[머신러닝]
1.[머신러닝] 머신러닝 개요, 선형 회귀

AI의 종류 시각적 인지 음성 인식 Decision Making 머신러닝 > 경험으로부터 자동적으로 학습, 성능을 향상시켜 나가는 학문 지도학습 데이터가 라벨링 되어 있음 Classification, 선형회귀, 로지스터 회귀 비지도학습 데이터 라벨링 X 데이터의
2.[머신러닝] 이진분류
데이터를 2가지로 나누는 분류예측함수를 선형회귀로 구하면 오차가 클 확률이 높음.그래서 완만한 곡선으로 이진 분류를 위한 예측함수를 선정함 -> 로지스틱 회귀함수의 값이 크면 클수록, 그 쪽일 확률이 높다.Sigmoid Function으 값이 0.5 이상 혹은 자연상
3.[머신러닝] 생물학적 뉴런과 두뇌
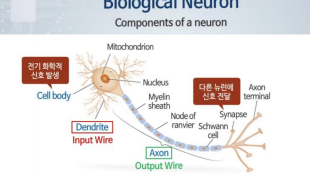
컴퓨터 비전과 같은 분야에선 예측함수로는 올바른 분석이 어려움따라서 굉장히 복잡한 비선형 가설 예측함수가 필요함하지만 굉장히 복잡한 다항식으로 이를 다 처리하기엔 연산량, 파라미터 개수가 너무 많음생물학적 뉴런들은 전기화학적 신호를 통해 정보를 주고 받음One Lear
4.[머신러닝] 예측함수
예측함수가 뽑아내는 출력 값이 실제 값에 가까운 경우가 자주 있을수록, 좋은 모델이라 할 수 있음.예측함수 모델을 개선시키기 위해선 6가지를 해볼 수 있음1) 더 많은 데이터를 수집2) 더 적은 특징 값을 수집(overfitting 방지)3) 더 많은 특징 값을 사용4
5.[머신러닝] SVM, K-means 알고리즘
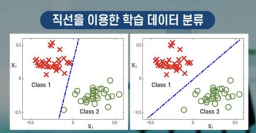
오른쪽의 그래프가 더 큰 마진을 가지고 분류하기 때문에 새로운 데이터를 더 잘 분류할 것.SVM(Support Vector Machine) : 곡선을 직선으로 근사화 한 것SVM은 직선의 형태이기 때문에, 계산량 면에서 많이 유리함강의에선 로지스틱 회귀에 사용되는 si