
1. 프로젝트 개요
| 프로젝트 주제 | Open -Domain Question Answering(ODQA) : Knowledge resource에서 주어진 지문을 찾아 이해하고 , 주어진 질의의 답변을 추론하는 task |
|---|---|
| 프로젝트 구현내용 | 1. Hugging Face의 Pretrained 모델과 Boost camp MRC 데이터 셋을 활용해 질문에 관련된 문서를 찾아주는 Retriever 와 관련된 문서를 읽고 적절한 답변을 찾거나 만들어 주는 Reader 를 구성하여 질의응답을 수행하는 AI 모델 구축 2. 리더 보드 평가지표인 EM과 F1 높은 점수에도 달할 수 있도록 Retriever, Reader 수정 및 데이터 증강 , 모델링 그리고 하이퍼파라미터 튜닝을 진행 |
| 개발 환경 | GPU: Tesla V100서버 5 개(RAM32G) / GeForce RTX 4090TI 로컬 (RAM24GB) 개발 Tool :PyCharm, Jupyternotebook, VSCode [서버 SSH 연결 ] |
| 협업 환경 | Github Repository : Baseline 코드 관리 및 CI 테스트 관리 Notion : 대회 Valid Score, Pubilc Score 기록 , 아이디어 브레인 스토밍 , 대회관련 회의 내용 기록 Slack,Zoom : 실시간 대면 / 비대면 회의 |
| 프로젝트 구조도 |  |
2. 프로젝트 팀 구성 및 역할
| 이름 | 역할 |
|---|---|
| 강민재 | Retrieval 리팩토링 (BM25 알고리즘 구현 ), 베이스라인 코드 리팩토링 (eval 단계에서 document retrieval 수행 ), 데이터 증강 (유사도 기반 wikipedia_documents 증강 ) |
| 김태민 | 베이스라인 코드 리팩토링 , RoBerta 모델 Head 레이어 수정 |
| 김주원 | 데이터 전처리 (KorQuAD 2.0), 베이스라인 코드 리팩토링 (Seed 고정 ), 모델 실험 (KorQuAD 2.0 Fine tuning, prompt engineering, 모델 하이퍼파라미터 튜닝 ) |
| 윤상원 | GitHub 프로젝트 관리 (PR, Issue 템플릿 배포 , CI 파이프라인 구축 ), 베이스라인 코드 리팩토링 , 모델 실험 (generation based MRC, TAPT, Prompt Engineering) |
| 신혁준 | Dense Passage Retrival 구현 |
3. 프로젝트 수행 절차 및 방법
원활한 협업을 위해서는 GitHub 을 사용할 때 반복적으로 수행되는 내용을 자동화하여 시간을 절약해야 한다고 생각했기 때문에 , 프로젝트 진행 전 Ground Rule 을 설정하여 GitHub 을 사용하는 규칙을 만들고 , Issue와 Pull Request 메세지를 작성하기 편리하도록 템플릿을 생성하였다 . 또한 , main 브랜치에 merge 된 코드에 이상이 없는지 빠르고 , 자동으로 확인하기 위해 CI 파이프라인을 구축함으로써 main 브랜치에 코드가 push 되거나 Pull Request 될 때마다 코드의 테스트를 자동으로 진행했다 .
3.1 협업 관련 Ground Rule
3.1.1 main branch Pull Request 관련 Rule
- main 브랜치에 merge 하기 전, 버그 수정 및 리팩토링한 뒤 PR 한다 .
- PR 메시지는 PR 템플릿에 맞게 메세지를 작성한다 .
- main 브랜치로 merg e 는 GitHub 담당자가 진행한다 . 만약 CI 테스트를 통과하지 못하는 경우 , 테스트에 통과할 수 있도록 코드를 수정한다 .
3.1.2 개인 Branch Commit 관련 Rule
- commit 메세지의 Header 와 Footer 는 필수로 작성하고 , Body 는 필요 시 작성한다 .
- Header 의 prefix 는 feat , fix, docs , style , refactor , perf 를 사용한다 .
