[BoT](Body Transformer: Leveraging Robot Embodiment for Policy Learning)
1. 논문이 다루는 Task
Task: Reinforcement Learning
- Input: Robot Sensor data
- Output: Action
2. 기존 연구 한계
2-1. Limitations of Transformer Architectures in Robotics
기존 Transformer 구조는 vision과 NLP에서 혁신적인 성과를 이루었고, 그 성공을 바탕으로 다른 도메인에서도 반복적으로 활용되고 있다. 특히, 이미지나 텍스트와 같은 데이터 모달리티를 다룰 때 Transformer 모달리티에 맞게 수정 사용되고, 일부 연구에서는 로봇 공학 분야에도 적용하려는 시도가 있었다. 그러나 기존 Transformer 구조는 로봇의 센서와 액추에이터가 가진 물리적 관계나 공간적 특성을 제대로 반영하지 못한다는 한계가 있다. 저자들은 이로 인해, 로봇의 고유한 신체 구조를 효과적으로 학습에 반영하지 못한다고 주장한다.
2-2. Challenges in Utilizing Body Structure for Policy Learning
정책 학습에서 로봇의 신체 구조를 충분히 활용하기 위한 시도는 주로 GNN을 통해 이루어져 왔다. GNN을 활용하면 로봇의 다양한 멀티태스크 정책을 학습할 수 있지만, 이 접근 방식은 모델이 깊어질수록 과도한 Oversmoothing과 Oversquashing 문제로 인해 장거리 관계를 학습하는 데 어려움을 겪는다고 주장하였다.
또한, 트랜스포머 기반 GNN이 정책 학습에 활용된 경우에도, 완전 연결 어텐션(Fully Connected Attention) 구조는 주로 구조적 정보가 없는 텍스트나 이미지 데이터를 처리하는 데 최적화되어 있어, 로봇의 신체적 구조를 반영하는 데 한계가 있다.
3. 제안 방법론
3-1. Body Transformer
Body Transformer의 구조는 Attention 메커니즘의 변환부터 시작하여 Transformer 구조에 로봇 구조에 따른 indutive bias를 부여하는 과정으로 정리된다.
Vanilla Transformer
기존의 어텐션 메커니즘은 위와 같으며 와 의 dot product 이후 의 차원 수가 커질수록 내적 값이 커지기 때문에 스케일링을 위해로 나누어준 후 함수로 attention map을 통해 연관성을 추출한다. 이후 를 곱해주어 실제 값을 적용시키며 이를 반복한다.
GNNs Transformer
이를 Transformer-based GNNs 위와 같이 변형하여 사용한다. 이때 B는 학습 가능한 매트릭스로 bias 매트릭스이다. 인접 행렬 구조를 통해 그래프 구조로 를 정의하여 관계를 보게된다. 수식에서 에 를 더해줌으로써 각 노드가이웃 노드와의 관계를 반영할 수 있도록 해준다. 이를 통해 모든 노드(실제로 NLP 에서는 Token)가 서로 Attnetion 하는 기존 Transformer 대신 특정한 관계를 가진 노드 쌍에 더욱 많은 attention을 가하여 그래프 구조에 맞춘 어텐션을 완성하게 된다.
Body Transformer
Body Transformer는 로봇의 신체 구조를 반영하여 설계된 트랜스포머 아키텍처로, GNNs Transformer의 구조에 Masked Attention과 identity matrix 를 추가하여 로봇의 특성을 잘 표현하도록 한 모델이다. 기본적으로 Body Transformer는 각 노드가 자기 자신과 직접 연결된 이웃 노드와만 상호작용할 수 있도록 Masked Attention을 적용한다. 또한, 각 노드가 자기 자신에 대한 정보를 항상 참조할 수 있도록 identity matrix 를 추가해 자기 자신의 정보 손실을 방지한다.
