BERT
BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 2018년에 발표한 언어 모델로, Transformer 아키텍처를 기반으로 하고 양방향(bidirectional) 학습을 사용하여 이전의 모델보다 더 좋은 성능을 보이는 모델이다. 큰 양의 텍스트 데이터를 사용하여 사전 학습(pre-training) 되며, 이후 특정 자연어 처리(natural language processing) 작업에 fine-tuning하여 사용할 수 있다.
BERT의 모델 구조
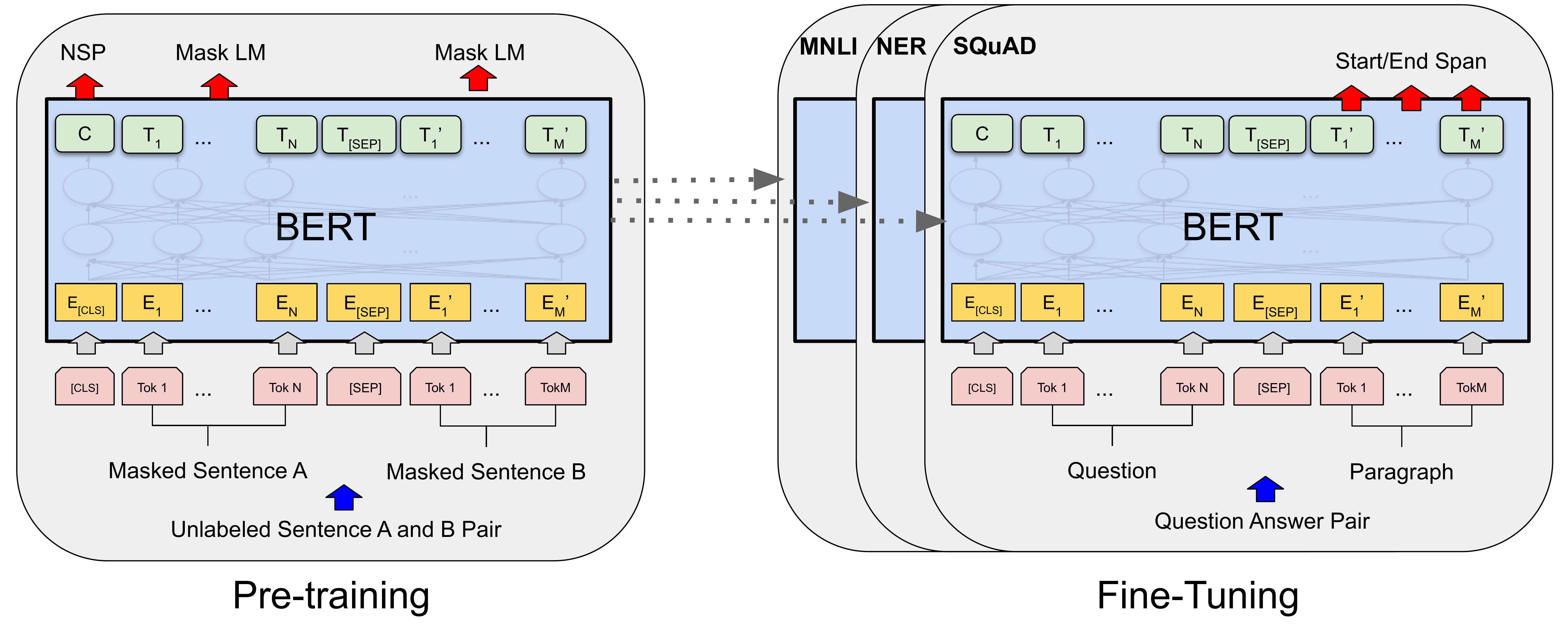
BERT의 모델 구조는 위와 같으며 Transformer의 인코더 구조만을 채택하였다. Pre-training 방법은 Masked Language Model(MLM)과 Next Sentence Prediction(NSP) 로 두가지 학습 방법을 사용하였다.