- 하나의 commit 은 코드의 유의미한 변화가 있는 최소 크기로 나누어서 올린다 .
3.1.3 실험 관련 Rule
- 진행해야 하는 실험과 실험 진행 상황은 GitHub Issue 에 등록한다 .
3.1.4 Submission 횟수 제한 Rule
- 개인별로 submission 횟수는 2 회씩 할당한다 .
3.2 프로젝트 진행 Time line
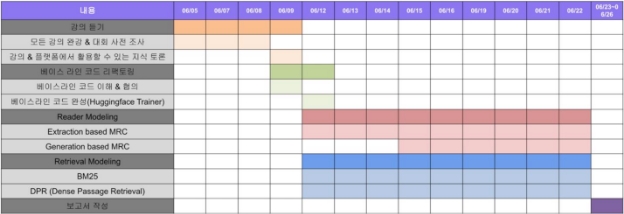
4. 프로젝트 수행 결과
4.1 베이스라인 코드 리팩토링
- 기존의 코드에서 훈련에 사용된 코드가 모두 한 .py 파일에 명시되어 있어 Train 과 Inference 에 공용으로 사용된 코드를 분할하여 코드를 독립적으로 구현했다 .
- 데이터 셋의 경우 Train, Validation, Inference마다 코드가 함수 형태로 있어 반복하여 쓰기 어려웠지만 이를 Class 형태로 통합하여 dataset.py 파일 하나로 만들었다 .
- 기존에 쓰이던 매트릭스 등을 utils 로 빼놓아서 만들었으며 기존의 훈련에서는 훈련 도중 Validation 을 수행하지 않았지만 , epoch마다 Validation 을 수행하고 바꾸었다 .
- HuggingFace Trainer 를 사용하면서 기존의 Argument 를 더욱 손쉽게 수정할 수 있도록 변경하였다 .
- 또한 pyarrow 형식의 데이터를 읽는 기존 베이스라인 코드를 CSV 형식의 데이터를 읽을 수 있도록 수정했다 . 데이터의 형식을 CSV로 수정함으로써 데이터의 내용을 확인하기 용이하고 , 손쉽게 데이터를 증강할 수 있게 되었다 .
4.2. 데이터 증강
4.2.1 Passage 데이터 증강
- Retrieval 은 벡터화된 위키피디아 문서로 구축된 데이터베이스를 사용한다 . Query가 입력되면 , 모든 document 와 TF-IDF 또는 BM25 알고리즘을 통해 계산된 점수로 유사도를 계산한다 . 그 후 유사도가 높은 상위 k 개의 문서를 반환한다 . 그러나 구축된 데이터베이스에 실제로 질문과 연관된 문서가 없다면 , 유사도가 높은 문서가 검색되어도 해당 문서 내에서 정답을 찾기 어려울 것이다 . 이 문제는 데이터베이스에 사용된 문서를 증강하면 해결된다는 가설을 설정하였다 .
- HuggingFace Dataset 에 업로드 되어있는 graelo/wikipedia 데이터 셋에서 , 한국어 위키피디아 문서로 구축된 20230601.ko 데이터를 사용하여 documents 를 증강하였다.
- 증강에 사용한 데이터 셋을 그대로 사용하지 않고 유사도를 기반으로 필터링을 수행하였다 . 외부 데이터셋의 샘플과 원본 document 각각에 대한 TF-IDF 점수를 곱하여 유사도를 계산하였다 . 가장 유사도가 높은 문서와의 유사도가 threshold (실험에 서는 0.7 을 사용 ) 이하일 경우에만 증강 데이터에 포함하였다 . 유사도가 threshold 이상인 문서가 존재한다면 , knowledge base를 확장한다는 가설에 부합하지 않기 때문이 다.
- 이 방식을 사용하여 documents 에 포함된 passage 를 기존 56737 개에서 86947 개로 총 30,210 개 증강하였고 , validation EM 점수가 기존 57.08 점에서 증강 후 59.17 점으로 2.09 점 향상되었다 .
