InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Paper Reviews
Abstract
- 최근 몇년간 large-scale vision transformer(ViT)의 연구에 큰 진전이 있었으나, CNN 기반 large-scale model은 초기 상태에 머뭄
- InternImage
- 새로운 large-scale CNN-based foundation model
- 증가된 파라미터로부터 이득(gain)을 얻으며 Vision Transformer (ViT) 처럼 학습 가능한 모델
- 최근 CNN 모델이 초점으로 한 large dense kernel과 달리 deformable convolution을 핵심 연산자로 사용하기 때문에 큰 receptive field를 가짐
- input과 task information에 따라 조절되는 adaptive spatial aggregation을 가짐
- 기존의 CNN의 strict inductive bias를 줄일 수 있으며, ViT 모델처럼 대용량 데이터에서 대규모 매개변수로 robust한 패턴을 학습
Inductive Bias
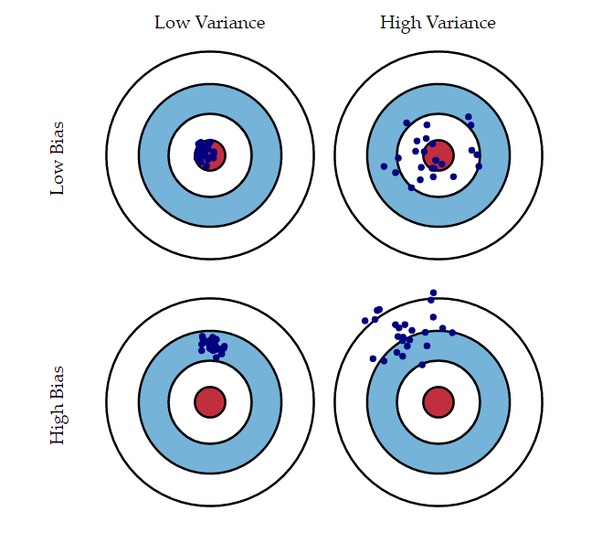
- Bias (편향)
- 실제값과 예측값이 얼마나 멀리 떨어져 있는가를 의미
- Bias가 높은 경우 데이터로부터 타겟과의 연관성을 잘 찾아내지 못하는 underfitting이 발생
- Variance (분산)
- 예측값들이 얼마나 퍼져있는가를 의미하며, 예측 모델의 복잡도라고 해석할 수 있음
- Variance가 높은 경우 훈련 데이터에 지나치게 적합을 시켜 데이터의 사소한 노이즈나 랜덤한 부분까지 민감하게 고려하는 overfitting이 발생
- Brittle, Spurious
- 일반적으로 모델이 갖는 일반화 문제로는 모델이 brittle(불안정)하다는 것과, spurious(겉으로만 그럴싸)하다는 것이 있음
- Brittle : 데이터의 input이 조금만 바뀌어도 모델의 결과가 망가짐
