[1주차] LIME 논문 리뷰 : “Why Should I Trust You? Explaining the Predictions of Any Classifier"
XAI

본 글은 LIME 논문("Why Should I Trust You?": Explaining the Predictions of Any Classifier 을 참고해 작성하였습니다.
- 해당 글에 첨부된 그림은 모두 위의 논문에서 발췌하였습니다.
- LIME에 관한 개념을 위주로 다루었습니다.
Abstract
- 현재 머신러닝 모델들은 대부분 블랙박스 모델입니다. 신뢰(trust)를 위해 모델 예측의 근거를 이해하는 것은 매우 중요하고, 이는 전체적인 모델의 신뢰도를 판단하는 데에도 사용될 수 있습니다. 해당 논문은 이를 해결하기 위해 모든 classfier의 예측에 대해 적용될 수 있는 LIME 기법을 제안합니다. LIME 기법의 유연성을 보여주기 위해 텍스트 분류와, 이미지 분류를 예시로 제공합니다.
Introduction
여러 의사 결정을 하기 위해 다양한 분야에서 머신 러닝 기법이 활용되기 시작했습니다. 하지만 대부분의 머신러닝 모델은 블랙박스(black box) 모형이기 때문에 모델이 내린 결정에 대해 해석이 어렵다는 치명적인 단점이 존재합니다. 이런 블랙박스 모델에 대해 믿지(trust) 못하는 사용자(user)들은 해당 모델을 사용하지 않을 것입니다. 우선, trust의 두 가지 정의에 대해 구별할 필요가 있을 것 같습니다.
- Trusting a prediction: 사용자(user)가 모델의 예측을 참고하여 행동으로 옮길 만큼 충분히 신뢰하는지.
- 예를 들어, 만약 머신러닝 모델이 의학적인 진단이나 테러 감지에 대해서 판단을 내릴 때, blind faith를 기반해 판단이 내려져선 안된다.
- Trusting a model: 모델이 배포될 경우 모델이 합리적인 방식으로 작동하는 지에 대해 신뢰하는지.
- 모델이 real-world data에 대해서도 정상적으로 작동할 지에 대해서 사용자가 충분히 납득할 수 있어야 합니다.
- 보통 머신러닝 모델은 검증 데이터의 accuracy를 참고해 학습이 진행되는데, real-world data는 이와 괴리가 존재할 수도 있을뿐더러 accuracy를 정하는 방식이 우리의 목표랑 맞지 않을 수도 있습니다.
위의 두 신뢰도는 인간이 모델의 행동(예측)방식에 대해 얼마나 이해하는 지에 따라 영향을 받습니다.
해당 논문에서는 모델의 개별적인 예측에 대한 설명을 제공해 예측을 신뢰할 수 있게 하고(trusting a prediction), 이런 개별적인 예측(또는 설명)을 여러 개 선택해 전체 모델에 대해서도 신뢰할 수 있는(trusting the model) 방법을 제안합니다.
-
LIME : 어떤 분류기(classifier)나, 회귀기(regressor)의 예측에 대해 해석가능한 모델로 (지역적으로) 근사함으로써 설명할 수 있는 알고리즘(trusting a prediction).
-
SP-LIME: 서브모듈러 최적화(submodular optimization)를 통해 설명 가능한 대표적인 예시들을 뽑아 모델을 신뢰할 수 있게끔 하는 방법(trusting the model).
예측에 대해 설명하는 것(‘Explaining a prediction’) 이란 문장 내 단어들 또는 이미지 내 패치 같은 구성요소들과 모델의 예측 사이의 관계를 이해할 수 있는 양질의 시각 정보를 제공하는 것으로 볼 수 있습니다. 예측에 대해 설명하는 것은 인공지능 모델을 신뢰함은 물론, 의사 선생님이 질병 예측에 대해 환자에게 설명을 덧붙이는 것과 같이 효과적으로 머신러닝 모델을 사용할 수 있습니다. 또한 인공지능 모델을 사용하는 사람은 해당 분야에 대해 사전 지식을 가지고 있기 때문에, 인공지능 모델로부터 설명을 받으면 그 설명이 타당한 지, 타당하지 않은 지 판단할 수 있습니다.