4.2.2 KorQuAD 2.0 데이터 증강
AI Stage에서는 아래와 같이 3952 개 질의응답 학습 데이터를 제공하지만 문맥을 이해해야 하는 Extraction based MRC Reader 를 학습하기에는 데이터양이 부족하다고 판단했다 . 따라서 외부 데이터를 사용해 리더를 학습시킨다면 성능을 개선할 수 있다고 가설을 세워 외부 데이터를 탐색했다 . 최종적으로 47957 개의 wikipedia article 을 활용한 KorQuAD 2.0[1] 데이터를 MRC Task의 추가 학습 데이터로 활용하기로 결정했다 . 이후 , 서버 메모리 capacity 을 고려하여 길이가 7500 이하의 데이터 27423 개를 학습에 활용했다 .

Level 1~ Level 2의 NLP Task를 진행하면서 학습 데이터와 테스트 데이터의 일관성을 유지하며 학습을 용이하게 해준다는 인사이트를 얻을 수 있었다 . 따라서 , 외부 데이터와 이미 주어진 학습 데이터의 EDA를 진행하여 유사점과 차이점을 분석하였고 이를 전처리에 적용하였다 . 주어진 학습 데이터에 존재하 지 않는 태그 , 유니코드 BOM, 하이퍼링크 , 무분별한 newline 기호 , 불필요하게 모든 문서에서 반복되는 footer 를 제거해 주었다 . 이후 , klue/roberta -large 모델의 special token 을 확인하여 불필요한 데이터를 삭제했는지 확인하였고 , 일부 외국어 데이터는 special token 으로 활용되고 있으므로 삭제하지 않고 학습 데이터로 구축하였다.
4.3 Retrieval 모델
4.3.1 BM25
베이스라인에서 retrieval 를 통해 문서를 검색하는 데는 TF-IDF 점수가 사용되었다 . TF-IDF 는 단어의 등장 빈도인 Term Frequency 와 단어가 제공하는 정보의 양인 Inverse Document Frequency 를 곱한 값으로 word level에서 문서의 의미를 수치화한 것이다 . 입력된 질의와 문서에 대한 유사도는 아래와 같이 계산한다 .
NLP ODQA 프로젝트 (Open -Domain Question Answering) NLP-08 조 팀 회고

TF-IDF 방식은 희소 행렬을 사용하여 빠르게 문서의 유사도를 계산할 수 있다는 장점이 있지만 , 단어가 제공하는 정보의 양인 IDF를
계산할 때 문서의 길이를 고려하지 않는다 . 실제로 식을 해석해 보면 , ( ) = { / ( )}에서 볼 수 있듯이 , 단순히 전체 문서에서 단어 t 가 등장한 횟수만을 고려하여 단어의 중요성을 판단한다 . 이러한 문제점을 개선한 알고리즘이 BM25 이다 . BM25는 아래 식에서 나타나는 것과 같이 전체 문서의 평균 길이에 대한 현재 문서의 길이를 고려하여 단어의 중요도뿐만 아니라 ‘문장 내에서 의미상으로 얼마나 비중을 갖는지를 수치화한다 .

BM25 알고리즘을 구현하기 위해 rank_bm25 라이브러리를 사용하였고 , BM25Okapi, BM25L, BM25plus 방식을 모두 시도하여 retrieval 의 성능을 비교하였다 .
성능 비교
TF-IDF와 BM25 알고리즘의 성능을 비교하기 위해 klue/roberta -large 모델을 사용하여 학습한 후 inference 결과를 비교하였다 . public EM을 기준으로 TF-IDF를 사용한 기존 모델의 점수 57.92 점에서 BM25 를 사용하여 60 점으로 2.08 점을 향상하였다 . BM25 알고리즘의 계산 방식은 검증 단계에서 비교하였다 . 기존 베이스라인에서는 validation data 에 이미 context 가 포함되어 있어 , retrieval 의 성능을 비교하기 어려웠다 . 이 문제를 해결하기 위하여 eval_as_train 인자를 추가하여 값이 True 일 경우 context 를 삭제하고 , retrieval에서 지정한 알고리즘 (BM25 또는 TF-IDF)에 의해 문서를 검색하여 context 를 새롭게 생성하도록 베이스라인을 변형하였다 . 이 방식으로 검증 단계에서 BM25 Okapi, L, plus 알고리즘의 성능을 비교하였고 , 그 결과는 다음과 같다 .
