[논문 리뷰] BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
Paper Reviews
Abstract
- 최근 센서 융합 3D 객체 검출은 point-level fusion을 기반
- 이 논문에서는 geometric, semantic 정보를 보존할 수 있으며, LiDAR, Camera 데이터 형식이 공유 가능한 BEV representation space에 multi-modal features를 통합하여 point-level fusion의 한계를 해결하고자 함
- 최적화된 BEV pooling을 제안하여 view transformation의 효율을 향상시켰음
- nuScenes 3D object detection benchmark에서 mAP과 NDS를 1.3% 향상시켰으며, BEV map segmentation에서 mIoU를 13.6% 향상시켰음
- github-code
- 모델을 실행시켜보려고 하였으나 2080ti 11g로는 lidar+camera 센서 융합은 커녕 lidar-only detector 학습시키는데 6일 걸리는 것을 보고 포기하기로 하였음 ㅠㅠ
- 저자는 vram 48g 그래픽카드를 사용하였으며 최소 24g는 요구된다고 하였으므로 혹시 해보고 싶은 사람은 참고바랍니다. (추후에는 24g 이하의 그래픽카드로도 학습 가능하게 한다 하였으나 현재는 batch size를 2로 해도 학습이 안됨)
Related Work

LiDAR-Based 3D Perception
- Single-stage 3D object detection
LiDAR 포인트 클라우드로부터 PointNet, SaprseConvNet 등을 사용하여 평탄화된 포인트 클라우드 feature를 추출하고 BEV space에서 detection 수행
- Anchor-free 3D object detection
One-stage object detector에 RCNN network 추가
- U-Net like 3D semantic segmentiation model
- Two-stage object detection
Camera-Based 3D Perception
- LiDAR 센서의 높은 비용으로 camera-only 3D perception을 연구
- FOCOS3D
Image detector에 3D regression braches를 추가하여 depth perception 수행
- DETR3D, PETR, Graph-DETR3D
DETR을 기반으로 한 oject detection head를 설계하고, 3D 공간에서 학습 가능한 object query를 사용- DETR
각 object query가 2D 이미지 feature과 상호작용하면서 2D 객체 검출을 수행하는 방식
- DETR
- BEVDet, M2BEV
LSS와 OFT를 3D object detection에 적용
카메라 이미지 feature를 LiDAR point cloud에 투영하고 이를 BEV representation으로 변환하여 3D object detection 수행
BEVDet은 이미지 feature의 depth 정보를 LiDAR 포인트에서 추정하고, M2BEV는 카메라 광선 방향으로 균일한 깊이 분포를 가정
- CaDNN
View transformer를 사용하여 카메라 이미지 feature를 LiDAR point cloud에 투영하고, 이를 BEV representation으로 변환하여 3D object detectiondmf tngod
View transformer의 출력에 depth estimation supervision을 추가하여 정확도 향상- View transformer
이미지 특징과 3D 좌표를 입력으로 받아서 이미지 특징을 3D 좌표에 따라서 재배치 하는 모듈
- View transformer
- BEVFormer, CVT, Ego3RT
Multi-head attention을 사용하여 view transformer 수행
- BEVDet4D, BEVFormer, PETRv2
Multi-camera의 temporal cue를 사용하여 3D object detection 수행
Temporal cue
- 시간적 정보를 의미하며, object detection에서는 주로 이전 프레임과 현재 프레임의 이미지나 feature를 비교하여 물체의 움직임이나 속도를 추정
- Temporal cue를 활용하면 단일 프레임 데이터만 사용하는 방법보다 더 많은 정보를 얻을 수 있음
