Intro
앞에서 Decision Tree를 배웠다. Decision Tree는 예측 모델로서 작용하였다. 적은 데이터로도 예측을 할 수 있기에 매우 효과적인 예측 모델이였다. 이러한 트리 기반 모델들은 금융 거래 자료를 분석하는 데 매우 유용하다.
특히 다음과 같은 장점이 존재하는데
1. 입력 데이터의 조정이 필요하지 않다.
2. outlier, missing value, noisy data에 대처하기 좋다.
3. 예측에 영향을 끼치지 않으면서 다른 데이터와의 높은 상호관계를 가지게 된다.
하지만 동시에 많은 제한을 가지게 되는데
1. Decision Tree는 다른 learning method와 비교하여서 정확도가 떨어진다.
2. overfitting한 결론을 낼 가능성이 높다.
하지만 예측한 결과들을 하나로 합침으로써 높은 예측 정확도가 나올 수 있다. 이러한 것을 앙상블(emsembling)이라고 부르는데 우리는 랜덤한 앙상블 방법을 통하여서 overfitting한 결과를 줄이는 과정을 거치게 된 것이다.
Ensemble Methods
이제 Decision tree에서 나온 각 성분들을 weak learners라고 부르고 하나로 합친 모델을 strong lerarner이라고 부른다. 그리고 이렇게 모델들을 합치어 내는 것을 ensembling이라고 부른다.
이때 emsembling을 하기 위해 중요하게 생각해야 할 점은 각각의 성분들은 결코 같지 않다는 것이다. 사실 emsembling의 결과 역시 각 모델이 전혀 다를때 좋은 결론이 나오곤 한다.
그렇다면 어떻게 해서 많고 다양한 tree들을 제작할 수 있을까?

이제 위와 같은 dataset이 있다고 가정하고 다음의 단계를 따르자.
- 새로운 트리마다 기존 dataset에서 행을 기준으로 새로운 dataset을 제작한다.
- 새로운 트리마다 기존 dataset에서 행을 교체한 dataset을 기준으로 새로운 dataset을 제작한다.
- 새로운 트리마다 기존 dataset에서 열을 기준으로 새로운 dataset을 제작한다.
이러한 것을 perturbations(동요=shake up)의 예라고 부른다. 이외에도 다양한 perturbations가 존재할 수 있다. 하나의 예를 들어보면 nth perturbations(n번째 동요)은 이전에 나온 트리를 기반으로 랜덤 트리를 생성한다. 하지만 이번 장에서는 deterministic하고 serial한 방법들 위주로 다루게 될 것이다.
Perturbations on Columns
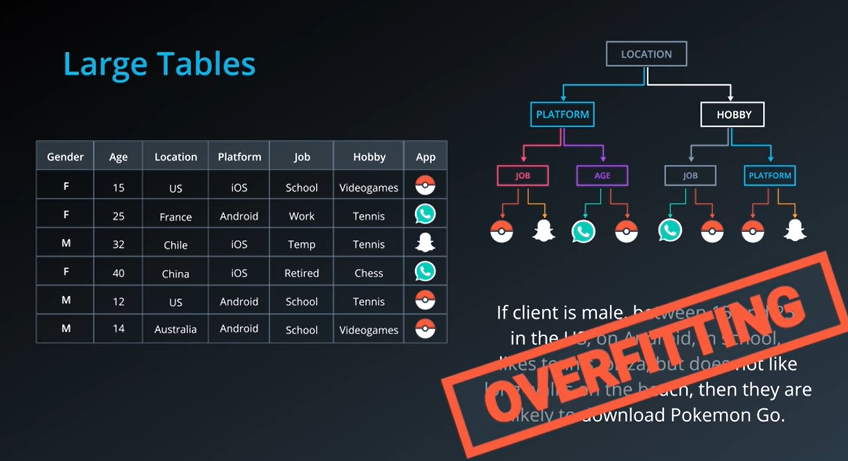
이제 perturbations을 이해하기 위해 위와 같은 거대한 dataset이 존재하고 이와 관련한 트리를 그려보자. 최종적인 결론은 만약 15~25살 사이의 안드로이드를 사용하는 미국 학교를 다니는 미국 남성이라면 테니스, 피자를 좋아하지만 해변위를 걷는 것을 좋아하지 않고 pokemon Go를 다운받기를 좋아한다는 데이터셋의 아래에서 두번째에 있는 내용과 완전히 일치하는 아무의미없는 overfitting이 발생하게 된다.