| BM25 Okapi | BM25 L | BM25 plus | |
|---|---|---|---|
| Exact Match | 54.23 | 33.20 | 57.08 |
4.3.2 Dense Passage Retrieval
입력된 query 와 임베딩 한 후 정답이 있는 passage 를 검색할 passage 임베딩을 만들었다 . klue/bert-base 사전학습 모델로 query 와 passage 를 임베딩으로 만드는 인코더를 학습했다.
데이터 셋 준비
- Query encoder 와 Passage encoder 를 학습하기 위해서 KorQuAD 1.0 데이터에서 query 와 answer 가 있는 positive pair 를 사용했다 .
- query encoder 와 pass age encoder 는 KorQuAD 1.0 데이터 셋의 question 과 context Pair 를 in batch negative sampling 을 통하여 새로운 데이터 셋을 구상하였다 . contrastive learning 을 수행하여 question 과 passage 를 같은 차원에 맵핑하였다 .
학습
P 인코더와 Q 인코더를 동시에 학습했다 . P 인코더의 output 임베딩과 Q 인코더의 output 임베딩을 행렬 곱 연산과 코사인 유사도를 사용하여 nll loss를 계산하였다 . positive pair인 target 은 1, negative pair는 target 을 0 으로 하여 query 와 passage 의 유사도가 높은 positive pair 는 같은 차원에서 임베딩 거리가 가까워지고 , negative pair는 임베딩 거리가 멀어지도록 contrastive learning 훈련을 진행했다 .
추론
위키피디아 데이터를 P 인코더에 입력으로 넣어 passage 임베딩을 만들고 , inference 할 질문들을 Q 인코더에 입력으로 넣어 query 임베딩을 만들었다 . 이후 질문과 코사인 유사도가 높은 순으로 passage 를 top_k 개 반환했다 .
4.4. Extraction based MRC
4.4.1 KorQuAD
Baseline MRC 모델의 성능을 향상하기 위해 두 단계로 나눠 fine-tuning 을 진행했다 . 이를 두 단계로 나눈 이유는 먼저 외부 데이터를 활용하여 MRC Task에 최적화된 모델을 만들고 이를 활용하여 성능을 향상하기 위함이었다 . 따라서 첫 번째 단계에서는 전처리된 KorQuAD 2.0 데이터를 이용하여 PLM(Pre-trained Language Model)을 학습시키고 , 그 후 두 번째 단계에서는 원본 학습 데이터에 대해 fine tuning 을 수행하였다 . KLUE 논문 [2]에서 klue/roberta -large 모델의 하이퍼파라미터를 참고하여 learning rate 는 1e-6 ~ 3e-5 사이에서 조정하고 , batch size는 8, 16의 범위에서 실험하여 최적의 성능을 갖는 모델을 구축했다 .
결과 비교
다음 표는 klue/roberta -large 모델과 KorQuAD 2.0 데이터로 학습된 모델을 fine tuning 한 EM과 F1 점수를 비교한 결과이다 . validation 을 기준으로 EM과 F1-score 모두 개선되어 각각 5 점과 3.37 점이 증가하였으며 , public score를 기준으로도 EM과 F1-score 가 각각 3.37 점과 2.73 점 상승하였다.
| 사용 기법 | validation EM | validation F1 | public EM | public F1 |
|---|---|---|---|---|
| TF-IDF + klue/roberta -large (Baseline) | 69.1667 | 77.4293 | 54.58 | 65.67 |
TF-IDF + uomnf97/klue-roberta - finetuned-korquad-v2[3] | 74.1667(+5) | 82.6015(+5.17) | 57.92(+3.37) | 68.40 (+2.73) |
4.4.2 모델 레이어 수정
모델의 Head 토큰들을 기존에는 단순히 Linear 층 1 개로 구성하여 logit 값들을 뽑아냈지만 , 이를 RoBERTa LM Head를 추가함으로써 아래와 같은 식으로 수정하여 모델의 레이어의 head 부분을 수정하였다 .
