KLUE-YNAT

KLUE-YNAT의 데이터는 연합뉴스 기사 제목으로 구성된 데이터이다.
부스트캠프 Data-Centric에서는 데이터의 일부가 P2G데이터로 구성되있으며 임의로 label을 다르게 추가하였다.
이를 원상으로 복구하기 위한 모델을 개발하고 오픈소스로 배포하였다. 또한 데이터를 증강하기 위해 뉴스의 topic을 넣으면 뉴스 기사를 생성하는 생성 모델을 만들어 배포하였다.
복원 모델
Text : 석유왕국 사우디 태양광·풍력 발전 중심지 될 것
P2G Text : 서규왕국 싸우디 태양광·풍녁 빨쩐 중심지 될 껃
탐지 모델
G2P Text : 월드커 파나은행 대표티메 행우늬 이달러 이영영장 선물
Label : 1
생성 모델
Text : IT과학
Generate Text : SK텔레콤 스마트 모바일 요금제 시즌1 출시
kfkas/t5-large-korean-P2G
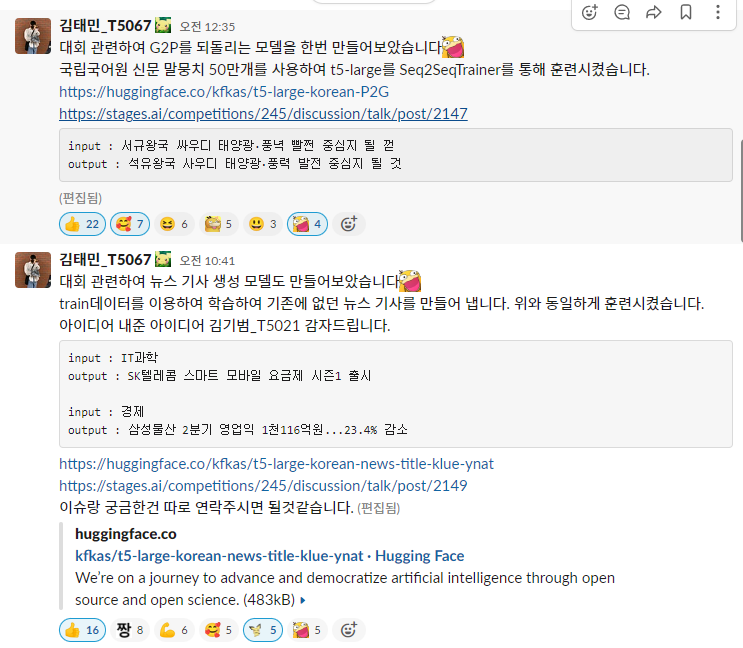
문장을 복원하기 위하여 Text2Text Generation Model을 선택하였다. 기존의 TextGeneration Model 같은 경우는 Fine-tuning을 진행하여도 문장이 제대로 생성되지 않았으며 일정한 규칙으로 생성되지 않았다. 질의응답 같은 Task나 추가적인 문장을 생성해내는 Task의 경우 적합하다. Text2Text Genration Model은 번역이나 일정한 규칙으로 보다 더 잘생성되며 Text가 Input인만큼 Text2Text Genration Model인 t5-large 모델을 선택하여 Seq2Seq Trainer을 사용하여 입력으로는 P2G 문장 타겟으로 원본 문장을 지정하여 Fine-tuning을 진행하였다.
Pre-train Model : lcw99/t5-large-korean-text-summary
Fine-tuing Model : kfkas/t5-large-korean-P2G
Data : 국립국어원 신문 기사 말뭉치 50만개
Trainer : Seq2SeqTrainerfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM model_dir = "kfkas/t5-large-korean-P2G" tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForSeq2SeqLM.from_pretrained(model_dir) text = "서규왕국 싸우디 태양광·풍녁 빨쩐 중심지 될 껃" inputs = tokenizer.encode(text,return_tensors="pt") output = model.generate(inputs) decoded_output = tokenizer.batch(output[0], skip_special_tokens=True) print(decoded_output)#석유왕국 사우디 태양광·풍력 발전 중심지 될 것