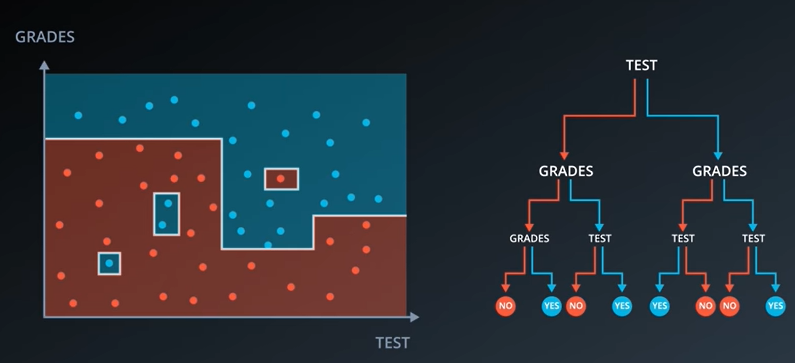
이렇게 되는 이유는 위와 같이 데이터를 분류하는 과정에 있어서 특정한 부분에 위치하는 데이터 값때문에 생기어 나는 결과물이다.
그렇기 때문에 우리는 perturbations을 활용하여 새로운 결론을 도출할 수 있도록 하여야 한다.
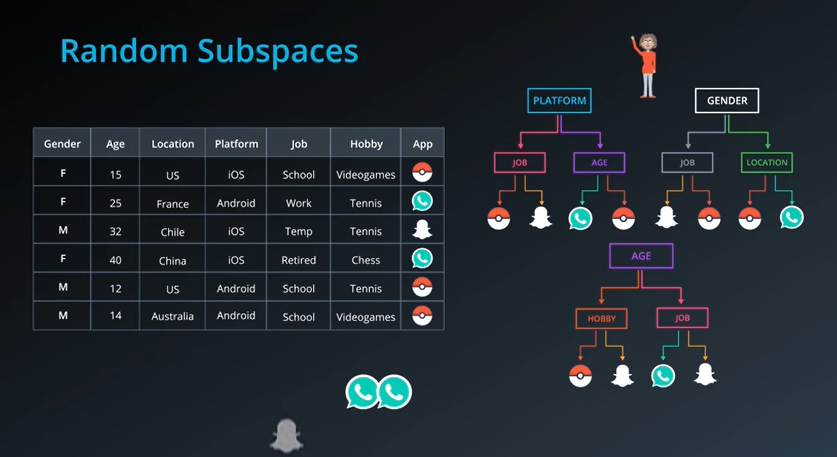
우선 데이터에서 일부 열만을 떼어와서 트리를 제작한다. 그리고 임의의 사람의 데이터를 받아서 이 사람이 과연 어떠한 앱을 깔았는지 모든 트리에 한 번씩 데이터를 삽입하여 보니 스냅쳇, 왓츠앱, 왓츠앱 으로 왓츠앱의 비율이 높기에 왓츠앱을 선택하였을 가능성이 높다고 판정하게 된다.
Perturbations on Rows
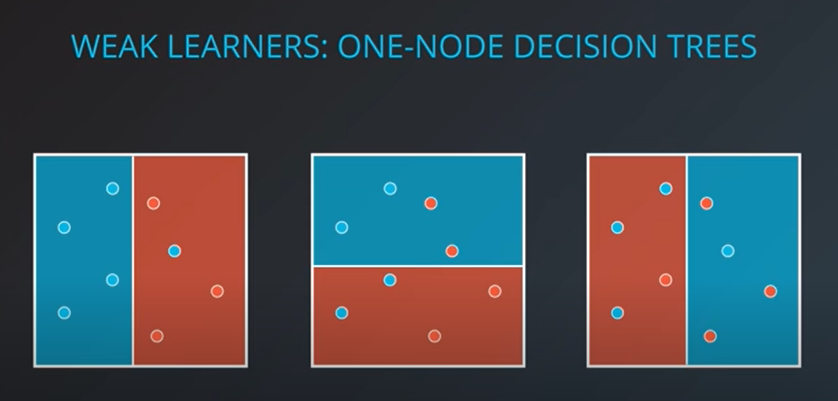
이제 weak learners는 데이터의 영역을 나누었을 때 홀로 존재하는 노드들을 이야기 한다.