변환 전

변환 후

4.4.3 TAPT
데이터에 대한 이해도를 높이기 위해 task 에 맞는 형식의 데이터 셋을 Masked Language Modeling 방식으로 모델에 학습시켰다 . train 데이터 셋과 validation 데이터 셋 외에 KorQuAD 데이터 셋을 활용하여 학습시켰지만 , 유의미한 성능 차이를 확인하지 못했다 .
4.5. Generation based MRC
4.5.1 학습 및 추론 코드 구현
generation based MRC를 개발하기 위해 encoder -decoder 구조의 T5 모델을 사용했다 . T5 모델을 학습시키기 위해 기존 베이스라인의 학습 코드에서 모델에 주어지는 입력 값, 모델이 예측한 결과 값을 후처리하는 함수 , 평가 지표 계산 방식을 수정하여 huggingface trainer 를 활용한 학습 코드를 구현했다 . 추론 코드의 경우 , retrieval 모델이 찾아낸 질문과 연관성이 높은 k 개의 본문을 가지고 데이터 셋을 만든 뒤, data loader를 통해 데이터를 모델에 입력하여 예측 값을 생성했다 .
4.5.2 모델이 예측한 정답 후보 중 정답을 선택하기 위한 Score 함수 구현
- retrieval 모델이 검색한 k 개의 본문와 질문을 tokenizing 하여 모델에 입력하면 하나의 질문에 대해 여러 데이터 셋이 모델의 입력으로 주어지게 된다 . 따라서 모델은 하나의 질문에 대해 여러 개의 정답을 예측 값으로 내놓게 된다 . 이 때, 모델이 예측한 여러 개의 정답 중 가장 높은 confidence 로 예측한 하나의 정답만을 해당 질문의 정답으로 사용해야 하기 때문에 , 각 예측 값에 대한 모델의 confidence score 를 계산하는 함수를 구현했다 .
- 하나의 예측 값에 대해 모델이 생성한 각 토큰의 probability 의 logit 값을 모두 더하면 해당 예측 값에 대한 누적 probability 의 logit 값을 계산할 수 있다 . 그러나 , 앞에서 설명한 계산 방식은 길이가 긴 seqeunce 의 경우 , probability 가 낮게 계산되기 때문에 length penalty 를 도입해 길이가 긴 sequence 의 probability 값을 보정했다 . length penalty 는 beam search 에서 probability 를 계산할 때 적용하는 length penalty 공식을 적용했다 .
4.5.3 Prompt Engineering
모델에 question 과 context 의 내용을 확실하게 구분해서 입력하기 위해 “질문 : 본문 : ”의 형식으로 데이터를 전처리하여 모델에 입력했다 . prompt engineering 을 하지 않았을 때 26.64 점이었던 public EM 점수를 27.08 점으로 향상할 수 있었다 .
4.5.4 Beam Search
토큰 생성 시, step마다 누적 확률이 가장 높은 n 개의 sequence 를 뽑아 , 다음 step 의 토큰을 생성하는 방식을 사용했다 . n이 커질수록 많은 경우의 수를 고려할 수 있지만 , 실행 시간이 늘어난다는 trade -off 가 존재한다 . greedy search 방식으로 생성했을 때 27.08 점이었던 public EM 점수를 n=4 의 beam search 를 활용하여 28.75 점으로 향상할 수 있었다 .