kfkas/t5-large-korean-news-title-klue-ynat
Topic을 입력으로 넣을시 Topic과 관련된 뉴스기사 제목을 생성하기위해 마찬가지로 lcw99/t5-large-korean-text-summary모델을 Fine-tuning하여 진행하였다. 데이터로는 klue-ynat 데이터에서 입력을 topic 타겟을 뉴스 제목으로 지정하여 훈련시켰다.
Pre-train Model : lcw99/t5-large-korean-text-summary
Fine-tuing Model : kfkas/t5-large-korean-news-title-klue-ynat
Data : 국립국어원 신문 기사 말뭉치 5만개
Trainer : Seq2SeqTrainerfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model_dir = "kfkas/t5-large-korean-news-title-klue-ynat" tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForSeq2SeqLM.from_pretrained(model_dir) model.to(device) label_list = ['IT과학','경제','사회','생활문화','세계','스포츠','정치'] text = "IT과학" input_ids = tokenizer.encode(text,return_tensors="pt").to(device) with torch.no_grad(): output = model.generate( input_ids, do_sample=True, #샘플링 전략 사용 max_length=128, # 최대 디코딩 길이는 50 top_k=50, # 확률 순위가 50위 밖인 토큰은 샘플링에서 제외 top_p=0.95, # 누적 확률이 95%인 후보집합에서만 생성 ) decoded_output = tokenizer.batch_decode(output, skip_special_tokens=True)[0] print(decoded_output)#SK텔레콤 스마트 모바일 요금제 시즌1 출시
https://huggingface.co/kfkas/t5-large-korean-news-title-klue-ynat

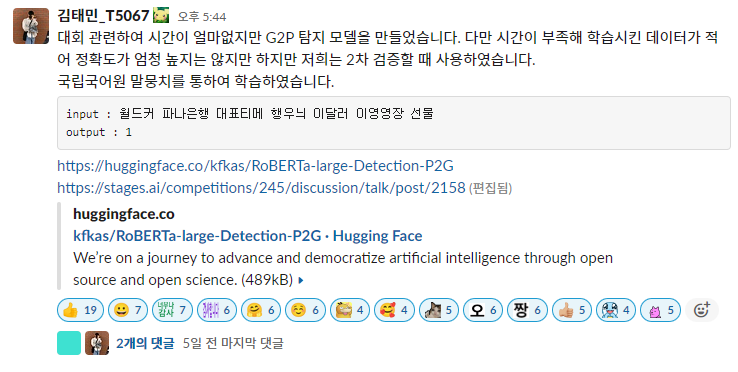
kfkas/RoBERTa-large-Detection-P2G
P2G 데이터를 탐지하기 위해 만든 모델이다. Text 데이터를 이진분류로 수행하여 탐지하게 된다.
원래는 label=1로 진행하여 임계값으로 탐지 강도를 조절 할수 있게 만들어야하지만 이 모델은 급하게 만들다보니 생각없이 label=2로 진행하여 학습을 진행하였다. 데이터의 경우 원본 Text 데이터를 G2P Text로 변환시키는 g2pk 라이브러리를 사용하여 원본데이터는 label=0 g2p로 변환된 데이터는 label=1로 지정하였다. 이로써 이진분류를 학습시키고 Pre-train은 모델은 이미 Klue 데이터에 훈련되어있는 klue/roberta-large를 분류 문제로 바꿔 학습을 진행하였다.
Pre-train Model : klue/roberta-large
Fine-tuing Model : kfkas/RoBERTa-large-Detection-P2G
Data : Klue-ynat
Trainer : Trainerfrom transformers import AutoTokenizer, RobertaForSequenceClassification import torch import numpy as np device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model_dir = "kfkas/RoBERTa-large-Detection-P2G" tokenizer = AutoTokenizer.from_pretrained('klue/roberta-large') model = RobertaForSequenceClassification.from_pretrained(model_dir).to(device) text = "월드커 파나은행 대표티메 행우늬 이달러 이영영장 선물" with torch.no_grad(): x = tokenizer(text, padding='max_length', truncation=True, return_tensors='pt', max_length=128) y_pred = model(x["input_ids"].to(device)) logits = y_pred.logits y_pred = logits.detach().cpu().numpy() y = np.argmax(y_pred) print(y) #1

개발 후기
처음에는 다른 방법을 많이 시도하였지만 모델을 개발해서 전처리를 수행하고 모두에게 배포하면 어떨까?라는 생각이 들었다. 오픈소스의 마음가짐으로 수행하였으며 Slack에서 모두에게 배포한 결과 좋은 반응을 얻어냈으며 몇몇의 분들에게 어떻게 만들었지는 질문도 오고 답변을 해주며 코드도 공유해주었다. 특히 P2G의 모델같은 경우 다운로드수가 700이 넘는 기염을 토해내며 현대 캐피탈의 과장님 또한 모델에 좋아요를 누르셨다.
앞으로도 딥러닝 모델을 개발할 시 많은 사람들이 쓸수있게 배포를 해야겠다.