Multi-Sensor Fusion
LiDAR-to-Camera Projection
- 2D perception은 기존의 많은 연구에서 다뤄졌기때문에 초기에는 LiDAR 포인트 클라우드를 카메라 이미지에 투영한 RGB-D를 2D CNN를 사용하여 처리하는데 초점을 둠
- 하지만 LiDAR 포인트 클라우드를 카메라 평면에 투영하여 2.5D sparse depth로 변환하는 LiDAR-to-Camera projection은 geometric distortion이 발생
- Depth map에서 인접한 두 픽셀이 3D 공간에서는 멀리 떨어져 있을 수 있으므로, 카메라 시점은 3D object detection과 같이 물체나 장면의 기하학적 특성이 중요한 작업에 부적합
Camera-to-LiDAR Projection (Point-Level Fusion)
- 최근 센서 융합 분야에서는 LiDAR 포인트 클라우드를 2D 이미지에서 추출한 semantic label, CNN feature 혹은 가상 포인트와 함께 augmentation을 하고 기존의 LiDAR-based detector을 사용하여 3D bounding box를 검출
- 카메라 이미지의 semantic features를 LiDAR 포인트 클라우드의 foreground에 칠하는 방법으로 LiDAR 기반 객체 검출을 수행
- camera-to-LiDAR projection은 각 데이터 형식의 semantic density의 차이로 인해 semantic feature의 손실이 있으며, 따라서 BEV map segmentation과 같은 semantic-oriented 작업에 부적합
- 32 채널 LiDAR 스캐너를 사용할 경우 오직 5%의 이미지 특징점만이 LiDAR 포인트에 매치되며 나머지는 손실
- Object-centric, geometric-centric 작업에 적용 가능
- LiDAR input-level decoration
AutoAlign, FocalSparseCNN, PointPainting, PointAugmenting, MVP, FusionPainting
- LiDAR feature-level decoration
DeepContinuousFusion, DeepFusion
Proposal-Level Fusion
- Proposal-level fusion은 object-centric method 이며 BEV map segmentation과 같은 다른 작업에 적용되기 어려움
- MV3D
3D space에서 object proposal를 생성한뒤, 이미지에 투영하여 RoI feature를 추출
- F-PointNet, F-ConvNet, CenterFusion
RGB 이미지에서 2D proposal을 구한 뒤 3D frustum으로 변환
Frustum 내부의 점들로부터 객체를 포함하는 지역적인 점들을 그룹화하여 특징을 추출한 뒤 3D 공간에서 객체의 방향이 있는 bounding box 예측
- FUTR3D, TransFusion
3D space에서 object query를 정의하고, 2D proposal의 이미지 feature과 융합
Method

- 주어진 multi-modal inputs에 대해 modality-specific encoder를 사용하여 feature 추출
- Multi-modal features를 unified BEV representation으로 변환
(제안된 BEV representation은 Geometric, semantic 정보를 유지할 수 있기 때문에 대부분의 3D perception 작업에 적용 가능) - Convolution-based BEV encoder를 사용하여 두 데이터 형식의 unified BEV features의 local misalignment를 완화시킴
- Task-specific heads를 추가하여 여러 3D 작업 수행
Unified Representation
View Discrepancy
- 다른 형식의 데이터 feature는 서로 다른 view에서 존재
- Camera feature : perspective view
- LiDAR/radar feature : 3D/BEV view
- 또한 카메라 feature은 각각 서로 다른 viewing angle (front, back, left, right)를 가질 수 있음
- 다른 view에서는 같은 element가 완전히 다른 공간 위치에 대응할 수 있기 때문에, 특정 텐서를 단순히 요소별로 융합하는 것은 효과가 없음