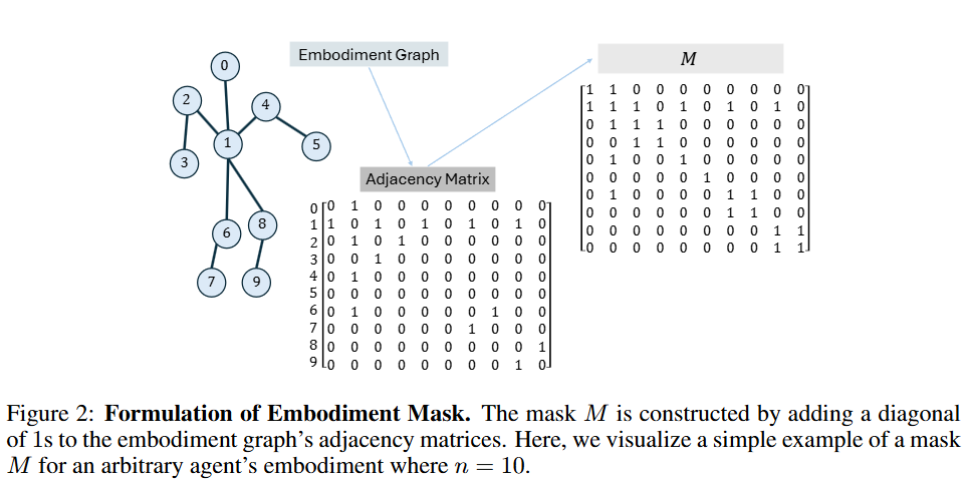
Body Transformer의 매트릭스는 GNNs Transformer에서 일반적인 그래프 구조를 표현하는 역할을 하는 것과 달리, 로봇의 신체 구조를 그래프 방식으로 직접적으로 표현한다. 이를 위해 매트릭스는 학습 불가능하게 설정되며, 로봇 구조의 특성을 반영하여 고정된 마스킹 방식으로 구성된다. 결과적으로, 로봇의 각 관절과 액추에이터는 노드로, 관절 간의 연결은 엣지로 표현되어 Figure 2와 같은 형태의 그래프 구조가 형성된다. 이를 통해 Body Transformer는 로봇의 신체 구조에 맞춘 정보 교환을 수행하며, 각 관절 간의 관계를 반영한 학습이 가능해진다.
3-2. Tokenizer and Detokenizer
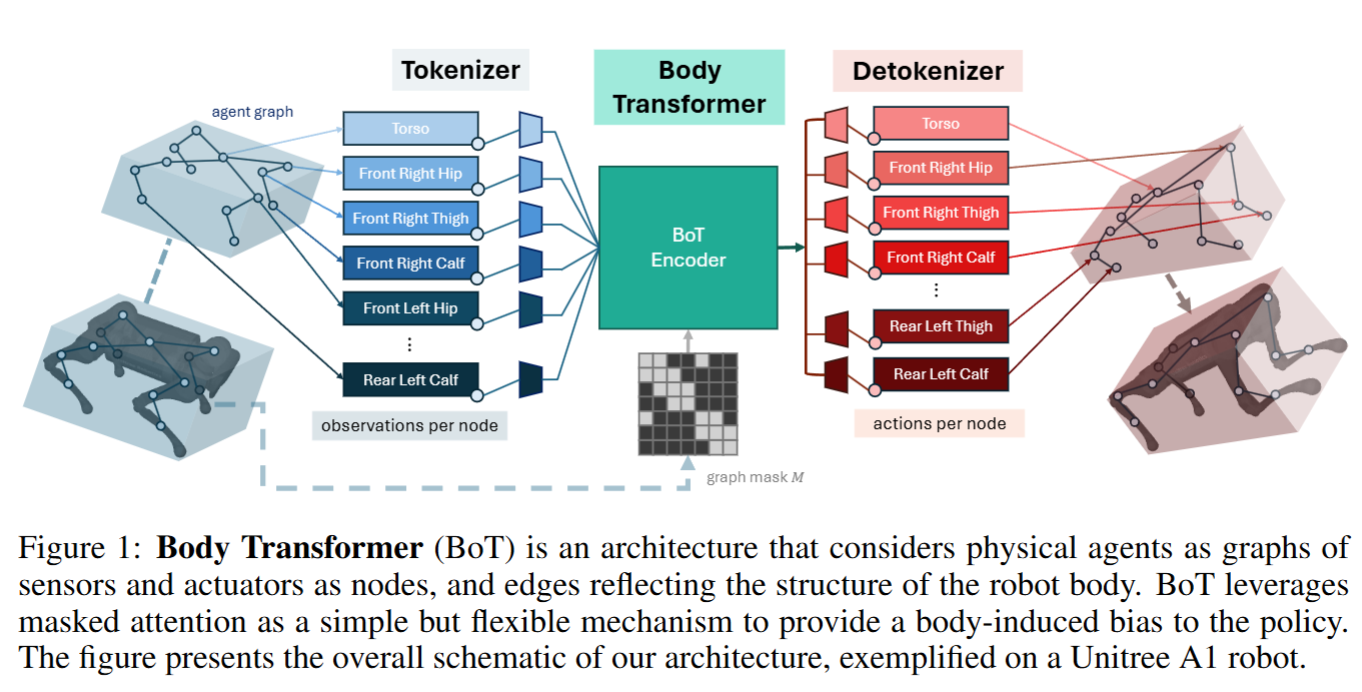
실제 입력에 대한 Tokenizer와 Action에 대한 Detokenizer의 역할을 알아본다. 그림에 따르면 Tokenizer는 로봇의 각 노드(센서와 액추에이터)의 위치에 맞는 입력을 받아 Body Transformer에 입력된다. 이 과정에서 고정된 크기의 N (시퀀스 길이, 즉 Seq_len 또는 node 수) 입력을 형성하며, 이 입력은 로봇의 각 관절이나 부위에 해당하는 정보로 구성된다.
이 정보들은 센서 데이터를 예시로 Discrete한 Token이 아니기 때문에 continuous 토큰으로 각각의 Linear을 통해 투영된다. (후에 VQ-VAE를 이용한 Discreate 토큰이 나왔으면 좋겠다.) 이는 결국 각 노드 정보는 토큰으로 정보가 취합되며 이를 입력으로 받아들이게 된다.
Detokenizer는 실제로 Body Transformer의 출력으로 입력과 동일한 N개의 토큰을 가지게 된다. 이에 대해 마치 BERT의 CLS Token의 MLP를 모든 토큰 N에 대해서 달게된다. 즉 로봇의 행동을 결정하기 위해선 각각 별도의 토큰마다 MLP 레이어가 삽입되어 각각의 로봇의 노드마다 독립적으로 Action을 결정하게 된다.