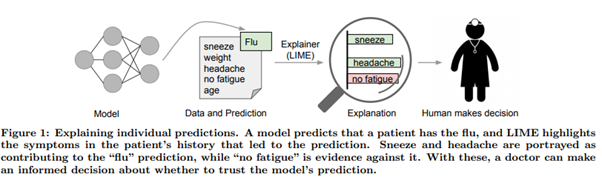
모델은 해당 환자가 감기에 걸렸다고 판단하였고, LIME은 그 판단의 근거가 되는 증상을 하이라이트하는 모습을 보여줍니다.
하지만 현재 머신러닝 모델의 성능을 판단하는 데 쓰이는 기준은 보통 검증 데이터를 이용하곤 하는데, 이는 실제 상황의 데이터에서는 제 성능을 발휘하지 못할 수도 있습니다. 또한, accuracy에 의존해서 신뢰도를 결정하는 것 또한 위험합니다. 아래 그림에서 “Atheism”을 판단하는 근거로 Posting, Host, Re와 같이 전혀 관련이 없는 단어들을 제공한 예시와 같이 단순히 정확성에 의존하는 모델은 신뢰할 수 없다는 것을 알 수 있습니다.

특정 문서가 기독교에 관한 것인지, 무신론에 관한것인지 예측하는 두 개의 분류기. 막대 차트는 그 판단에 가장 관련이 깊은 단어의 중요도를 보여줍니다.
설명자(Explainer)의 바람직한 특성
- Interpretable : 입력과 결과에 대한 질 좋은 설명이 제공되어야 합니다. 사용자의 수준에 맞게 설명이 제공되어야 하며, 비전문가 또한 예측에 대해 쉽게 이해할 수 있어야 합니다.
- Local fidelity : 예측에 대한 설명은 적어도 지역적으로(locally) 신뢰(faithful)되어야 합니다. 즉, 모델이 하나의 데이터에 내린 판단에 대해 설명할 수 있어야 합니다.
- Model-agnostic : 어떠한 모델을 사용하든 설명 가능해야 합니다.
- Global-perspective : 정확도만으로는 모델을 정확하게 평가할 수 없기 때문에, 어느 정도 전체적인 모델에 대한 설명 또한 제공되어야 합니다.
Local Interpretable Model-Agnostic Explanations(LIME)
저희는 위와 같은 ‘설명’을 제공하기 위해 Local Interpretable Model-agnostic Explanations(LIME) 방법을 제안합니다. LIME의 전반적인 목표는 기존의 분류기에 대해 지역적으로 신뢰(locally faithful)를 보이는 해석 가능한 표현(interpretable representation)들을 통해 해석가능한 모델을 정의(식별)하는 것입니다.
해석가능한 데이터 표현
모델을 설명하기 앞서서, 특성(features)과 해석 가능한 표현(interpretable data representations)의 차이를 구별하는 것은 중요합니다. 해석가능한 설명은 보통 모델에 쓰이는 feature와는 관계없이 사람이 이해할 만한 표현을 사용해야 합니다. 예를 들면, 텍스트 모델의 경우 모델은 word embeddings과 같은 복잡한 feature를 사용하지만 인간에게는 ‘단어의 존재 또는 부재’와 같은 간단한 이진 벡터가 제공될 수 있습니다. 이미지 모델에서도 모델은 픽셀 당 RGB 값을 이용한 tensor를 이용하는 반면, 우리는 이미지의 특정 부분(슈퍼 픽셀)과 같은 요소의 ‘존재 또는 부재’를 제공받을 수 있습니다.
식 정의
: 설명되는 데이터에 대한 기존의 표현
: 해석가능한 표현을 위한 이진 벡터
: 평가하려고 하는 모델 가 를 넣었을 때 원하는 에 대한 확률 값
:
- : 해석가능한 모델들의 클래스, ex) linear model,decision tree..
- : 사용자에게 visual or textual 요소를 제공하는 설명 모델. 의 {0,1} 벡터를 정의역으로 하며, 어떤 ‘해석 가능한 요소들’에 대한 ‘존재 또는 부재’로 표현됩니다.
모든 설명 모델 가 해석가능 할 만큼 간단하지는 않기 때문에, 를 설명 모델 의 복잡성 측정(measure of complexity)라 하고, 해석가능성(interpretability)와 반대되는 개념으로 정의합니다. 예를 들어, 결정 트리에서 트리의 깊이나, 선형 모델에서 가중치의 개수가 될 수 있습니다.
