boostcamp3week
1.네이버 부스트캠프 5기 15일차

위와 같은 데이터셋으로 0~9까지의 글씨 사진과 라벨로 0~9까지의 라벨이 그려져 있음위와 같은 모델을 구성할 경우 mnist의 이미지 shape (28,28,1)이 들어올때 이를 view함수로 먼저 (-1,28\*28)로 변환 시켜주고Linear층을 통하여 선형결합을
2023년 3월 21일
2.네이버 부스트캠프 5기 16일차

시퀀스 모델인 LSTM으로 Mnist를 분류 해보자우선 LSTM의 인풋은 총 3개이다 cell state와 h-1 state 이때 배치별로 처음 데이터가 들어올경우 t-1의 cell state와 h-1 state가 없음으로 단순히 torch.zeros를 통해 만들어주고
2023년 3월 22일
3.네이버 부스트캠프 5기 17일차

직사각형 막대를 이용하여 데이터의 값을 표현 주로 수직,수평으로 분류수직x값 : 범주 y값 : Value수평x값 : Value y값 : 범주각 그룹을 표시하는데 stack하여 표현하는 Plot이다.각 그룹의 순서는 항상 유지되어야 한다.물론 이 또한 barh를 이
2023년 3월 25일
4.네이버 부스트캠프 5기 19일차 ViT 코드리뷰
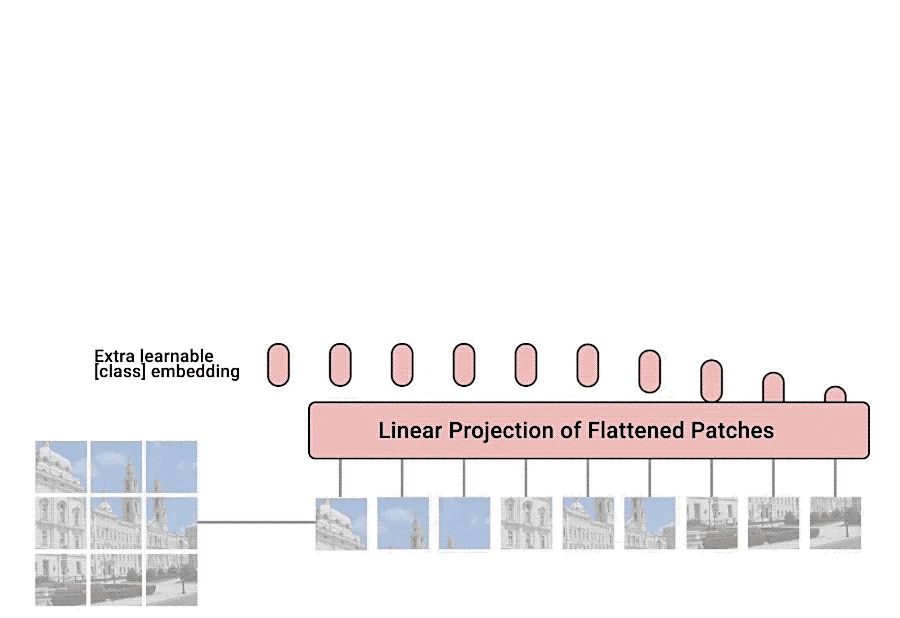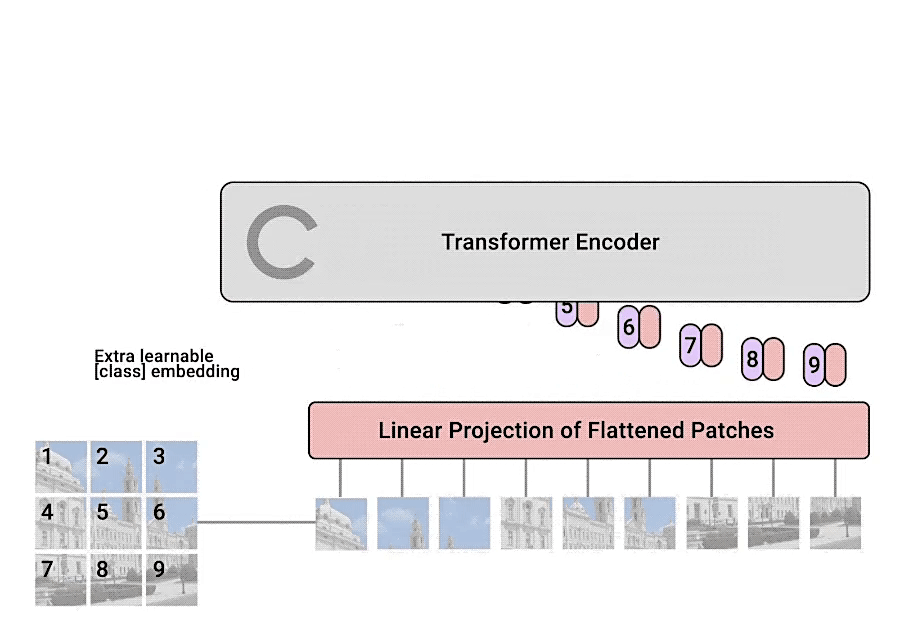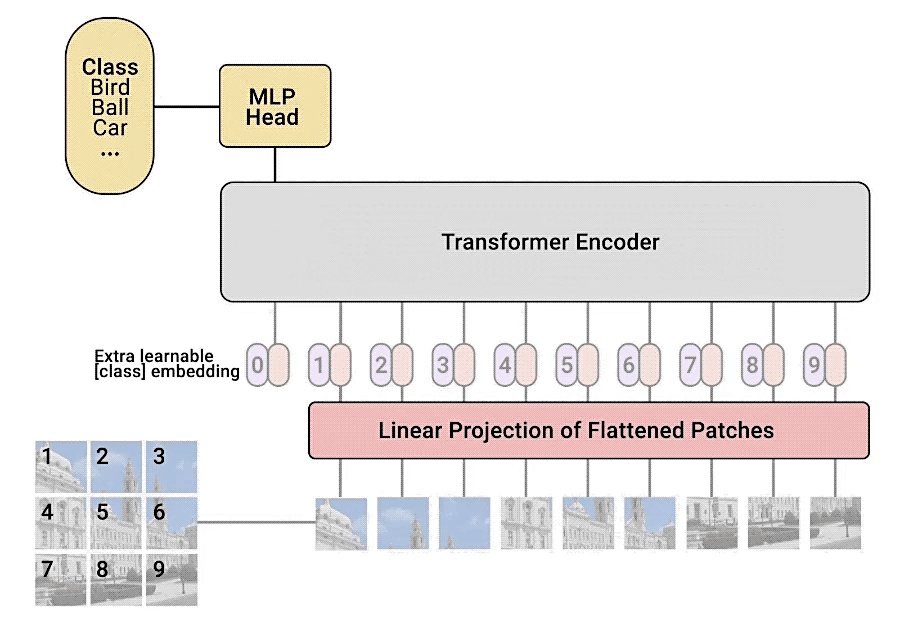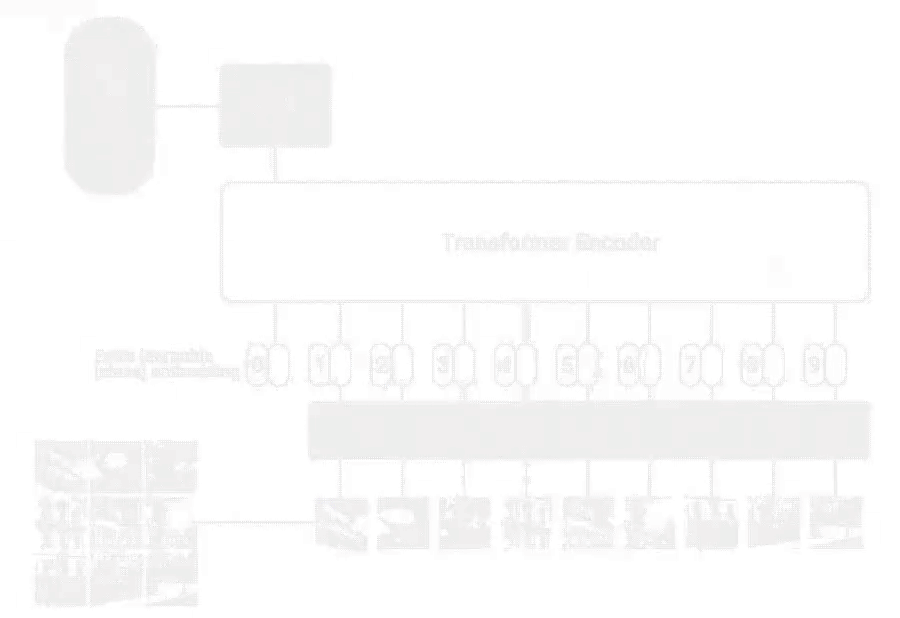
Vistion Transformer은 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale으로 구글에서 2020년 10월 20일날 발표된 논문이다 이미지 분류에 Transformer을 사용
2023년 3월 26일
5.[Seq2Seq 논문리뷰](Sequence to Sequence Learning with Neural Networks)

Seq2Seq에 대한 논문 리뷰입니다. 다만 PDF파일이라 첨부가 불가하여 Github링크를 첨부했습니다.
2023년 3월 26일