따라서, Tokenizer는 연속적인 센서 데이터를 개별적인 노드 임베딩으로 변환하여 Body Transformer에 입력하며, Detokenizer는 각 노드의 임베딩을 개별적으로 처리해 액션을 출력하도록 설계되었다.
3-3. BoT Encoder structure
논문에서는 BoT Transformer의 구조를 아래와 같이 셋팅하여 실험하였다.
BoT-Hard
BoT Trnasformer를 그대로 사용하며 모델의 레이어에 모두 적용한다. 이를 통해 지역적인 정보에 집중하여 로봇의 구조를 최대한 반영시킨다.
BoT-Mix
BoT Transformer를 구성할때 Masking Attention layer와 mask가 없는 레이어를 번갈아가며 모델을 구성하게된다. 이렇게 반복적으로 사용하면 정보가 점차 지역적->전역적을 반복하며 확장ㅇ된다. 이는 더 넓은 문맥에서 로봇의 지역적 정보와 전역적 정보를 잘 결합하여 로봇의 신체 구조를 학습하는데 도움이 된다.
이 두 가지 설정을 통해 로봇의 물리적 구조를 반영한 정보 흐름 방식이 정책 학습에 미치는 영향을 실험적으로 분석하였다.
4. 실험 및 결과
-
Does masked attention benefit imitation learning in terms of performance and generaliza-
tion? -
Does BoT exhibit a positive scaling trend compared to a vanilla transformer architecture?
-
Is BoT compatible with the RL framework, and what are sensible design choices to maxi-
mize performance? -
Can BoT policies be applied to a real-world robotics task?
-
What are the computational advantages of masked attention?
저자들은 위와 같은 질문을 구성하여 답을 하는 것을 목표로 구성하였다.
BoT Transformer 구조의 성능 입증을 위해 사용된 주요 모델들은 encoder의 구성을 바꿔 실험하였다.
