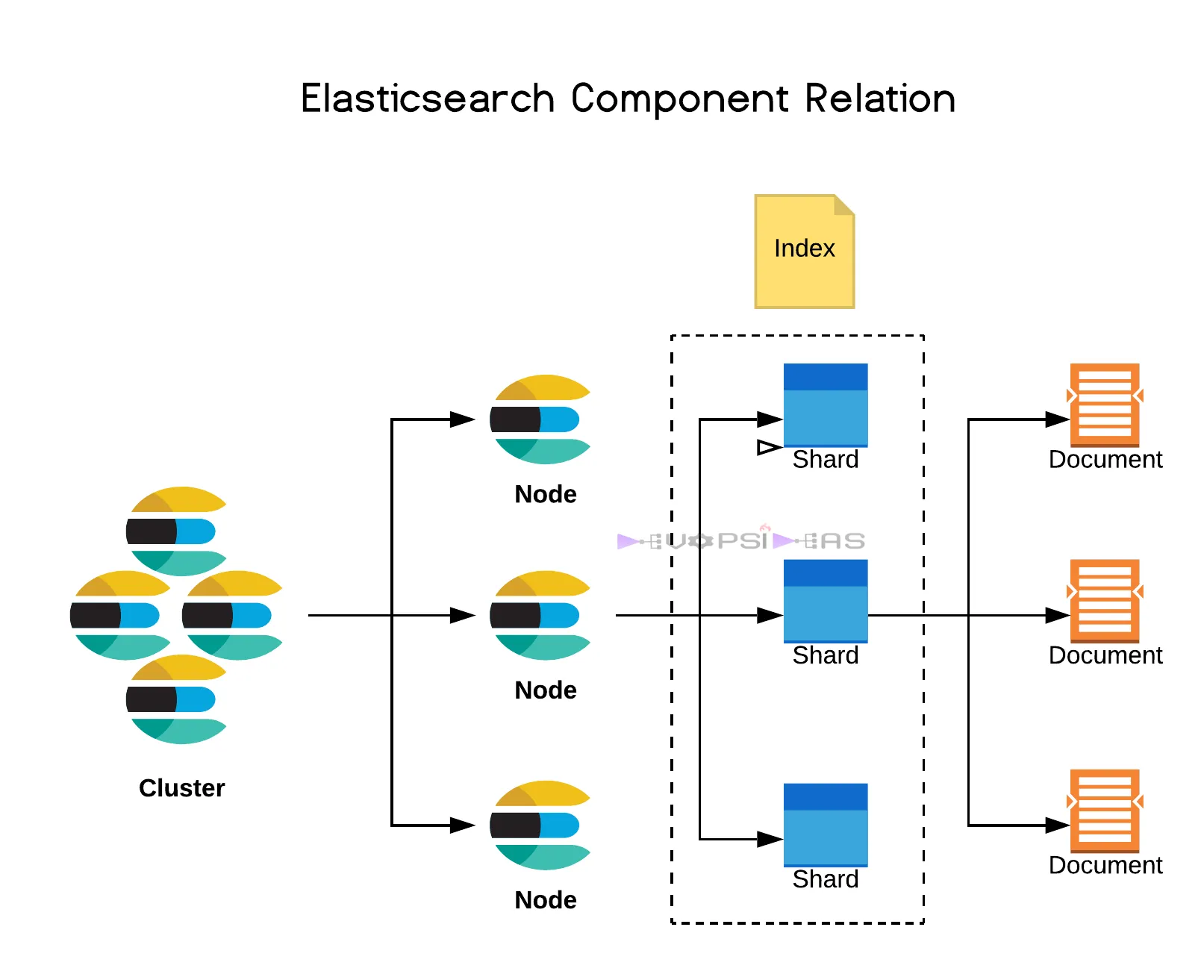
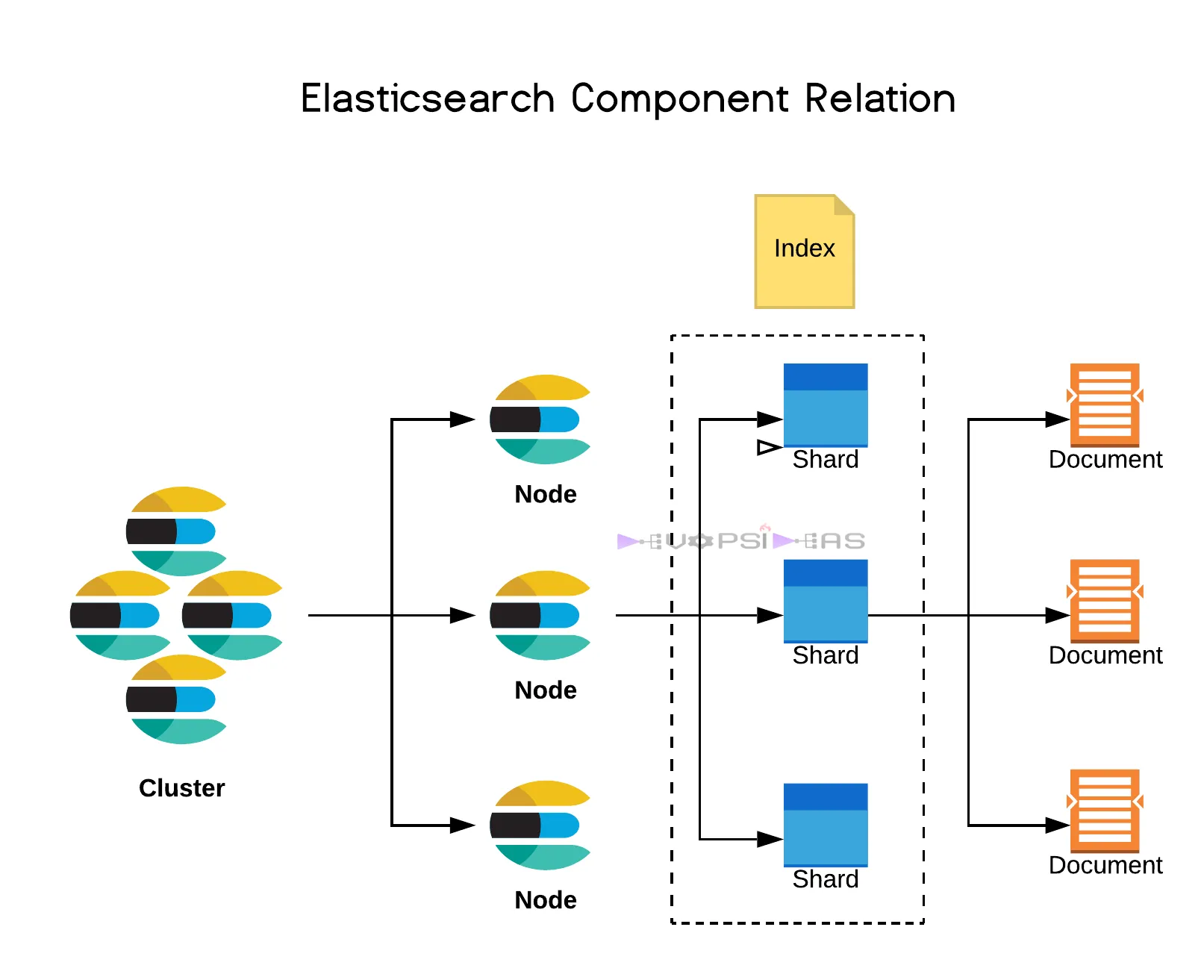
- cluster: 여러 개의 노드로 구성된 ElasticSearch의 전체 시스템
- Node: 클러스터 내에서 데이터를 저장하고 검색 요청을 처리하는 개별 서버
-> Master Node: 클러스터 상태 관리 및 노드 추가/제거 수행
-> Data Node: 데이터 저장 및 검색, 색인 처리 담당
-> Ingest Node: 데이터를 전처리하여 저장하는 역할 수행
-> Coordinator Node: 클라이언트 요청을 받아 데이터 노드로 분배
- Index: 인덱스는 문서의 모음
- Shard와 Replica
-> Shard(샤드):데이터를 분할하여 저장하는 기본 단위
-> Replica(레플리카): 데이터 복제본을 유지하여 고가용성 제공
-> 샤드와 레플리카 개수 조절을 통해 ElasticSearch의 성능 최적화가 가능함cf) 출처: https://devopsideas.com/different-elasticsearch-components-and-what-they-mean-in-5-mins/
-
클러스터 상태
: 클러스터 상태는 세 가지 색상(green, yellow, red)로 표시되며 각 색상은 클러스터의 건강 상태를 나타냄