Masked Language Model(MLM)
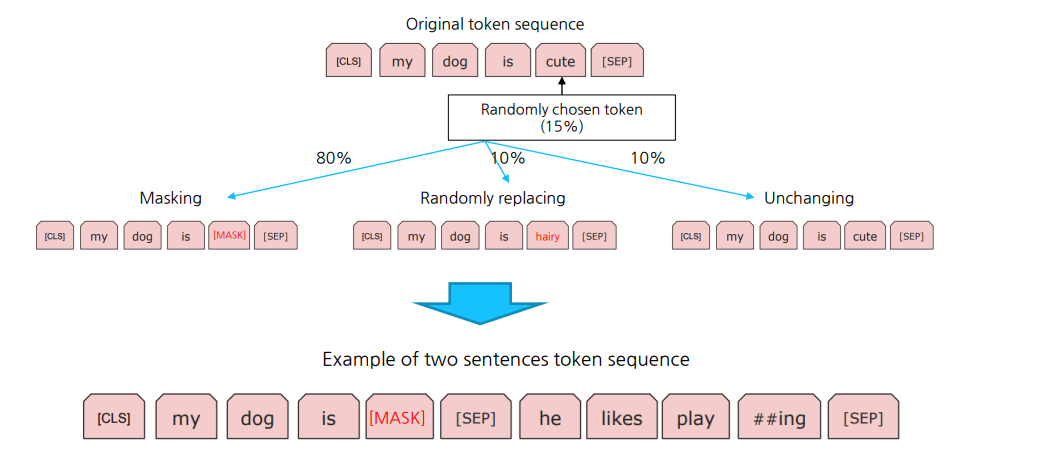
MLM은 입력 문장에서 랜덤하게 일부 단어를 마스크하고, 해당 단어를 예측하는 것으로 학습하며 이때 3가지 유형의 마스크를 사용하게 된다. MLM 방식으로 문장의 문맥을 이해하며 단어의 의미를 파악하는 능력을 학습하게 된다. 마스킹 방식은 아래와 같다.
전체 토큰 중 15%를 랜덤하게 고른다. 이때 15% 중에서도 3가지 유형으로 마스킹을 진행한다.
첫 번째 유형: 입력 문장에서 랜덤하게 일부 단어를 마스크하는 경우, 이 유형의 확률은 80%이다.
두 번째 유형: 일부 단어를 마스크하는 대신 랜덤하게 다른 단어로 대체하는 경우, 이 유형의 확률은 10%이다.
세 번째 유형: 마스크하지 않고 그대로 둔 단어를 임의의 확률로 마스크하는 경우, 이 유형의 확률은 10%이다.
Next Sentence Prediction(NSP)
NSP는 두 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지 아닌지를 예측하는 것으로 학습한다. 이를 통해 모델은 문장과 문맥의 의미를 파악하는 능력을 배우게 된다. 이때 문장의 유형은 2가지이며 50%의 확률로 결정된다. 유형은 아래와 같다
첫 번째 유형: 첫 번째 문장과 두 번째 문장은 원본 문장의 이어지는 문장이다.
두 번째 유형: 첫 번째 문장과 두 번째 문장은 원본 문장에서 이어지지 않는 관계 없는 문장이다.