우리는 위의 예시를 기준으로 노드의 일부분만을 선택하여 영역을 나누는 과정을 거칠 것이다.
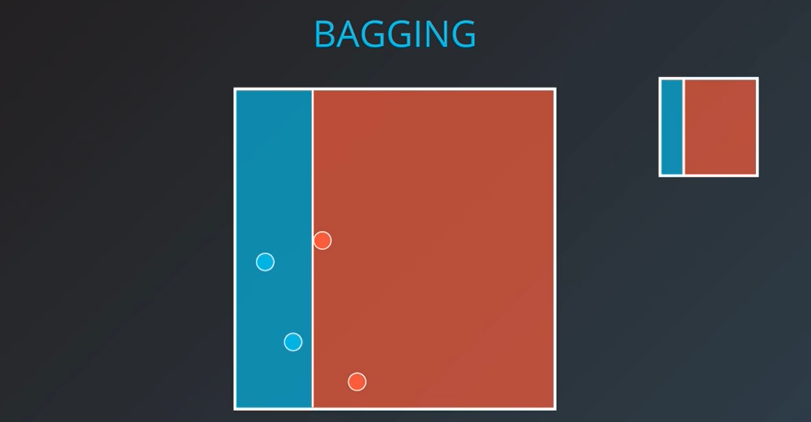 |  | 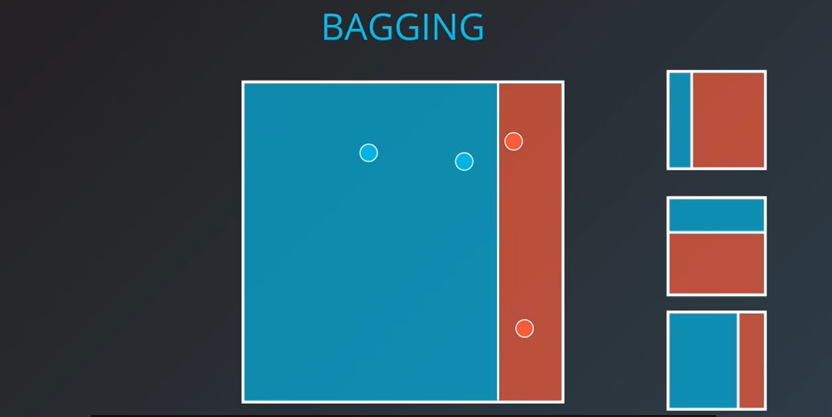 |
|---|
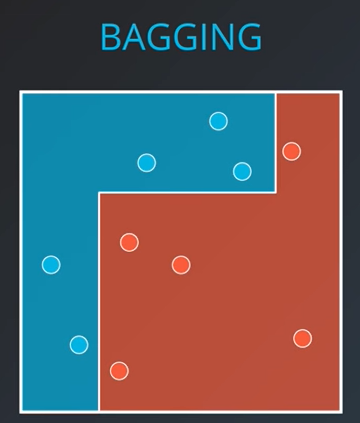
이제 우른 위와 같이 세가지로 나누었다. 이제 세 모델을 하나로 합치어 보자
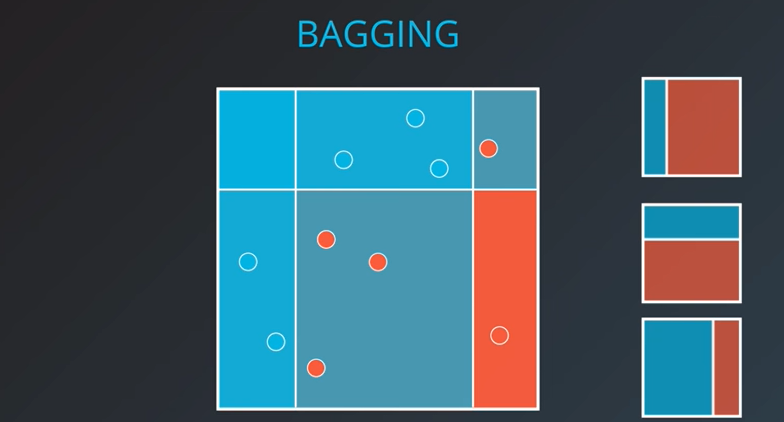
하면 위와 같이 정확하게 파랑 혹은 빨강으로 나뉘어 진 곳도 존재하나 애매하게 색이 겹친 곳도 존재한다. 이러한 색이 겹친 부분을 잘 분리함으로써 다음과 같은 분류 결과를 얻어낼 수 있다.