1)
Green
: 클러스터의 모든 주 샤드와 복제 샤드가 정상적으로 할당되어 있음
: 클러스터가 최적의 상태에 있으며 모든 데이터가 안전하게 복제된 것을 의미함2)
Yellow
: 모든 주 샤드는 할당되었으나 하나 이상의 복제 샤드가 할당되지 않았음
: 주 샤드는 사용 가능하지만, 일부 복제 샤드가 할당되지 않아 데이터의 내고장성이 완벽하지 않은 상태임
: 주 샤드의 노드가 실패할 경우, 해당 데이터의 복제본이 없어 데이터 손실의 가능성이 있음3)
Red
: 하나 이상의 주 샤드가 할당되지 않은 상태임
: 데이터의 일부가 사용 불가능함을 의미하며, 시스템에 문제가 있는 상태임
: 적색 상태에서는 해당 샤드의 데이터에 접근할 수 없으므로 데이터 손실이 발생할 수 있음
- ElasticSearch 구축 방법
1) Docker-Compose 파일 작성
: docker-compose.yml 작성
2) ElasticSearch 및 Kibana 실행
: docker-compose up
3) ElasticSearch 상태 확인
: curl -X GET "http://localhost:9200/_cluster/health?pretty"
- 데이터 인덱싱 및 검색 실습
- 실습 코드 정리한 것 참고