MLP, vanilla unmasked transformer encoder,
BoT-Hard, BoT-Mix
4-1. Imitation Learning Experiments
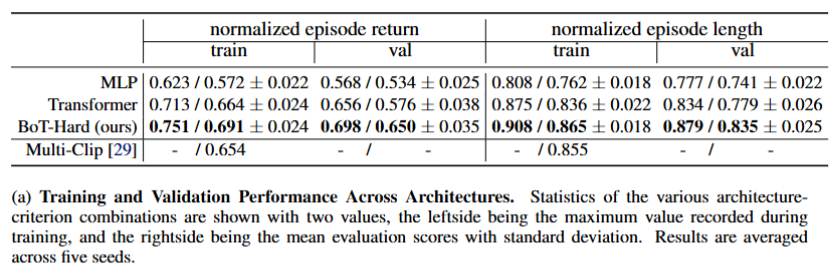
MoCapAct 데이터셋을 사용하여 Body Transformer의 모방 학습 성능을 평가하였다. MoCapAct는 모션 캡처 데이터를 기반으로 다양한 동작이 포함된 데이터셋으로, 각 샘플은 액션 레이블로 구성되어 있어 로봇이 전문가의 동작을 모방할 수 있는 환경을 제공하게된다.
(a)의 결과로 MLP, Transformer보다 BoT-Hard가 높은 성능을 보여준다 또한 Train에서의 격차보다 val 에서의 격차가 더욱 증가하였는데 이는 보다 성공적인 일반화과 되었다고 볼수있다고 한다.
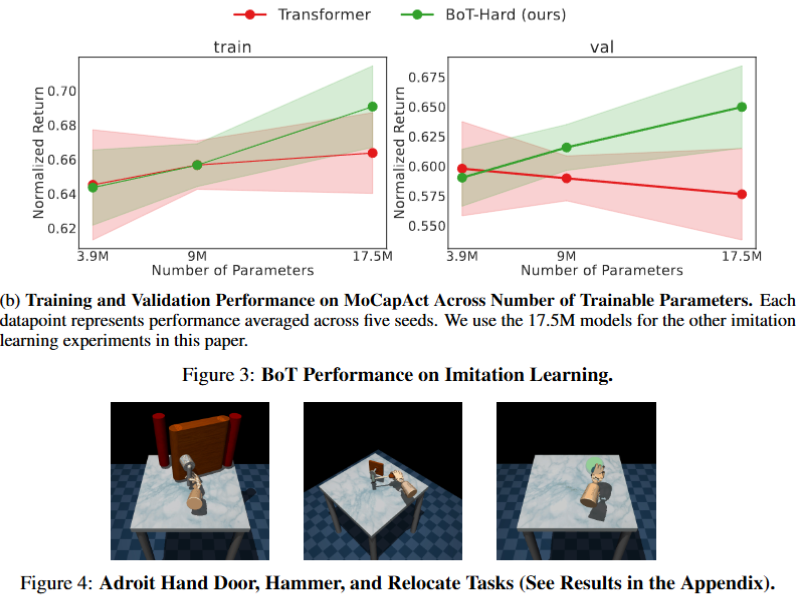
(b)에서는 Parameters를 증가시켰을때 성능 성능 변화율 추이를 분석하였다. BoT-Hard는 Transformer보다 비교적 파라미터가 증가하였을때 성능이 보다 증가하였다. 특히 val에서는 Transformer는 과적합으로 인해 val의 성능이 감소하지만 BoT-Hard는 성능이 지속적으로 증가하여 과적합을 감쇠하는 추세를 보여주었다. 이는 inductive bias(embodiment bias)의 영향이라고 분석하였다.