모든 센서 features가 정보 손실 없이 변환되기 쉽고 다양한 타입의 작업에 적용가능한 shared representation을 찾는 것이 중요
To Bird's-Eye View
- 본 논문에서 채용한 방법으로 BEV view를 센서 융합을 위한 unified representation으로 사용
- 출력 또한 BEV 영역이기 때문에 대부분의 perception 작업에 적용 가능
- BEV 영역으로 변환하는 것은 geometric structure (from LiDAR features)과 semantic density (from camera features)를 유지할 수 있음
- LiDAR-to-BEV projection
Sparse LiDAR feature를 z-dimension을 따라 flatten하기때문에 geometric distortion이 발생하지 않음 - Camera-to-BEV projection
카메라 feature pixel을 3D 공간에서의 광선(ray)으로 되돌리고 카메라의 semantic 정보를 완전히 보존하는 dense BEV feature map을 생성
- LiDAR-to-BEV projection
Efficient Camera-to-BEV Transformation
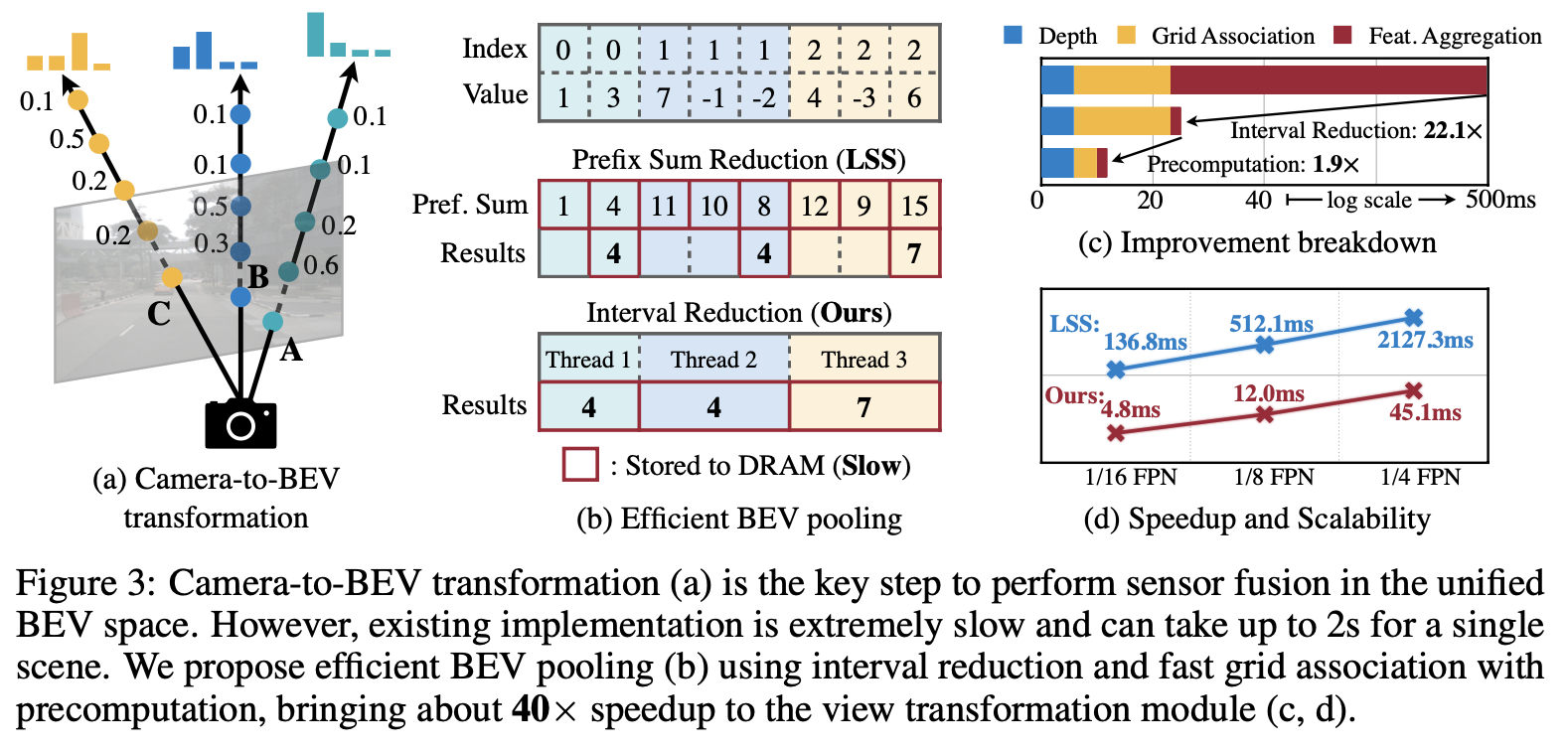
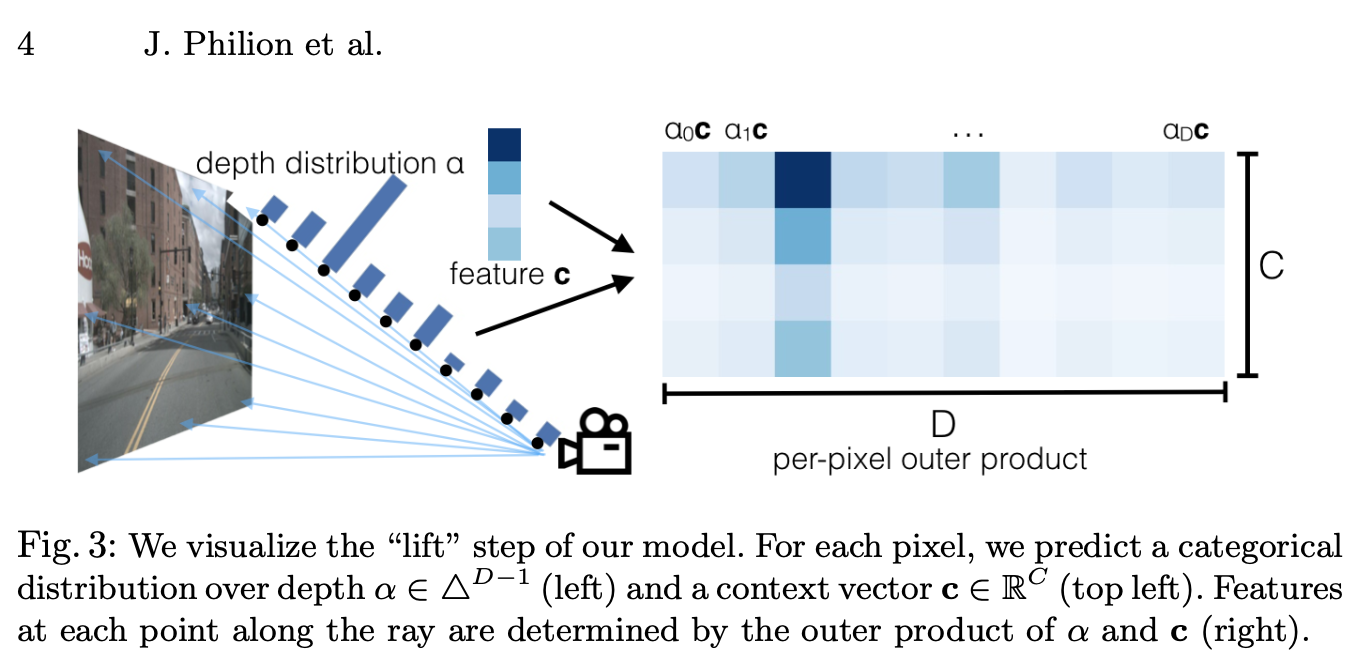
- 카메라 feature의 각 픽셀에 대응되는 depth는 본질적으로 모호하기 때문에 Camera-to-BEV 변환은 매우 중요
- 각 픽셀의 discrete depth distribution 예측
- Feature map의 각 픽셀을 카메라 광선에 따라 개의 discrete points로 분산
Feature map의 channel 수를 라 하였을 때 하나의 카메라의 feature map으로부터 생성된 Camera feature point cloud의 크기는 로 예상됨
- 3D feature point cloud는 축을 따라 step size 로 양자화 됨
- 모든 features를 BEV grid에 모으고 축을 따라 flatten 수행하기 위해 BEV pooling을 사용
Example)N = 6, (H, W) = (32, 88), and D = (60-1)/0.5=118
6개의 multi-view camera를 사용하며 각각의 256 X 704 이미지는 1/8 downsampling되어 32 X 88 camera feature map으로 추출
Depth는 1 ~ 60m, step size 0.5m 로 이산화
- Camera feature point cloud는 매우 크기 때문에 계산 속도가 느림
- 이를 해결하기 위해 본 논문에서는 precomputation과 interval reduction을 사용하는 최적화된 BEV pooling 방법 제안
BEV-pooling
Precomputation
- The first step of BEV pooling : Grid association
camera feature point cloud의 모든 점을 BEV grid에 속하는 하나의 그룹으로 묶는 과정
- LiDAR point cloud와 달리, 카메라의 내부, 외부 파라미터가 변하지 않는다면 Camera feature point cloud의 각 point의 좌표는 변하지 않음
- 이를 바탕으로 Camera feature point cloud의 모든 point의 3D 좌표와 BEV grid indices 미리 계산
- 모든 point들을 grid indices에 따라 정렬하고 각 point의 순위(rank of each point)를 기록하여 저장
위 문장이 잘 이해가 안되는데 내가 생각하기엔 camera feature point cloud의 크기가 이해하기 쉽게 (X, Y, Z, C)라 하였을 때
W->X, D->Y, H->ZBEV grid indices는 형태를 지니고 rank of each point는 값인듯하다. 위에서 BEV pooling을 point cloud에서 BEV 형태로 변환하기 위해 사용된다 하였으므로 Figure 3.b에서 index는 이고 value는 각 픽셀의 feature과 depth probability를 곱한 값이며, 같은 좌표의 grid에 속하는 point들을 sum pooling 하여 BEV 형태로 flatten하는 과정이라고 볼 수 있을 것 같다. 정확한 것은 추후 코드를 분석하여 확인할 예정이다.