설명의 대상이 되는 모델을 이라 합시다. 즉, 분류에서는 : ’특정 class에 속할 확률’ 이 됩니다. 또한, 예시(instance) 와 사이의 유사성 척도로 를 사용합니다. 결론적으로, 를 로 정의되는 지역성(locality) 하에서 ‘가 로 근사하는 데 있어서 얼마나 믿음직스럽지 못한가’를 측정하는 척도로 사용할 수 있습니다.
우리는 해석가능성(interpretability)과 지역적 신뢰도(local fidelity) 두 가지를 보장하기 위해 복잡성인 를 인간이 해석가능 할 정도로 최대한 낮추면서, 를 최소화 해야 합니다.
결국, LIME이 생성하는 설명은 아래와 같은 식으로 얻어집니다.
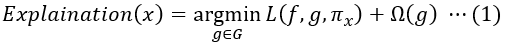 위에 사용되는 는 각각 모두 다른 신뢰 함수(fidelity function), 설명족(explanation family) 그리고 복잡성 척도(complexity measures)가 쓰일 수 있습니다. 우리는 본 논문에서 간섭(perturbation)을 사용한 탐색과, 설명 모델로서 희소 선형 모델(sparse linear model)을 중점으로 설명하겠습니다.
위에 사용되는 는 각각 모두 다른 신뢰 함수(fidelity function), 설명족(explanation family) 그리고 복잡성 척도(complexity measures)가 쓰일 수 있습니다. 우리는 본 논문에서 간섭(perturbation)을 사용한 탐색과, 설명 모델로서 희소 선형 모델(sparse linear model)을 중점으로 설명하겠습니다.
지역 탐색을 위한 샘플링.
우리는 모델-애그노스틱 한 설명 모델을 원하기 때문에, f에 대한 어떠한 가정도 하지 않고 지역인식 손실(locality-aware loss)인 를 최소화하고 싶습니다. 따라서 입력 데이터가 변하는 와중에 의 지역적(부분적)인 행동을 학습하기 위해서 가중치 를 사용, 샘플들을 뽑고 싶습니다.
그를 위해 의 원소 중 이 아닌 원소들을 무작위로 뽑아서 주변의 값을 샘플링합니다. 의 원소들 내 무작위 적인 조합을 포함하는 간섭 샘플 로부터, 기존의 표현인 샘플을 복원해 를 얻습니다. 여기서 얻어진 는 설명 모델 를 위한 로 쓰입니다. 을 가지고 있는 이러한 간섭 샘플 데이터 세트 가 주어질 때, 우리는 을 얻기 위해 방정식 (1)을 최소화해야 합니다.
뒤에 있는 주된 직관은 아래의 그림으로 나타납니다. 아래 그림에서 우리는 데이터들을 근처(때문에 가중치가 높은)에서도 뽑고, 와 먼 곳(가중치가 낮은)에서도 뽑습니다. LIME은 입력 데이터 (red cross) 주변의 데이터를 샘플링하고, 샘플링 데이터를 를 사용해 예측한 뒤 유사도에 따라 가중치를 부여합니다(틀리게 예측한다면 그만큼 가중치는 적게 주기 때문에 loss에 영향을 덜 끼친다). 아래의 푸른색 원의 크기가 가중치의 크기입니다.
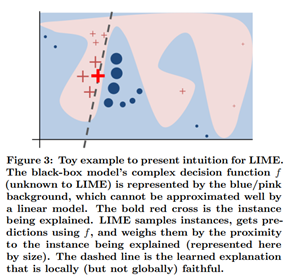
기존의 분류 모델이 전역적으로 설명하기에 너무 복잡할지라도, LIME은 지역적으로(즉, 한 데이터에 한해서) 신뢰가 가는 설명을 제공합니다. 그런 지역성은 로 나타납니다. 우리의 샘플들은 에 의해 가중치가 부여되기 때문에 노이즈(여기서 )를 샘플링하기에 꽤나 robust하다고 할 수 있습니다.
Sparse Linaer Explanations
본 논문의 나머지 파트에서는 G를 linear model들로 가정합니다. 즉, 에서, 를 만족하는 집합입니다. 우리는 아래와 같은 locally weighted square loss를 로 사용합니다.