4.6 성능
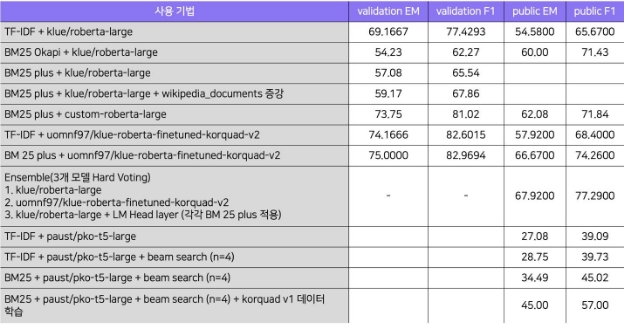
- 앙상블 : 앙상블 모델은 Hard Voting 기법과 Soft Voting 기법을 결합하여 구현했다 . 해당 모델에서 일반적으로 가장 많은 표를 받은 예측 값을 최종 예측 값으로 선택한다 . 동일하게 표가 주어진 경우 각 예측 값 확률의 평균을 구해 가장 높은 확률 값을 가지는 데이터를 예측 값으로 반환하도록 구현했다 . BM 25 Retriever가 적용된 klue/roberta -large , uomnf97/klue-roberta-finetuned-korquad-v2 , klue/roberta-large + LM Head layer 3 개의 모델 앙상블을 진행했다 . 해당 모델을 통해 최종적으로 가장 높은 성능인 67.92 점의 public EM과 77.92 점의 public F1 점수를 얻을 수 있었다 .
5. 자체 평가 의견
5.1. 잘한 점
- 팀 내에서 commit convention 을 정해서 적용해 본 결과 , 다른 팀원의 작업뿐만 아니라 내가 과거에 한 작업도 손쉽게 찾을 수 있었다 .
- 팀이 외부 경진대회를 병행하는 상황임에도 불구하고 모델 수정 , extraction/generation based MRC, BM25/DPR 구현 등 다양한 시도가 이루어졌다 .
- 이전과 다르게 GitHub issue/PR Template 를 만들어 협업에 활용하고 GitHub Action으로 CI를 구축하여 버전 관리를 체계화하는 등 최종 프로젝트를 앞두고 팀이 체계적으로 GitHub 을 협업하고 관리하는 법을 함께 익힐 수 있는 기회가 되었다 .
- 팀원들끼리는 자신이 맡은 부분이 아니더라도 , 구현이 원활하지 않은 부분이 있을 때 상호 간에 질문하고 도움을 주며 코딩을 진행했다 .
5.2 시도 했으나 잘 되지 않았던 것들
- rank_bm25 라이브러리 내 위에서 언급한 것 외에 BM25 Adpt, BM25T 방식이 주석 처리된 채 구현되어 있었다 . 주석을 해제하고 retrieval 에 적용하려 했지만 , 다른 방식들과 입출력 형식이 달라서 적용 후 성능을 비교하기 어려웠다 . 수식에 대한 이해가 미흡했기 때문이라고 생각하는데 , 이를 분석한 후 실제로 구현해 보고 싶다는 생각이 들었다 .
- dense passage retrieval 에 포함되는 in batch negative에서 negative sample 의 수를 적게 주었다 . 그 결과 정답이 아닌 다른 passage 와 임베딩 거리를 멀리하는 학습을 하지 못했다 . 따라서 query 의 정답이 있는 passage 를 retrieval 하지 못했다 . negative samlpe의 수를 늘리면 query 와 positive passage 의 임베딩 거리는 가까워지고 더 많은 negative passage 와의 임베딩 거리는 멀어져 retrieval 의 정확도가 높아질 것이다 .
- extraction based MRC 의 prompt engineering 을 진행하여 입력에 question 과 passage 를 구분할 수 있도록 punctuation 이나 ‘질문 , 답변 ’ 등을 추가해 보았 지만 , 성능이 감소하였다 . question 의 answer 를 context 에서 찾는데 해당 punctuation 이나 토큰들이 이미 많이 context 에 존재해 질문의 난이도를 높여 모델이 문맥을 파악하는 데 어려움을 주었겠다고 판단했다.
5.3 아쉬웠던 점들
- wikipedia_documents 를 증강할 때 threshold 를 임의로 설정하였는데 , 다양한 시도를 통하여 이 값을 최적화하지 못한 게 아쉽다 . 또한 , 데이터 증강에 예상보다 매우 긴 시간이 걸려서 많은 양의 데이터를 증강하지 못한 점도 아쉬움으로 남는다 .