- 추론 시에는 미리 계산된 순위에 따라 모든 feature point를 재정렬하여 사용
Interval Reduction
- The next step of BEV pooling : Feature aggregation
각 BEV grid 내의 feature들을 대칭 함수 (e.g., mean, max, and sum)로 집계(aggreate)
- 기존의 pooling은 Figure 3.b에서 보듯이 모든 point에 대해 prefix sum을 계산한 다음 인덱스가 바뀌는 경계에서 이전 경계의 결과값을 빼는 방식
- prefix sum 연산은 GPU에서 tree reduction을 필요
- 경계에서의 값만 필요로 하는 것에 비해 사용되지 않는 partial sum을 많이 생성하여 비효율적
- 본 논문에서는 feature aggregation을 가속하기 위해, BEV grid에 직접 병렬화하는 특수한 GPU kernel을 제안
- 각 그리드에 GPU thread를 할당하여 그리드내의 구간 합을 계산
- 제안된 커널은 그리드의 출력들 사이의 의존성을 제거하기 대문에 multi-level tree reduction이 필요하지 않음
- Feature aggregation의 지연 시간을 500ms에서 2ms로 단축 가능 (Figure 3.c)
Fully-Convolutional Fusion
- Shared BEV representation으로 변형된 두 센서의 feature는 concatenation과 같은 elementwise operator로 쉽게 융합 가능
- 하지만, LiDAR BEV features와 Camera BEV features는 같은 BEV 공간에 있지만, Camera feature map에서 depth를 계산하는 view transformer과정에서 부정확한 계산으로 어느 정도 공간적으로 불일치할 수 있음
- 이를 해결하기 위해 본 논문에서는 residual block을 포함하는 convolution-based BEV encoder를 사용하여 지역적인 불일치를 보상
- 결과적으로 제안된 방법은 더욱 정확한 depth estimation에 강점을 가짐
Multi-Task Heads
- 본 논문에서는 융합된 BEV feature map에 다양한 작업에 특화된 head를 적용하였으며, 대부분의 3D perception 작업에 적용 가능
Experiments
- 본 논문에서는 geometric-, semantic-oriented task인 Camera-LiDAR 센서 융합 기반 3D object detection, BEV map segmentation으로 BEVFusion 모델을 평가