4-2. Reinforcement Learning Experiments
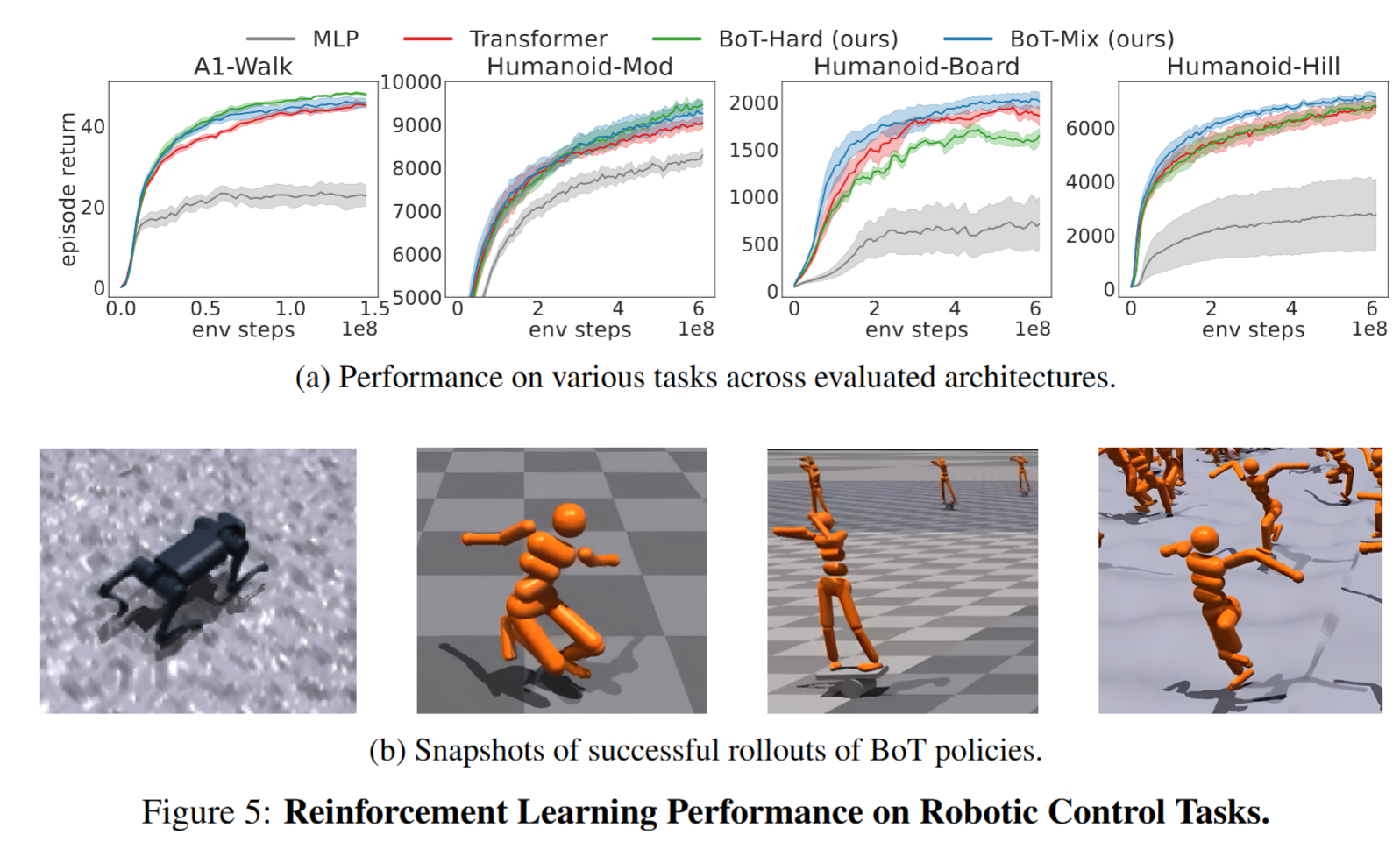
Body Transformer의 성능을 검증하기 위해 RL인 PPO(Proximal Policy Optimization)를 사용하여 4가지 로봇 환경에서 학습을 진행했다. 실험 데이터는 Isaac Gym을 통해 제공되는 Humanoid-Mod, Humanoid-Board, Humanoid-Hill, A1-Walk 환경으로 구성되어 있다.
- Humanoid-Mod: 로봇이 평지에서 달리는 작업을 수행하는 환경이다.
- Humanoid-Board: 로봇이 원통 위에 올라가 균형을 유지하며 움직이는 작업을 수행하는 환경이다.
- Humanoid-Hill: 곡면 지형에서 달리는 작업을 수행하는 환경으로, 평지가 아닌 지형에서의 이동 능력을 평가한다.
- A1-Walk: 사족 보행 로봇인 Unitree A1이 주어진 속도 명령에 따라 이동하는 작업을 수행하는 환경이다.
