H-Index
위 문제는 이번에 다시 풀어서 성공할 수 있었다. 이럴때마다 보람을 느낀다..! 그래도 이전에는 일단 코드부터 짜고봤는데
그것보다 지금처럼 생각을 해보고 코드를 짜는 방법이 더 효율적인거 같다.
위 문제는 사실 문제를 이해하는 게 더 중요했다. 필자는 n 편 중 h번 인상인데
여기서의 n을 배열 내부의 원소로 이해해서 시간이 좀 더 걸렸다.
나의 처음 로직은 다음과 같다.
- 배열을 sort함수를 활용해 정렬한다(내림차순)
- 이중 for문을 활용하여 배열을 순회하며 조건을 만족하면 바로 return 하도록한다.
- 조건은 다음과 같다.
- 원소보다 같거나 큰 숫자가 있으면 count up
- 위 count가 고정 원소보다 크고 배열의길이 - 카운트 ( h보다 작은 것들의 원소 수)가 고정 원소보다 작거나 같으면
return 하자
근데 문제를 자세히 보니 n편은 그저 배열의 길이가 됐다. 즉 1부터 배열의 길이까지 순회하여
조건에 만족하면 return하면된다. 최댓값을 구해야 함으로 1부터 배열을 순회하지않고 배열의 길이부터 1이 될때까지
순회하도록 만들었다.
코드는 다음과 같다.
function solution(citations) {
const arrLength = citations.length;
for (let i = arrLength; i > 0; i -= 1) {
let biggerCount = 0;
for (let j = 0; j < arrLength; j++) {
if (i <= citations[j]) {
// i보다 큰 원소가 있으면 count는 높인다
biggerCount = biggerCount + 1;
}
}
if (biggerCount >= i && arrLength - biggerCount <= i) {
// 누적된 count는 i(h)보다 크고 h보다 작은 원소 (인용수가 작은)의 수가 i(h)보다 작으면
// return 해준다.
return i;
}
if (biggerCount === 0) {
//인용이 안될 수 도 있어서 0인경우 0을 리턴한다.
return 0;
}
}
}다른 분들의 코드를 보니 H-Index를 구하는 공식이 있었다.
인용수 기준 내림차순 정렬 후
정렬된 상태에서의 논문 순서가 인용 수와 같거나 커지는 시점을 h index라고 한다
순서 >= 인용수
이를 이용해서 다음과 같이 풀 수 있다.
function solution(citations) {
citations = citations.sort(sorting);
let i = 0;
while(i + 1 <= citations[i]){
i++;
}
return i;
function sorting(a, b){
return b - a;
}
}괄호회전하기

위 문제를 풀 때는 두 가지의 로직이 필요했다.
- 괄호를 회전시킬 수 있어야한다.
- 올바른 괄호인걸 판단할 수 있어야한다.
괄호를 회전 시킬 때 마다 타당성검증을 할 수 있어야했다.
- 괄호를 회전시킬 수 있어야한다.
=> 이것은 굳이 array로 바꿔 풀지 않아도 될거라 생각했다.
slice 함수를 이용하여 처음 부분을 잘라내고 그 후 뒷 부분에 붙이면 괄호가 회전 된 것이기 때문이다.- 올바른 괄호인걸 판단할 수 있어야한다.
=> 이것은 Stack을 사용하여 문제를 해결하였다. {, (, [ 가 들어왔을 때 Stack array에 쌓고
stack array와 비교하며 문제를 해결해야겠다 생각했다.