BERT Embedding
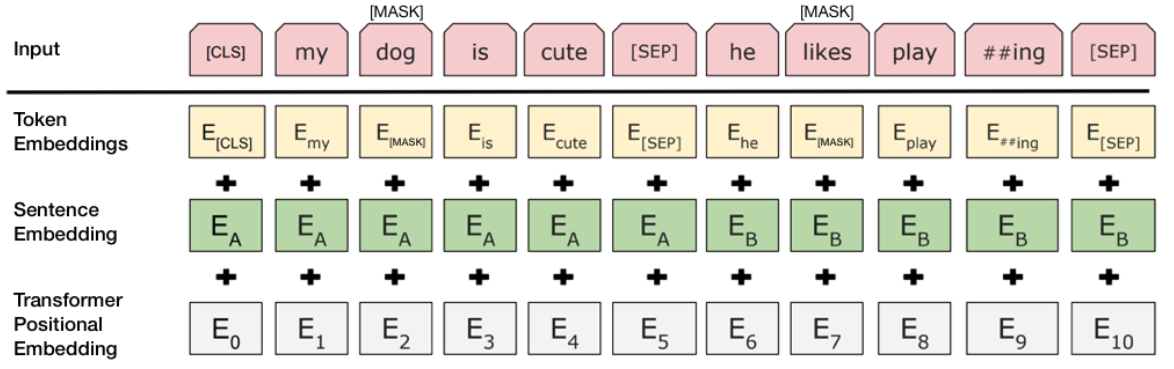
BERT의 Embedding 레이어는 기존의 Layer에 비해 Sentence레이어가 추가되었다. 이는 NSP를 학습할 때 첫번째 문장과 두번째 문장을 구별하기 위해 사용되는 Embedding Layer이다. 추후 모든 레이어를 단순히 Sum하여 Encoder의 입력으로 넣는다.
BERT Encoder
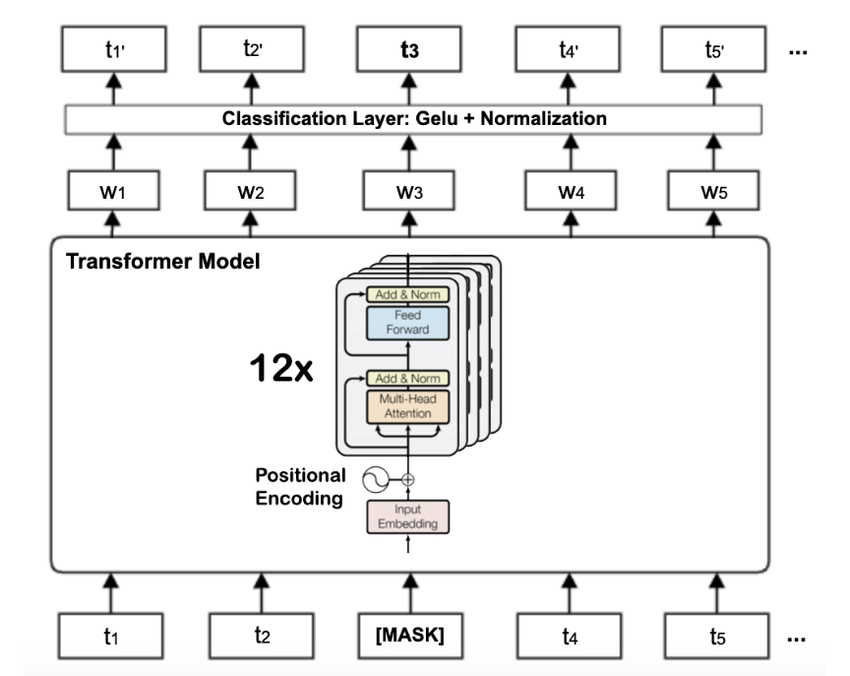
BERT의 Encoder는 기존의 Transformer과 동일하다. 이때 w1은 [CLS] token으로써 추후 소개할 많은 작업에서 주로 사용되는 토큰이다.