Forests of Randomized Trees
이제 배우게 될 Random Forest는 행과 열로 나누는 perturbation의 장점을 모두 가지게 된다.
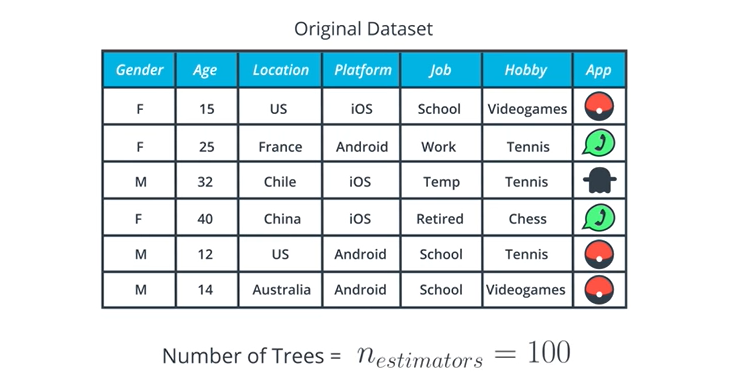
이제 위와 같은 표가 존재한다고 할때 우리가 얻어낼 수 있는 트리의 갯수는 100개가 된다.
첫번쨰로는 랜덤하게 데이터를 뽑아내 보자

이제 보면 위의 tree에서도 중복되는 dataset이 존재하는 것을 확인할 수 있다. 이러한 것을 Bootstrap Sample이라고 부른다.

이제 fully-grow tree가 되면 트리의 성장을 멈춘다.
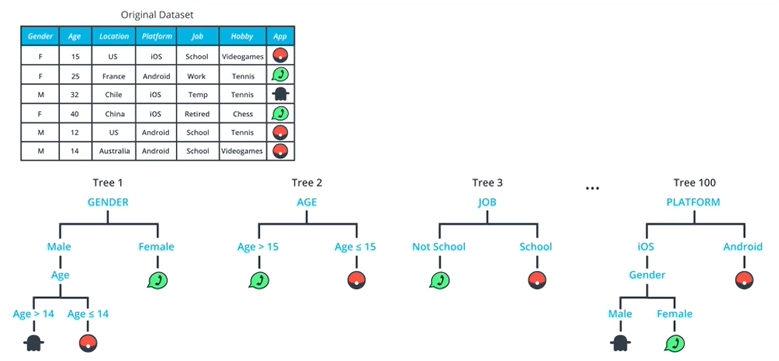
이러한 과정을 반복하여서 Randomized Tree를 제작하자.
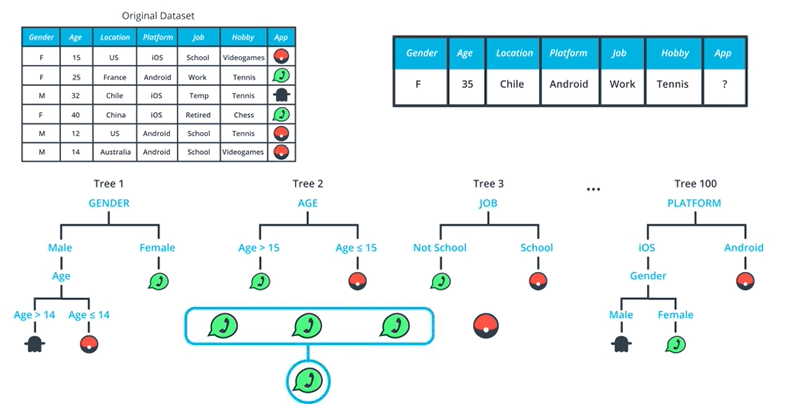
결과적으로 우리는 랜덤한 사람의 데이터를 삽입함으로써 이 사람이 정확히 어떠한 앱을 사용할지를 예측할 수 있다.