이 문제는 과거에 풀었었다. 함수를 분리하여 풀었던 거 같다. 그런데 지금보니 불필요한 과정이 많이보인다.
function check(newArr) {
const checkArr = [];
newArr.forEach((item) => {
const lastIndex = checkArr.length - 1;
checkArr.push(item);
if (item === ")" && checkArr[lastIndex] === "(") {
checkArr.pop();
checkArr.pop();
}
if (item === "}" && checkArr[lastIndex] === "{") {
checkArr.pop();
checkArr.pop();
}
if (item === "]" && checkArr[lastIndex] === "[") {
checkArr.pop();
checkArr.pop();
}
});
return checkArr;
}
// 위 check 함수에서 pop을 굳이 두번하지않고 continue나 if else를 사용하여
// push와 pop을 적절히 사용했으면 더 좋았을 거 같다.
function spin(arr) {
const newArr = [];
const arrLength = arr.length;
for (let i = 0; i < arr.length; i++) {
const checkArr = [];
for (let j = 0; j < arr.length; j++) {
checkArr.push(arr[(j + i) % arrLength]);
}
newArr.push(checkArr);
}
return newArr;
}
// spin 함수는 굳이 array로 푸려고 하다보니 더 복잡해졌다.
// string 상태에서 바로 회전을 시켜줬다면 더 좋은 코드가 되었을 거 같다.
function solution(s) {
const arr = s.split(``);
let count = 0;
const newArr = spin(arr);
newArr.forEach((arr) => {
const checkArr = check(arr);
if (checkArr.length === 0) {
count = count + 1;
}
});
return count;
}좀 더 생각해보고 코드를 짜보았다. 많이 부족하지만 그래도 필자 나름의 풀이법은
function solution(s) {
let count = 0;
for (let i = 0; i < s.length; i++) {
const stack = [];
const first = s.slice(0, 1);
const last = s.slice(1);
s = last + first;
// 첫번 째 반복문에서 slice한 괄호를 합쳐 회전시켜주고
for (let j = 0; j < s.length; j++) {
// 회전된 괄호를 받아
if (
(stack[stack.length - 1] === "[" && s[j] === "]") ||
(stack[stack.length - 1] === "{" && s[j] === "}") ||
(stack[stack.length - 1] === "(" && s[j] === ")")
) {
stack.pop();
continue;
//stack에 넣고 타당성을 검증해줍니다.
}
stack.push(s[j]);
}
if (stack.length === 0) {
count = count + 1;
}
}
return count;
}위 코드 전에 if문을 3개로 나누어 각각 { [ ( 의 경우를 다르게 if문을 짰었는데 이는 효율성에 더 안좋았다. || && 연산자를 적극 활용하는 것이 효율성에서 더 좋은 점수를 받을 수 있다.
또한 continue를 사용하여 if else 문을 최대한 안쓰려 노력했다!
위의 stack.length-1로 하나의 변수로 저장하여 사용하는 것도 더 좋은 방법이 될 거같다.
캐시

다음 문제는 2018년 카카오 블라인드 채용 때 출제된 level2 문제이다.
이 문제는 Cashe와 관련된 문제인데 먼저 문제를 이해하는 부분에서 꽤 시간이 걸렸다..
(약 1시간만에품..)
이 전에 푼 기억이 있었지만 어떻게 풀었는지 모르겠다. 아마 꽤 오래 걸렸던 거 같은데 필자가 보기엔 지금의 코드가 더
나아보인다. 문제에서는 조금 잘렸지만 캐시의 교체 알고리즘은 LRU 알고리즘을 따른다고한다.
먼저 이를 이해하기 위해서는 구글의 도움이 필요했다.
Cahse의 LRU 알고리즘 정리 블로그
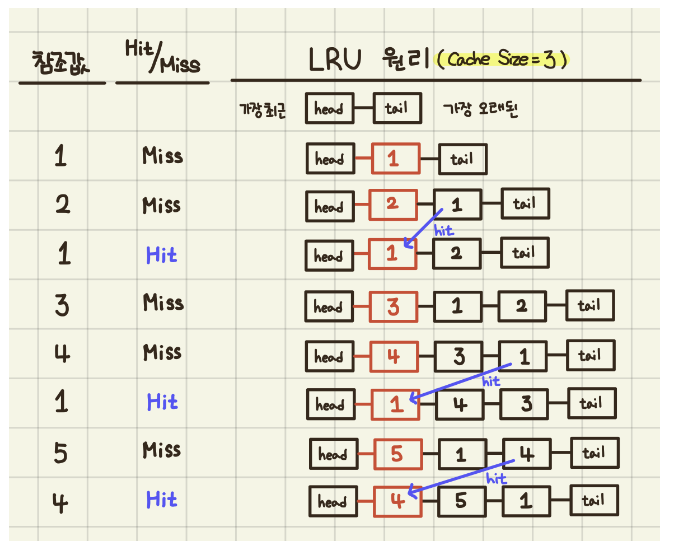
위 블로그에서 가져온 그림이다. 즉 LRU 알고리즘은 오래된 것은 교체되고 가장 최근의 값이 업데이트 되는 것이다.