- Spurious : 데이터 본연의 의미를 학습하는 것이 아닌 결과와 편향을 학습
- Inductive bias (귀납 편향)
- 일반화 문제들을 해결하기 위해 inductive bias를 이용
Inductive bias란, 학습시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정 (additional assumptions)Translation invariance: 어떠한 사물이 들어 있는 이미지를 제공해줄 때 사물의 위치가 바뀌어도 해당 사물을 인식할 수 있음
-
Translation Equivariance: 어떠한 사물이 들어 있는 이미지를 제공해줄 때 사물의 위치가 바뀌면 CNN과 같은 연산의 activation 위치 또한 바뀜 -
Maximum conditional independence: 가설이 베이지안 프레임워크에 캐스팅될 수 있다면 조건부 독립성을 극대화 -
Minimum cross-validation error: 가설 중에서 선택하려고 할 때 교차 검증 오차가 가장 낮은 가설을 선택 -
Maximum margin: 두 클래스 사이에 경계를 그릴 때 경계 너비를 최대화 -
Minimum description length: 가설을 구성할 때 가설의 설명 길이를 최소화합니다. 이는 더 간단한 가설은 더 사실일 가능성이 높다는 가정을 기반으로 하고 있음 -
Minimum features: 특정 피쳐가 유용하다는 근거가 없는 한 삭제해야 함 -
Nearest neighbors: 특징 공간에 있는 작은 이웃의 경우 대부분이 동일한 클래스에 속한다고 가정
Introduction
-
Large-scale language model에서 transformer의 성공과 함께 Vision Transformer (ViT)는 large-scale vision foundation model의 연구에 중요한 선택지가 되었음
-