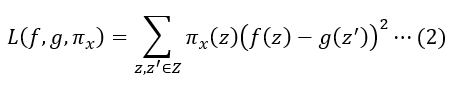
이 때, 인 width가 인 exponential kernel을 사용하고, 는 특정한 거리 함수(distance function,텍스트에는 코사인 거리,이미지에는 L2거리 등)이 됩니다. 위에서 는 샘플링 된 값들이라고 볼 수 있습니다.
참고 : Kernel이란?
보통 비선형 문제를 풀기 위해 비선형을 선형 문제로 변환시켜야 되는 상황이 많습니다. 하지만 적당한 변환 함수를 찾기는 쉽지 않기 때문에 변환하지 않고 비선형 문제를 해결하는 방법이 필요합니다. 이러한 방법들 중 하나로, (선형)Z 공간에서 특정 가설 G를 구하기 위해서는 선형식 z를 직접 구하지 않고 z간의 내적만 뽑아내 사용하는 방법이 있습니다. 이런 내적을 구하는 식(즉, 커널함수)은 다항 커널, 가우시안 커널, 지수형 커널 등이 있습니다. 위에서 쓰인 지수형 커널(exponential kernel)은 가우시안 커널에서 제곱만 빠진 형태로, 서로간의 방향은 상관 없는 완전 거리 기반 방사형 커널입니다. sigma가 높아지면 결과가 데이터 간의 거리에 상관 없이 1에 가까워질 것이고, 고차원의 정사영은 비선형의 힘을 잃을 것입니다. 만약 sigma가 작아진다면 값이 지수적으로 커져버리기 때문에 regularization를 잃어버릴 것이고, 결정 경계는 학습 데이터의 노이즈에 너무 민감해질 것입니다.
텍스트 분류에서는 해석가능한 표현(interpretable representation)으로 단어 가방(A bag of words, 순서를 고려하지 않은 단어 묶음)으로 설정함으로써 설명 가능할 것입니다. 이 때 단어 가방에 몇 개의 단어를 담을 지는 사용자의 몫이며, 많은 단어를 담는다면 필연적으로 모델은 복잡해질 것입니다().
이미지 분류에서는 해석가능한 표현으로 픽셀 간 비슷한 정보를 담고 있는 슈퍼 픽셀(Super-pixel)을 사용할 것입니다. 그로부터 이미지의 해석가능한 표현은 슈퍼 픽셀이 켜지거나, 꺼지는 이진 분류로서 나타날 것입니다.
우리는 로 불리는 과정(Lasso를 이용해 K feature를 선택하고, 제곱합을 통해 가중치를 학습하는)을 사용하기 때문에 Loss 방정식(1)을 근사적으로 풀 것입니다. 직접적으로는 거의 풀 수가 없습니다.
아래와 같은 K-LASSO 알고리즘은 한 데이터에 대한 설명을 내포하기 때문에 데이터세트가 얼마나 크든지 복잡도에 영향을 받지 않으며, 그렇기 때문에 비교적 간단하다고 할 수 있습니다. 대신 를 계산하고, 개수인 N에는 복잡도가 영향을 받을 것입니다.
일반적으로, 1000 tree, N=5000인 결정 트리에서는 3초 미만, Inception network에서의 이미지 분류는 10분정도 걸렸습니다.

어떤 방식으로 해석 가능한 표현과 해석 모델 G를 고르든, 단점은 분명히 존재할 것입니다.
- 기존의 분류 모델이 블랙박스 모델일지라도 특정한 해석 가능한 표현은 어떤 행동을 설명할 정도로 강하지 못할 수도 있습니다.
- 예를 들면, sepia-toned의 이미지를 retro-toned로 오판하는 것은 슈퍼 픽셀의 부재로 설명될 수가 없습니다(색조의 문제).
- 우리가 로 선택한 Sparse linear model은, 만약 기존의 분류 모델이 지역적으로도 ‘매우 비선형’적이라면 지역적인 선형을 가정한 linear model로는 신뢰도 높은 설명을 할 수 없을 것입니다.
하지만, LIME 모델은 예측을 잘 설명하는 최고의 간섭 샘플만 사용할 수 있는 게 아니라, 특정 데이터 근처의 다양한 샘플들()에 대해서도 설명을 제공할 수 있습니다. 그렇기 때문에 적절한 설명 집합()을 선택할 수 있고, 주어진 데이터 세트와 분류기에도 맞출 수 있게 됩니다. 해석가능 모델을 선형모델로 택했을 때에도 여러 블랙박스 모델에 잘 작동하였습니다.

흠터레스팅