- 외부 데이터를 활용하여 모델을 학습했을 때, 하이퍼파라미터 튜닝에 많은 시간이 소요되어 시간적 여유가 부족했고 , 이에 따라 추가적인 외부 데이터 전처리 및 튜닝에 시간을 할애하지 못했다 . 만약 , 다른 외부 데이터를 활용했다면 팀 내에서 extraction/generation based MRC 에서 더 의미 있는 성능 향상을 이끌어낼 수 있었을 것으로 예상되어 많은 아쉬움이 남았다 .
- 시간적인 제약으로 인해 앙상블 과정에서는 hard voting 만 적용했고 , soft voting 및 weighted voting 기법을 활용하지 못했다 .
5.4 프로젝트를 통해 배운 점 또는 시사점
- 검색을 수행하는 모델의 성능이 좋아져도 , 검색에 활용할 적절한 문서가 존재하지 않는다면 올바른 답을 찾아내기 어렵다는 것을 경험을 통해 배울 수 있었다 . retrieval의 중요성에 대해서 깨닫게 되었고 , MRC 모델 뿐만 아니라 retrieval system 의 성능 개선을 위한 다양한 방법론이 존재함을 배울 수 있었다 .
- 팀 내에서 시도했던 extraction/generation based MRC 모두 외부 데이터를 함께 활용했을 때 성능이 향상하는 것을 볼 수 있었다 . ‘모델의 성능을 올리기 위해서는 데이터가 중요하다 ’는 사실을 실험을 통해 다시 한번 깨달을 수 있었다 .
6. 참고 문헌 (References)
[1] KorQuAD 2.0 data : https://korquad.github.io/ [2] Sungjoon Park, Jihyung Moon, Sungdong Kim, Won Ik Cho, Jiyoon Han, Jangwon Park, Chisung Song, Junseong Kim, Yongsook Song, Taehwan Oh, Joohong Lee, Juhyun Oh, Sungwon Lyu, Younghoon Jeong, Inkwon Lee, Sangwoo Seo, Dongjun Lee, Hyunwoo Kim, Myeonghwa Lee, Seongbo Jang, Seungwon Do, Sunkyoung Kim, Kyungtae Lim, Jongwon Lee, Kyumin Park, Jamin Shin, Seonghyun Kim, Lucy Park, Alice Oh, Jung-Woo Ha, Kyunghyun Cho. KLUE: Korean Language Understanding Evaluation, NeurlPS, ppl 1~25, May 2023
[3] KorQuAD 2.0으로 학습하여 배포한 huggingface 모델, https://huggingface.co/uomnf97/klue-roberta-finetuned - korquad-v2
개인 회고
1. 나는 내 학습 목표를 달성하기 위해 무엇을 어떻게 했는가 ?
이번 학습 목표로는 크게 NLP 의 꽃인 질의응답 테스크 자체를 이해해보자고 생각하였다 . 이를 위해 성능을 높이는 것보다는 베이스라인을 이해하고 리팩토링하며 테스크에 대해 전반적으로 높은 이해도를 얻어낼 수 있었다 . 또한 개인적으로 모델링에 관심이 조금 더 많아 전에 KLUE-RE 테스트보다 간편하게 모델을 수정하는 코드를 작성하고 GitHub 를 통해 공유하였다 .
2. 마주한 한계는 무엇이며 , 아쉬웠던 점은 무엇인가 ?
마주친 한계로써는 우선으로 KDT해커톤 을 일주일 동안 진행 후 대회에 참가하였지만 몸 관리 실패로 인하여 일주일 가까이 감기에 시달린 게 가장 큰 문제였다 . 몸 관리의 중요성을 깨달았으며 컨디션의 관리 또한 매우 중요하였다 . 대회적인 부분으로써는 많이 시도한 것이 없지만 최근 CLIP 논문을 읽고 있어 이와 비슷한 훈련방식을 가져가는 DPR을 하고 싶었지만 . 맡은 부분이 아니기에 살짝 아쉬운 부분이 존재하였다 .
3. 한계 /교훈을 바탕으로 다음 프로젝트에서 시도해보고 싶은 점은 무엇인가 ?