Model
- Backbone
Image : Swin-T
LiDAR : VoxelNet
- Camera feature extractor : FPN
- 입력의 1/8 크기의 feature map 생성
- 앞선 methods 에서는 256 X 704 크기의 이미지를 1/8 크기로 downsampling 하여 32 X 88 크기의 camera feature map을 생성한 뒤 Camera-to-BEV transformation 한다고 하였으나, 여기에서는 카메라 이미지를 256 X 704 크기로 downsampling 한다고 함
We apply FPN [28] to fuse multi-scale camera features to produce a feature map of 1/8 input size. We downsample camera images to 256×704 and voxelize the LiDAR point cloud with 0.075m (for detection) and 0.1m (for segmentation)
- LiDAR point cloud는 detection 작업에서는 0.075m, segmentation 작업에서는 0.1m로 복셀화를 수행
- Detection과 segmentation은 다른 크기와 범위의 BEV feature map을 필요로 하기 때문에 각각의 task-specific head에 입력되기 전에 grid sampling과 bilinear interpolation을 적용하여 BEV feature map을 변환
Training
- 전체의 모델을 end-to-end 방법으로 학습
- 이미지와 LiDAR에 data augmentation을 적용하여 overfitting 방지
- 최적화는 AdamW를 사용하였으며 weight decay 사용
Dataset
- nuScenes
6개의 monocular 카메라 이미지와 FoV, 32-beams LiDAR scan 데이터를 포함하는 40,157개의 annotation 된 샘플
3D object Detection
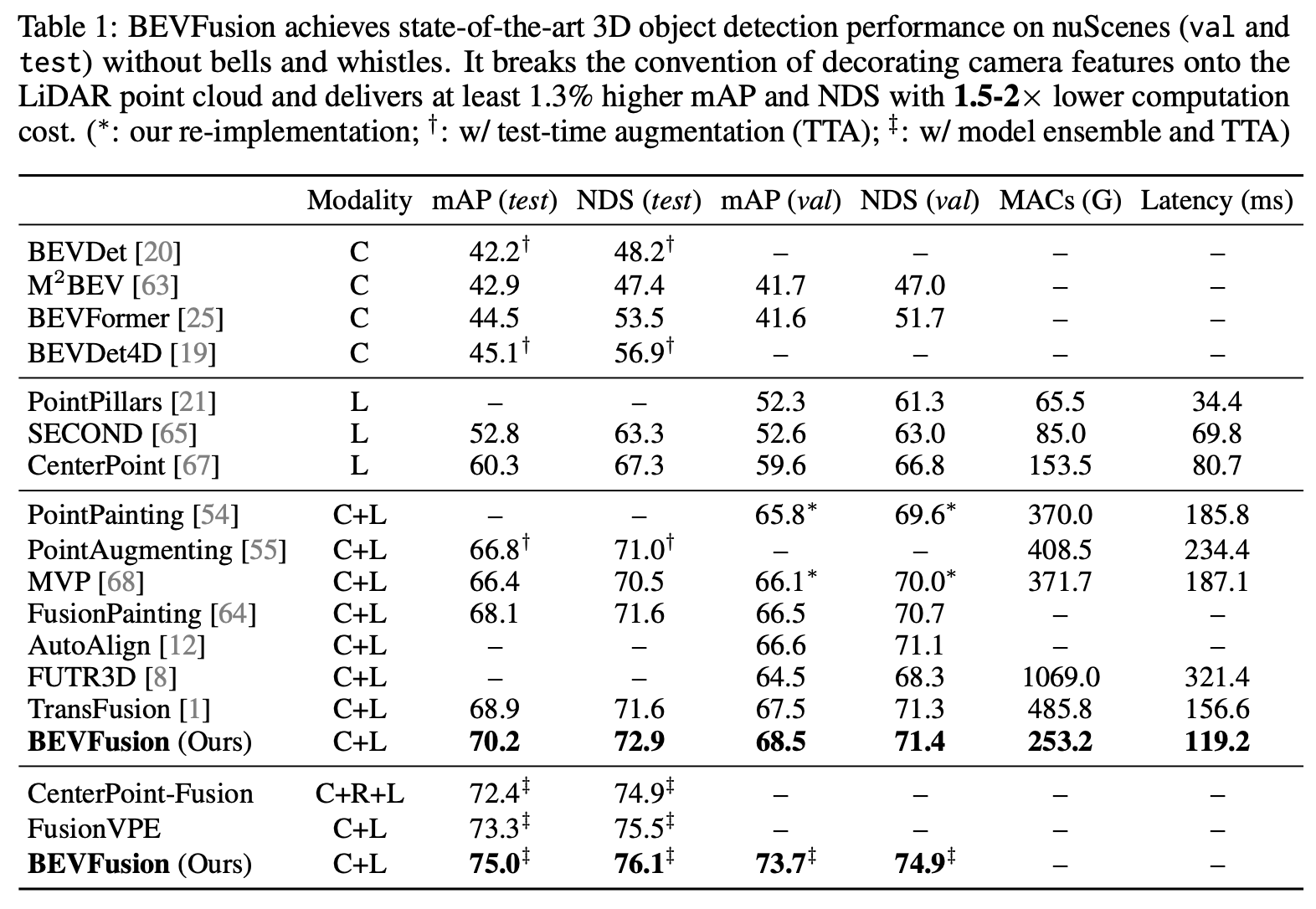
Results
- BEVFusion은 카메라의 features를 단지 5%만 사용하는 것이 아닌 전부 활용할 수 있는 BEV 영역을 fusion space로 사용하였기 때문에 높은 효율을 보여줌
- 또한, 효율적인 BEV pooling 연산자를 사용하여 같은 성능 대비 훨씬 적은 MACs를 보여주었음