BERT NLP TASK
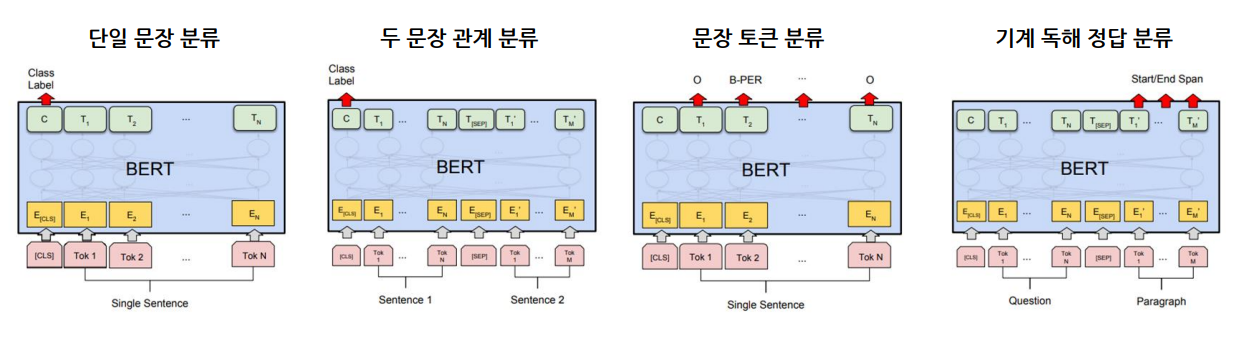
현재 간단하게 소개할 TASK는 4가지이며 각 TASK는 추후 글에서 상세하게 설명하겠다.
BERT 단일 문장 분류
입력으로 1개의 문장을 넣는다. 이때 최종 [ClS] token 위에 Classification layer을 추가함으로써 최종적으로 나온 [CLS] token을 통과시켜 분류 문제를 해결한다.
주요 예시) 감성 분석, 관계 추출
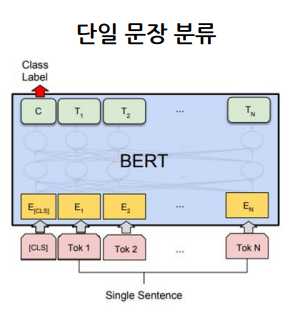
BERT 두 문장 관계 분류
입력으로 2개의 문장을 [SEP] token 기준으로 입력을 넣는다. 이때 [SEP] token은 서로 다른 문장임을 명시시켜주는 token이다. 2개의 문장의 경우 Embedding Layer의 Sentence Embedding의 입력이 서로 다르게 들어가게 된다.
마찬가지로 [ClS] token 위에 Classification layer을 추가함으로써 최종적으로 나온 [CLS] token을 통과시켜 분류 문제를 해결한다.
주요 예시) 의미 비교
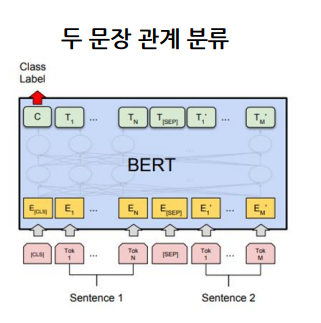
BERT 문장 토큰 분류
입력으로 1개의 문장을 넣고 이때 [CLS] token뿐만 아닌 문장의 모든 token을 대상으로 Classification layer 추가하고 통과시키며 이를 각각의 클래스로 분류 한다.
주요 예시) 개체명 분석
BERT 기계 독해 정답 분류
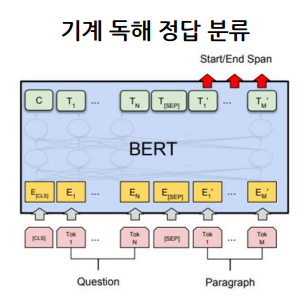
입력으로 문장에서 찾을 질문과 전체 문장이 [SEP] token을 기준으로 입력이 들어가게 된다. 출력으로 start positions와 end_positions가 나오게 된다. 이는 문장 내에서 위치 범위를 나타낸다. 최종적으로 모든 토큰들의 정보를 취합하여 Classification layer를 통과시킨다. 이때 Classification layer는 클래스가 start positions과 end poisitons으로 총 2개의 클래스이다.
회고
요새 너무 바빠서 글을 잘 못쓰는것 같다. 또한 제목의 양식 또한 몇일차로 기록하다보니 보기가 매우 불편하다.
다음부터는 지금처럼 공부한 내용을 바탕으로 제목을 지정하는편이 조금 더 좋은 것 같고. 2일에 하나씩은 블로그 글을 올리는게 좋아보인다. 최근 대회를 진행하며 Custom BERT를 만드는중인데 쉽지는 않지만 성공해내서 다행이다.