매우 큰 모델로 확장된 ViT 연구들은 computer vision에서 CNN을 뛰어넘는 성능을 보여주었으며, 대용량 파라미터와 데이터를 사용하는 분야에서 ViT가 CNN 보다 뛰어나다고 주장
-
본 논문에서는 CNN-based foundation model이 ViT와 유사한 operator-architecture level design, scaling-up parameter, massive data를 갖추었을 때 ViT 이상의 성능을 보여줄 수 있다고 주장
Operator-Architecture Level Design
- Vision Transformer (ViT)
이미지의 spatial 정보를 유지하기 위해 attention 메커니즘을 조정하여 설계
ViT는 이미지를 16x16 픽셀 크기의 patch로 분할하고, 각 patch에 대해 transformer를 사용하여 attention을 계산
모든 patch의 attention결과를 결합하여 최종 이미지를 인식
- ViT의 operator-architecture level design 장점
이미지의 spatial 정보를 유지할 수 있음
CNN보다 강력한 표현력을 가지고 있으며, 더 효율적으로 학습 가능
Gap Between CNNs and ViTs
Long-Range Dependence
입력데이터의 서로 다른 위치의 정보가 서로 연관되어 있는 것을 의미
예를 들어, 이미지에서 개를 인식하려면 개가 있는 위치의 정보 뿐만 아니라 개가 있는 위치 주변의 정보도 필요
Adaptive Spatial Aggregation
이미지의 특정 영역의 중요도를 계산하고, 그 중요도에 따라 해당 영역의 정보를 계산하는 방법으로 이미지의 공간적 정보를 보다 정확하게 계산할 수 있으므로, 딥러닝 모델의 성능을 향상시킬 수 있음
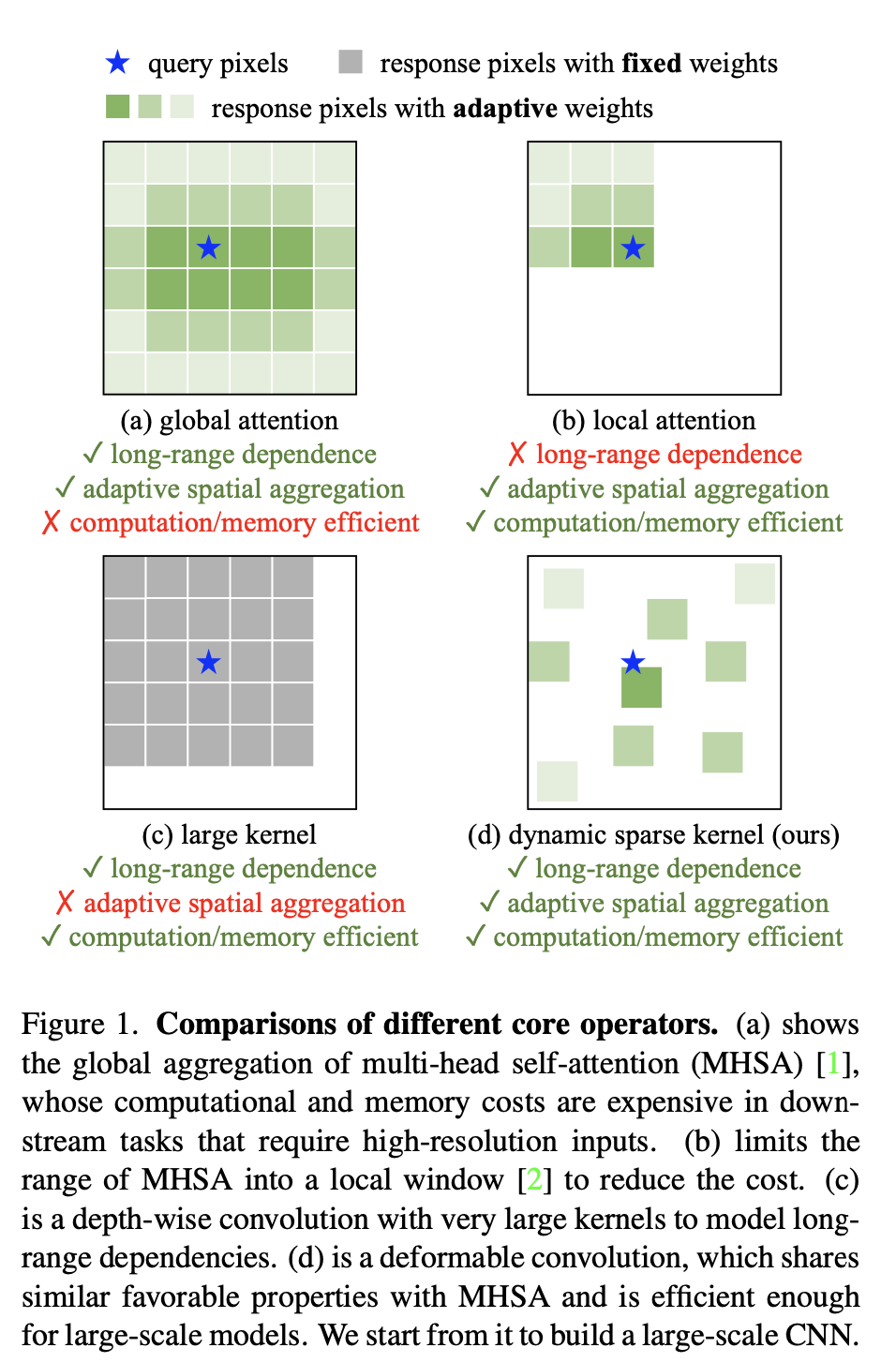
- Operator level
ViT의 Multi-Head Self-Attention (MHSA)는 long-range dependence와 adaptive spatial aggregation을 가짐