The Out-of-Bag Estimate
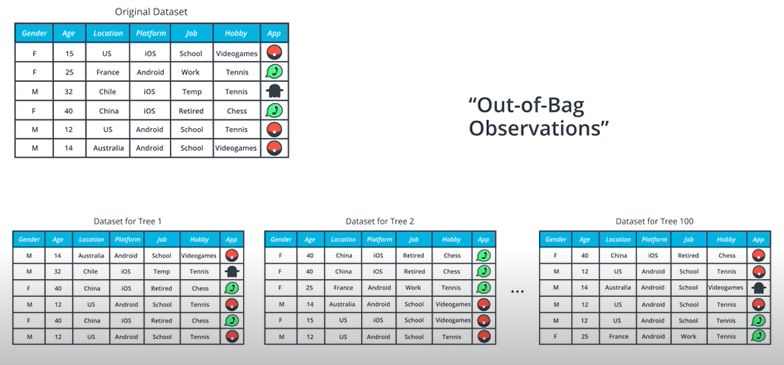
이제 우리가 랜덤하게 데이터를 뽑아 만든 트리에서 확인되지 않는 데이터를 Out-of-Bag Obervation이라고 부른다. 이와 동시에 Out-of-Bag Score을 계산하게 되는데 이는 bag들에서 확인되지 않은 데이터를 모두 합친 값을 이야기 한다.

그래서 만약 B=100 개의 트리가 제작되었다면 대략 1/3 정도의 Out-of-Bag이 발생하게 될 것이다.
이러한 스코어는 tree에서 에러가 얼마나 나왔는지 확인하는 용도로 사용될 수 있다.
Random Forest Hyperparameters
이제 이전에 배운 Random Forest model의 hyperparameter들을 확인하여 보자
min_samples_leaf : leaf 노드를 자르는 최소 경우를 정의한다.
min_samples_split : 매우 적은 트리인 상황에서 더이상의 분리가 가능하지 않게 끔 한다.
max_features : 최대 경우를 제한한다.
n_estimators : 전체 트리의 갯수를 제한한다.
oob_score : True로 설정지 out-of-bag score를 계산한다.
bootstrap : bootstrap samples가 트리를 제작하는데 사용할지를 결정한다.
n_jobs : 병렬 스레드를 가능하게 끔 한다.
Choosing Hyperparameter Values
overfitting을 막기 위해서 Hyperparameter을 어떻게 정하는 것이 좋을까?
우선 non-financial, non-time series한 machine learning에서는 hyperparameter을 간단하게 정해야 한다. 하지만 time-series한 데이터를 가지고 있다면 cross-validation(교차 검증)을 하지 않게 될 것이다.
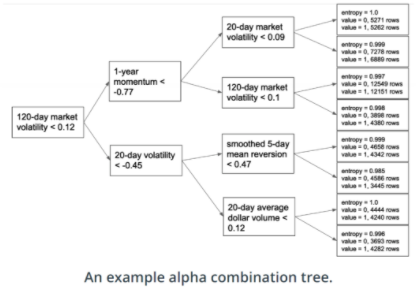
Random Forests for Alpha Combination
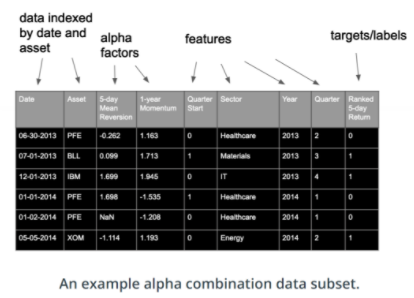
이제 우리가 가지고 있는 데이터는 위와 같이 다양한 date와 asset을 모두 포함하고 있다. 그렇기 때문에 dataset에서 특정 index를 alpha값으로 뽑아서 combination tree를 구성할 수 있다.