MAC (Multiply-ACcumulates)
- 컴퓨터 비전에서 모델의 복잡도와 연산량을 측정하는 지표
- 모델이 수행하는 곱셈과 덧셈의 총 횟수를 나타내며, 일반적으로 1 MAC = 2 FLOPs (Floating Point Operations)
- MACs는 모델의 크기와 입력 이미지의 크기에 따라 달라지며, MACs가 작을수록 모델이 더 효율적이고 빠르다고 할 수 있음
BEV Map Segmentation
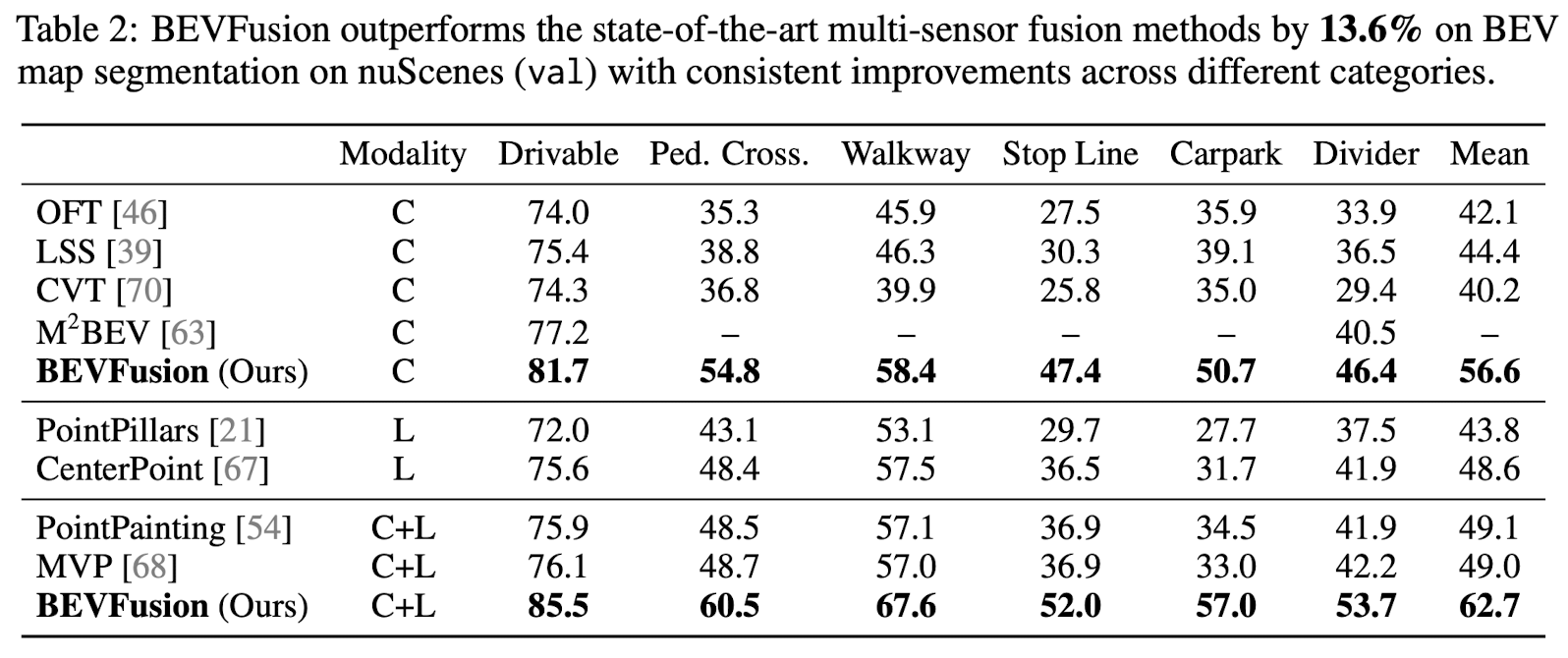
Results
- Table 1 (object detection) 에서 Camera-only의 SOTA 모델의 성능이 LiDAR-only 모델보다 떨어지는 반면 Table 2 (BEV map segmentation) 에서 Camera-only BEVFusion이 LiDAR-only baseline보다 성능이 뛰어남
- Multi-modality에서 BEVFusion이 다른 두 방법에 비해 높은 성능을 보임
- 다른 두 모델은 센서 융합에 있어서 LiDAR 형식이 더욱 효율적이라는 가정하에 Camera-to-LiDAR projection 방법을 사용하였으나 본 논문의 실험결과 이는 잘못된 가정이라고 주장
Analysis
Weather and Lighting
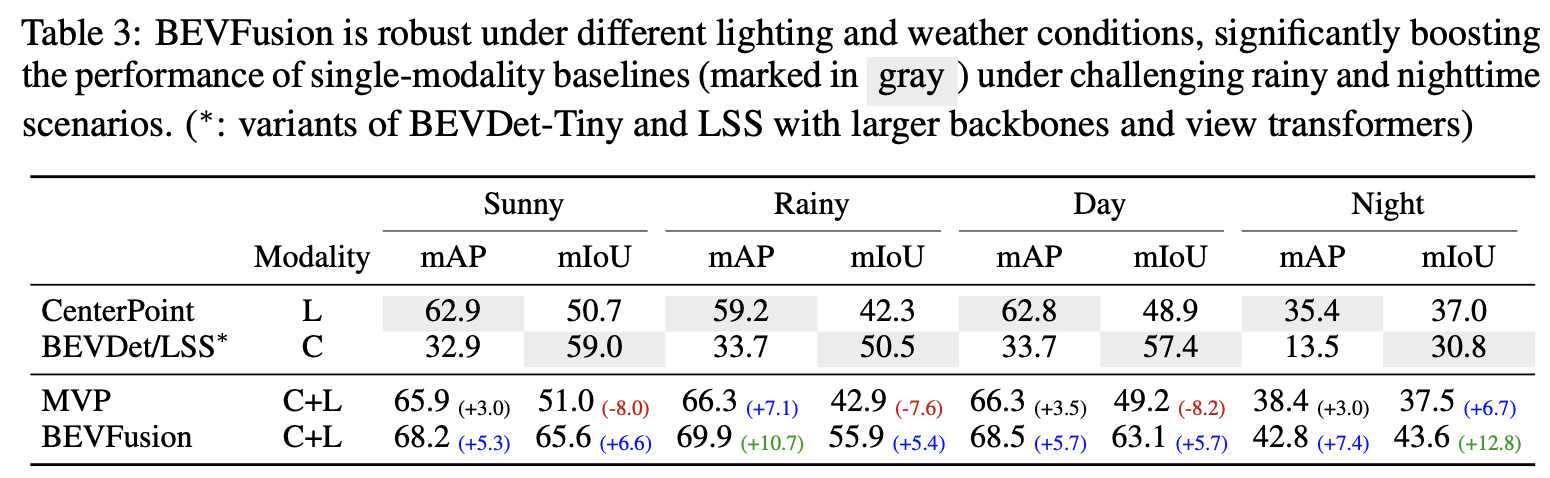

- Table 3에서는 여러 기상 조건에서 BEVFusion의 성능을 분석
- 비오는 날씨에는 LiDAR 센서에 심한 노이즈가 발생하기 때문에 LiDAR-only 모델은 object detection에 어려움이 있음
- 하지만 카메라는 환경 변화에 강인하기 때문에 BEVFusion은 비오는 날씨에서 성능이 향상 되었으며 화창한 날시와의 성능 차이를 줄였음
- 밤에는 BEVFusion이 camera-only 모델인 BEVDet/LSS 보다 mIoU가 약 12.8% 증가
- 이는 카메라 센서가 무용지물이 될 때 LiDAR로 부터 추출 된 geometric 정보가 얼마나 중요한 지를 보여줌
Sizes and Distances
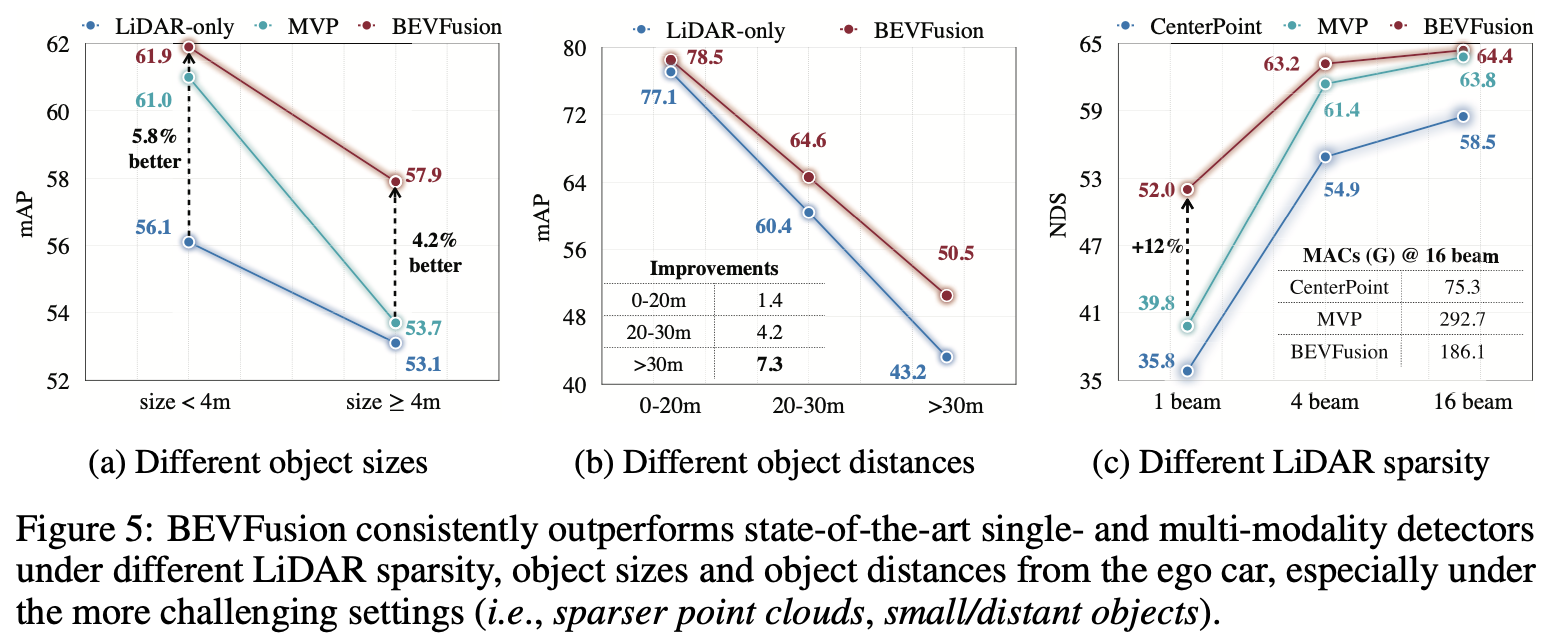
- Figure 5에서 BEVFusion은 모든 실험 조건에서 LiDAR-only BEVFusion보다 향상된 성능을 보여주었음
망상
- Figure 5.a와 b에서 크기가 작거나 먼 거리의 객체 검출 성능이 모두 크게 증가하였는데 이는 객체의 LiDAR point cloud는 희박하지만 밀도가 높은 카메라 정보에서 이득을 얻을 수 있기 때문