MHSA 덕분에, ViT는 CNN 보다 대용량 데이터로부터 강력하고 강인한 패턴을 학습할 수 있음
- Architecture view, besides MHSA
ViT는 기초적인 CNN과 달리 Layer Normalization (LN), Feed-Forward Network (FFN), GELU 등 고등적인 요소를 포함하고 있음
비록 최근에는 large kernel과 함께 dense convolution를 사용하여 CNN에서도 long-range dependence를 가지기 위한 연구가 이루어져왔으나, large-scale ViT와 비교했을 때 성능과 모델 크기 측면에서 큰 차이가 있음
Layer Normalization (LN)
- Normalization (정규화)
모든 데이터를 같은 정도의 스케일로 변경
- Min-max normalization
- Standardization
모든 데이터를 평균 0, 표준편차 1의 값을 같는 스케일로 변경
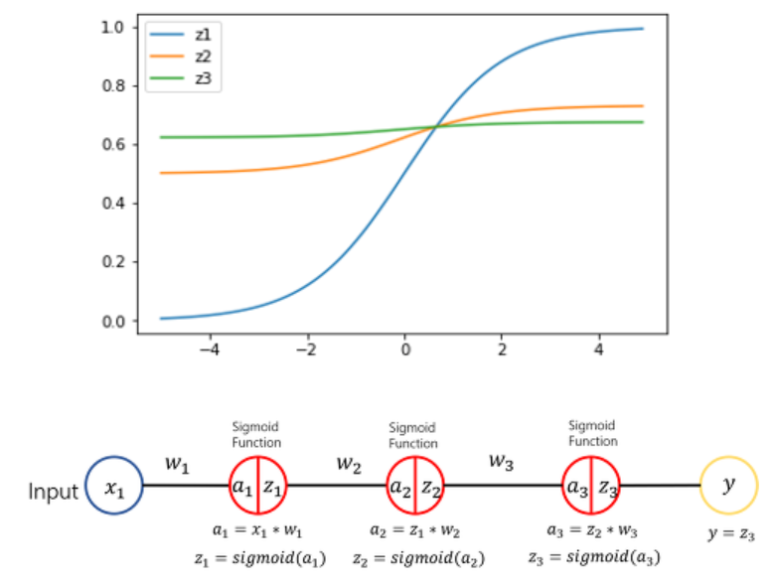
- Standardization을 사용할 경우 bias가 없어져 학습 가능한 파라미터의 영향이 사라지므로 제대로 학습이 불가능
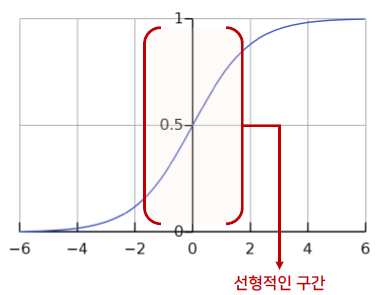
- 평균 0, 표준 편차 1로 데이터의 분포를 변환하게 될 경우 활성 함수로 sigmoid를 사용하게 되었을 때 비선형성의 특징을 잃어버림
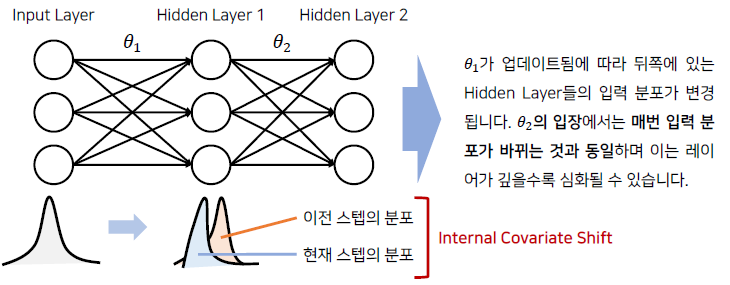
- Internal Covariate Shift
- 매 스텝마다 hidden layer에 입력으로 들어오는 데이터의 분포가 달라지는 현상
- 평균이 0인 분포를 가진 데이터를 입력으로 주었을 때, Sigmoid 함수를 거치면 데이터의 분포를 평균이 0.5인 분포로 변환하는 것으로 이해할 수 있음
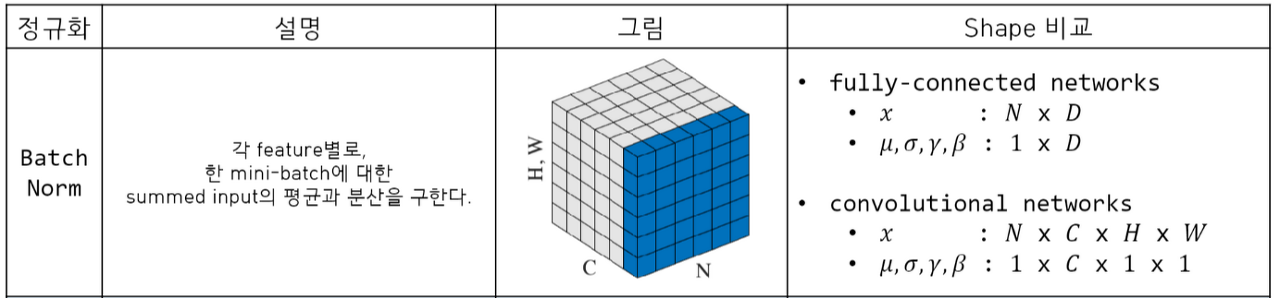
- Batch Normalization