실험결과 (a)에서 BoT는 모든 부분에서 MLP와 Transformer에 비해 일관적으로 성능이 향상된 부분을 볼수 있다. 하지만 BoT-Hard의 경우 Humanoid-Board와 Humanoid-Hiil에서는 비교적 Transformer보다 감소된 성능을 보여준다.
논문의 저자들은 이를 BoT-Hard의 경우 마스크가 모든 레이어에 적용되어 기존 RL의 탐색을 강한 Inductive bias가 방해한다고 주장한다. 이러한 부분은 작업이 불규칙적으로 변하며 어려운 환경이어서 성능이 감소된다고 본다. 그에 맞게 BoT-Mix는 이러한 작업에서 보다 성능이 높다.
하지만 단순한 작업인 Humanoid-Mod와 A1-Walk는 환경에서 규칙적이므로 보다 강한 Inductive bias를 가지는 BoT-Hard가 빠르게 학습할 수 있다고 주장한다.
(이는 CNN이 공간적인 Inductive bias를 가지고 있는 반면 Transformer는 Inductive bias가 적어 대규모의 학습 데이터가 필요한다는 점과 일치하다고 '나는' 생각한다.)
4-3. Computational Analysis
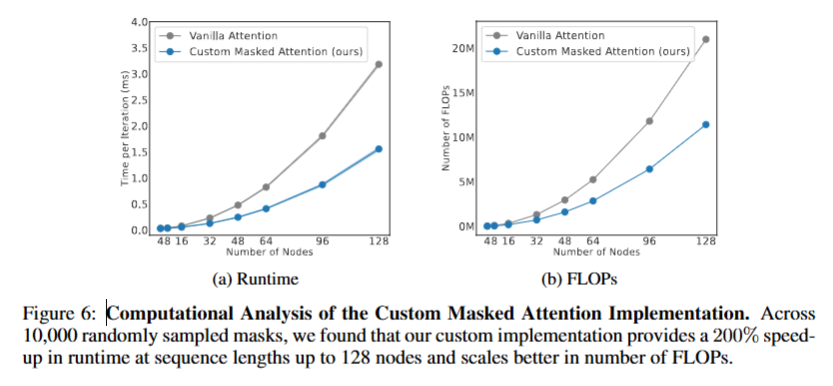
Computational Analysis에서는 Body Transformer의 계산 효율성과 성능을 분석하여 기존 모델 대비 개선된 점과 한계를 평가한다.
Body Transformer는 로봇의 신체 구조에 맞춘 마스킹된 어텐션과 특화된 토크나이저 구조를 통해 불필요한 계산을 줄이고 연산 효율성을 높이는 구조를 갖춘다. 이를 통해 자원 소모를 줄이며 계산 속도를 개선할 수 있음을 보인다.
Figure 6의 결과에 따르면, Body Transformer는 시퀀스 길이(노드 수)가 증가할수록 Vanilla Attention 대비 성능에서 큰 개선을 보이며, 최대 128개의 노드에서 206%까지 속도 향상을 달성할 수 있었다. 이 성능 향상은 특히 많은 노드를 다루는 환경(예시: 정밀한 손동작이 필요한 휴머노이드)에서 더욱 두드러진다. 이러한 결과는 BoT의 inductive-bias가 성능을 향상시킬 뿐만 아니라, 마스크를 적용해 효율적인 계산이 가능함을 보여준다.
5. Conclusion
본 연구에서는 로봇의 신체 구조를 inductive bias로 반영하여 설계된 새로운 그래프 기반 정책 아키텍처인 Body Transformer (BoT)를 제안하였다. 이렇게 로봇의 물리적 구조를 효과적으로 반영하여 효율적으로 정보 교환을 가능하게 하였으며 과한 inductive bias를 막기위해 Hard, Mix 방법을 제안하였다.
또한 본 연구에서는 정보들은 각 시간 단계로 나누어 처리허였지만 시간 축으로 확장하는 연구를 향후 과제로 남겨두었으며 이를 통해 실제 로봇 환경에서의 성능을 개선할 가능성이 있다고 주장하였다. 특히, Unitree A1 로봇과 같은 실제 응용 환경에 최적화된 정책 학습을 지원할 수 있을 것으로 기대된다.