처음 이 문제를 풀때는 그냥 맨 마지막 index에 있는 값이 새로 들어온 값과 같으면 pop, unshift를
이용해서 넣고 빼주면 되는 구나 생각했지만 3,1,2 에 중간에있는 1이 새로 들어온 값이라면 마지막 인덱스만으로
캐시를 정렬해줄 수 없다는걸 깨닳았다.. (늦게 깨닳았다..)
그렇게 내가 세운 로직은 다음과 같다.
- checkArr.length 가 cacheSize 보다 작을 경우 && 새로 들어오는 값이 checkArr에 없을 때만 checkArr에 unshift해주자
- 공통적으로 이미 checkArr에 값이 있다면 filter로 그값을 제거한 후 unshift 메서드를 통해 다시 최근 캐시로 업데이트해주자.
- checkArr에 값이 없고 checkArr.length가 cacheSize와 같거나 더 크다면 pop() 해준 후 해당 값을 unshift하여 캐시를 업데이트 해주자.
로직은 비교적 빨리세웠지만 마지막 한 부분에서 애를 먹었다. 어떤 부분에서 오류를 겪었는 지는 코드를 보며 정리해보겠다.
function solution(cacheSize, cities) {
if (cacheSize === 0) {
return cities.length * 5;
}
let checkArr = [];
let count = 0;
cities = cities.map((item) => item.toLowerCase());
for (let i = 0; i < cities.length; i++) {
if (checkArr.length < cacheSize && checkArr.includes(cities[i]) === false) {
checkArr.unshift(cities[i]);
count = count + 5;
continue;
}
if (checkArr.includes(cities[i])) {
count = count + 1;
checkArr = checkArr.filter((item) => item !== cities[i]);
checkArr.unshift(cities[i]);
continue;
}
count = count + 5;
checkArr.pop();
checkArr.unshift(cities[i]);
}
return count;
}필자는 continue문을 좋아한다. continue문을 사용하는 이유는 return없이 해당 값이 나오면 원하는 조건을 설정하고 계속 반복문을 이어나갈 수 있기 때문이다. 또 if문을 줄일 수 있는 거 같아 이를 많이 사용한다.
효율성이 좋은지는 잘모르겠지만 이 부분은 더 학습이 필요해 보인다.
필자가 애를 먹었던 부분은
for (let i = 0; i < cities.length; i++) {
if (checkArr.length < cacheSize && checkArr.includes(cities[i]) === false) {
checkArr.unshift(cities[i]);
count = count + 5;
continue;
}이 부분이다. checkArr.length와 cacheSize를 비교해야 체크하는 배열의 길이를 조절할 수 있는데
필자는 i< cacheSize 이렇게 비교를 했어서 계속 오류가 발생했다..
그런데 신기하게 테스트코드는 모두 다 통과를해서 꽤나 애를먹었다. 문제를 잘읽고 어떤 값과 비교가 되어야하는지 정리하는 연습이 필요하다!!
또, 다른 분들의 코드를 보며 배운 점은
unshift와 filter를 나누지 않고 filter로 오래된 값을 걸러준다면 if문이 줄어들 수 있다.
또한 filter 보다는 splice를 많이 사용하셨다.
filter보다는 splice가 더 효율이 좋은 거 같다. 다음 문제부턴 splice로도 한번 풀어봐야겠다.