Internal covariate shift를 해결하기 위해 등장
Normalization 된 값들에 대해 Scale factor()와 Shift factor()를 더하여 학습이 가능한 파라미터를 추가


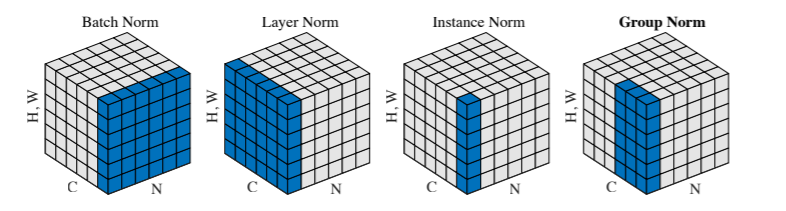
- In CNNs
- Batch Normalization
Mini-batch의 channel 별로 평균과 분산을 구함
batch size가 1일때 분산 크기가 0이 되어 학습되지 않음
RNN model에서는 각 시점마다 다른 데이터가 연속적으로 나오기 때문에 배치 정규화를 적용하기 어려움
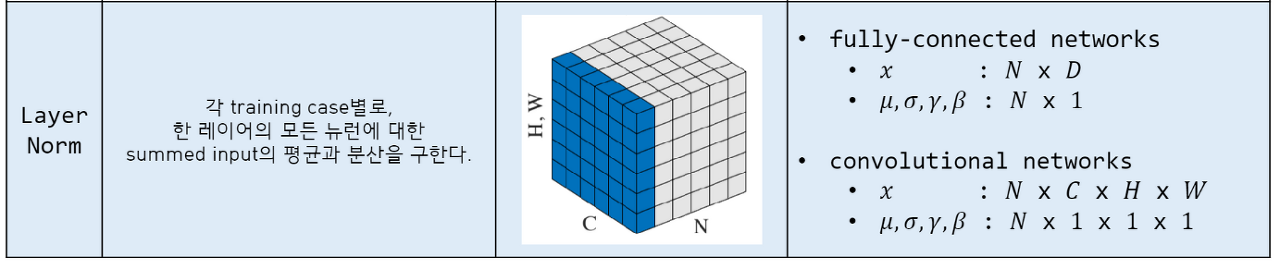
- Layer Normalization
Mini-batch의 데이터 별로 평균과 분산을 구함
Batch normalization이 가지고 있던 batch에 대한 의존도 제거
Batch가 아닌 layer를 기반으로 normalization 수행
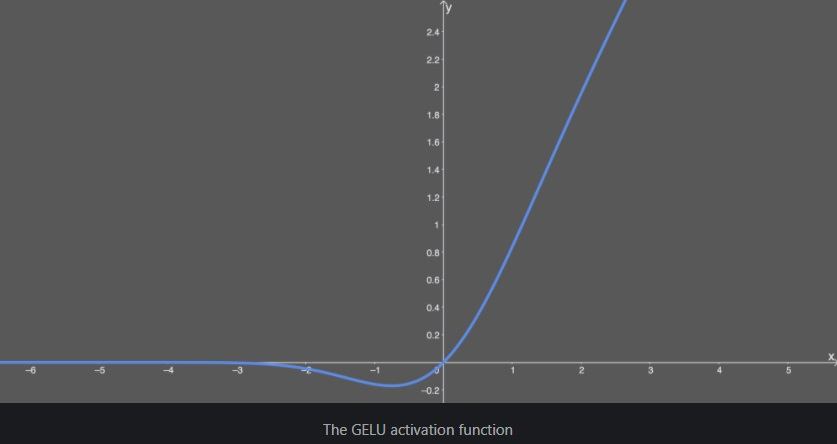
GELU (Gaussian Error Linear Unit)
- dropout, zoneout, ReLU 함수의 특성을 조합하여 유도된 함수
- ReLU : 입력 x의 부호에 따라 1이나 0을 deterministic하게 곱함
- dropout : 1이나 0을 stochastic하게 곱함
- GELU
- x에 0 또는 1로 이루어진 마스크를 stochastic하게 곱하면서도 stochasticity를 x의 부호가 아닌 값에 의해서 정하고자 함
- 하지만 neural networks 활성화 함수로 사용되기 위해서는 deterministic 함수를 원함
- Equation
- 장점
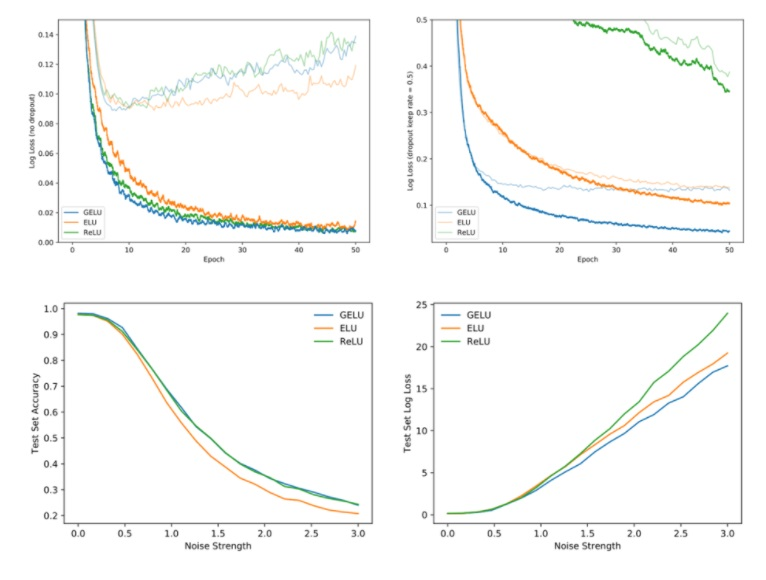
- ReLU, ELU 등의 타 활성화 함수보다 빠르게 수렴, 낮은 오차를 보여준다
Reference
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.