우선 무엇보다 몸 관리를 최우선 과제로 두고 컨디션을 잘 관리하여야겠다 . 코딩 실력보다 중요한 건 자기관리인 거 같은 생각이 머릿속에 깊게 박힌 프로젝트였다 . 다음 프로젝트의 경우 파이널 프로젝트로써 지금까지 배운 AI 기술들을 활용하며 이제 BERT에서 벗어나 GPT,LLM을 집중적으로 다루어 활용해보고 싶다 . LLM의 코드를 이미 작성해두었지만 4bit Lora tuning등 시도해야 할 것이 아직 많이 보인다 .
4. 나는 어떤 방식으로 모델을 개선했 는가 ?
모델의 개선은 위에 나와 있는 방식으로 개선하였으며 가장 중요한 점은 기존의 이해하기 어려운 베이스라인을 더욱 쉽게 리팩토링을 진행하여 파라미터 튜닝 , 모듈화를 집중적으로 개선한 부분이 큰 것 같다 .
이를 통해 retriver 와 Reader 의 역할을 깨달아 이 둘을 구분하여 개선 방향을 모색하였다 . 기존의 메인코드에 몰려있던 모든 함수를 리팩토링을 진행하여 기존의 데이터셋 코드가 훈련 , 평가에 중복적으로 들어가 코드가 난잡하였지만 데이터는 데이터코 드에 클래스로 정리하여 중복을 제거하고 , 훈련 코드는 Trainer 훈련 코드를 사용하여 파라미터를 쉽게 변경할 수 잇었으며 , korquad 매트릭스나 리트리버에서 몇 개의 문서 집합을 가져오는 코드와 같은 유틸 코드는 유틸에 따로 모아둠으로써 관리를 쉽게 진행하였다 .
5. 내가 해본 시도중 어떠한 실패를 경험 했는가 ? 실패의 과정에서 어떠한 교훈을 얻었는가 ?
모델 레이어 수정 : 레이어를 수정하려고 각종 논문을 찾아보았지만 새로운 모델을 제외한 기존 모델에서 레이어를 수정 한 부분은 적었다 . 확실히 HEAD 의 레이어를 수정하는 것보다는 어떻게 인코더 파트에서 벡터를 잘 만드는 것이 중요한지를 깨달을 수 있었는데 그래도 우선적으로 근거있게 레이어를 수정하였다 . 첫 시도는 트랜스포머의 feed forward layer 을 참고하여 이와 동일하게 구성하였다 . 물론 성능 향상이 있었지만 유의미하지는 않았다 . 아마 RelU 함수의 역할을 내가 아직 0 은 0 으로 그 이상값은 선형적으로 내보는 것 이외의 역전파 단계에서의 무슨 역할을 하는지 잘 모르는 것 같다는 생각이 들어 단순 forward 구문이 아닌 bacward 에서의 역할도 알아야겠다는 생각이 크게 들었다 .
6. 협업 과정에서 잘된점/아쉬웠던점은 어떤것이 있는가?
협업은 이번에 잘된 것 같았다 . 첫 대회는 노션을 집중적으로 사용하였고 그 이후 대회는 두 개를 동시에 사용하였지만 , 깃허브를 많이 사용하지는 않았다 . 하지만 이번에는 깃허브의 비중이 90% 이상일 정도로 노션은 기록용으로만 사용하였다 . 파이널 프로젝트를 대비해 필요한 기능을 이슈로 처리하고 사용하며 이슈에 대한 커밋 그리고 최종 푸시와 풀리퀘를 모두 연관 지어 사용하였으며 모든 부분에 대하여 템플릿을 적용하였다 . CI 또한 사용하여 풀리퀘스트 할시 자동으로 테스트가 수행되도록 진행하였다 . 기존보다 완벽히 깃허브를 사용하여 협업을 사용하였다는 점이 굉장히 잘된 점이라고 생각된다 . 아쉬운 부분은 이처럼 CI등 다른 유틸적인 부분에 집중을 하다 보니 정작 대회의 성적은 낮았다 . 하지만 이보다 중요 한 최종 프로젝트를 대비하기엔 알찬
대회라고 생각된다 .