- Figure 5.b에서는 가까운 거리의 (큰) 객체 검출 정확도가 먼 거리의 (작은) 객체보다 높은 것에 비해, Figure 5.a에서 모든 모델의 작은 사이즈의 객체 검출 정확도가 큰 사이즈의 객체 검출 정확도보다 상대적으로 높음
- 논문에는 나와있지 않으나, 크기가 4m가 넘는 객체의 경우 객체 전체의 정보가 아닌 부분적인 정보만 포함되었기 때문이라고 생각함
- 이유
- MVP 모델은 카메라 이미지에 2D instance segmentation을 수행하고, 각 인스턴스에 속하는 픽셀들에 depth estimation을 하여 virtual point를 생성
이 가상의 점들을 LiDAR point cloud와 결합하여 3D 객체를 검출- 본 논문에서는 MVP 모델의 크기가 큰 객체의 검출 정확도가 LiDAR-only 모델에 비해 크게 향상되지 않은 이유를 이미 LiDAR point cloud의 밀도가 높기 때문에 virtual point를 사용한 증강 방법의 이득이 적기 때문이라고 하였음
- 이는 BEVFusion에도 어느정도 적용가능하기 때문에 MVP 모델의 성능 향상이 미미한 이유에 대한 근거라고 보기 어려울 듯 함
- 따라서 앞서 설명한 것과 같이 4m 보다 큰 객체는 부분적인 데이터만 포함하고 있으며, 2D instance segmentation이 부정확하기 때문에 MVP 모델의 성능 향상이 미미함
Sparser LiDARs
- MVP 모델은 카메라 이미지로부터 가상 point를 생성해 LiDAR point cloud 데이터를 증강시키고, 조밀해지고 semantic 정보가 추가된 LiDAR point cloud를 LiDAR-only CenterPoint 모델에 입력
- 당연히 CenterPoint의 성능에 큰 영향을 받음
- BEVFusion은 multi-modal 정보를 shared BEV space로 융합하기 때문에 강인한 LiDAR-only detector이 필요 없음
Ablation Studies
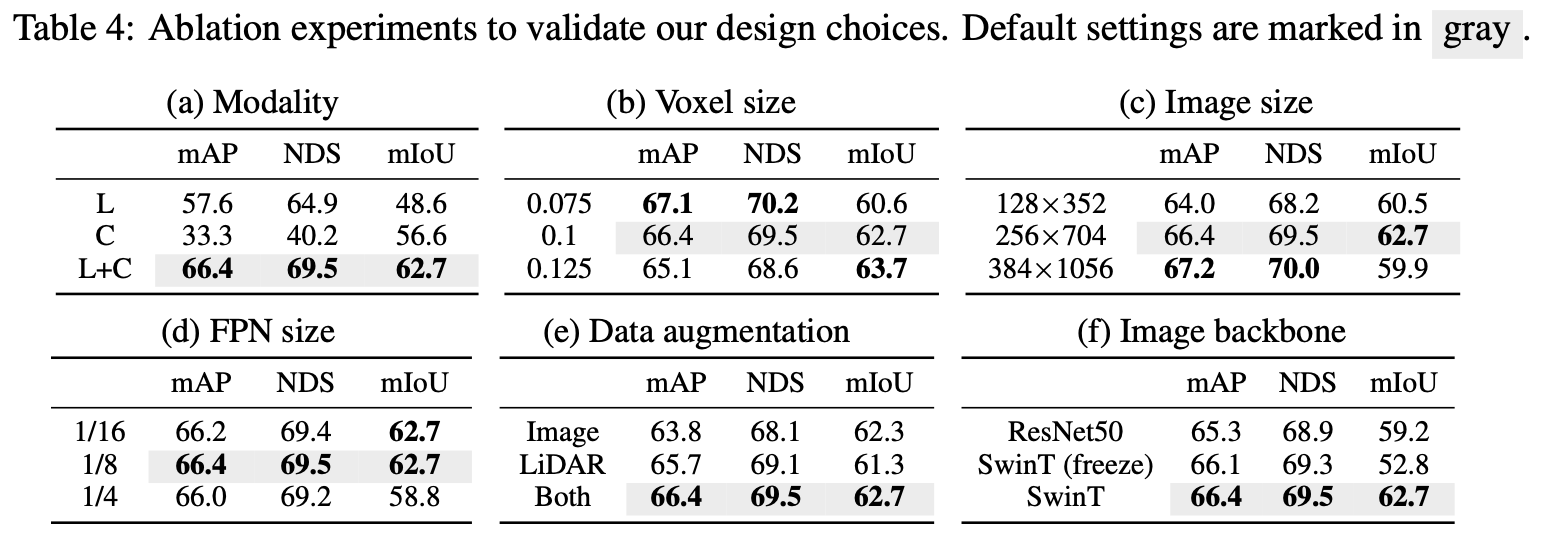
- Table 4.a
Camera-only segmentation, LiDAR-only detection에 비해 성능이 크게 향상되었으며, 이는 shared BEV space로 센서 융합하는 것이 geometric-, semantic-oriented task에 강점이 있다는 것을 의미
- Table 4.b, 4.c
BEVFusion은 복셀과 이미지의 해상도에 따라 다른 성능을 보임- Detection에서는 복셀과 이미지의 해상도가 높아질수록 성능이 좋아지지만, segmentation 작업에서는 이미지의 해상도가 256 X 704보다 커지면 성능이 더 이상 향상되지 않음
- Table 4.d
입력 이미지의 1/8 크기의 FPN feature를 사용하는 것이 detection과 segmentation 모두에 최적의 성능을 제공하고, 더 많은 연산을 수행하는 것은 성능 향상에 도움이 되지 않음
- Table 4.f
BEVFusion은 일반적인 다양한 백본 모델에 잘 작동
기존의 다중 센서 3D object detection 연구에서 흔히 사용되는 카메라 백본을 freeze 시키는 방법은 카메라 feature extractor의 잠재력을 완전히 활용하지 못하기 때문에 BEV segmentation에서 큰 성능 저하(10%)를 일으킴
Multi-Task Learning

- Negative transfer
- Table 5에서는 3D object detection과 instance segmentation 작업을 동시에 학습하는 것은 각각의 작업의 성능에 부정적인 영향을 미친다는 것을 보여줌
BEV encoder를 각 작업별로 분리하면 이 문제를 부분적으로 완화 가능하다고 설명
- Table 5에서는 3D object detection과 instance segmentation 작업을 동시에 학습하는 것은 각각의 작업의 성능에 부정적인 영향을 미친다는 것을 보여줌
Conclusion
- BEVFusion은 효율적이고 일반적인 multi-task multi-sensor 3D perception 프레임워크
- BEVFusion은 카메라와 LiDAR의 features를 shared BEV space에서 융합하는 방법으로 geometric, semantic 정보를 모두 보존
- 제안된 BEV pooling을 사용하여 camera feature map에서 BEV로 변환하는 과정을 40배 이상 가속화
- 기존의 point-level 센서 융합이 multi-sensor 3D perception에 최적의 선택이라는 오랜 관행을 깨뜨림
Limitations
- 다중 작업을 같이 학습할 때 성능 저하 발생
- 다중 작업 상황에서 더 큰 속도 향상을 달성하지 못하였음
- 본 논문에서는 정확한 depth estimation에 관하여는 깊이 탐구하지 않았으며, BEVFusion의 성능을 향상시킬 수 있는 가능성이 있음
References
