
0. Intro
지난 포스트에서 간단하게 짚고 넘어갔던 cross entropy에 대해 더욱 자세히 설명하고자 합니다.
entropy와 cross entropy는 정보 이론 (Information Theory)과 관련이 깊습니다. 따라서 이번 포스트에서는 entropy와 cross entropy 뿐만이 아닌 KL-divergence, mutual information에 대해서도 함께 정리하겠습니다.
공부 소스 : 혁펜하임의 "꽂히는" 딥러닝 (Youtube)
1. 엔트로피 (Entropy)
정보 (information)는 어떻게 표현할 수 있을까요?
나라마다 언어가 서로 다르듯이, 정보를 표현하는 방식도 천차만별입니다.
텍스트, 음성, 영상 등등..
하지만 언어 쪽에는 "영어"라는 만국공통어가 존재합니다. 이를 통해 정확하지는 않더라도 하나의 공통된 형태로 표현이 가능합니다.
정보 분야에서도 이러한 만국공통어를 정의하고자 노력한 인물이 있습니다.
 출처 : 위키백과
출처 : 위키백과
바로 "정보 이론의 아버지"라고 불리는 미국의 수학자 클로드 섀넌 (Claude Shannon)입니다.
섀넌은 모든 정보를 표현할 수 있는 공통된 단위로써 비트 (bits)를 고안했습니다. 즉, 0과 1로 모든 정보를 표현할 수 있다는 것이죠.
섀넌은 앞으로 살펴볼 엔트로피 (Entropy)에 대한 정의도 내렸는데, 이는 다음과 같습니다.
"정보를 표현하는 데 필요한 최소 평균 자원량"
여기서 "자원량"은 비트를 기준으로 하는 정보의 길이를 의미합니다. (111은 3 bits, 1010은 4 bits)
엔트로피 개념의 핵심은 자주 쓰는 정보의 크기를 작게 만드는 것입니다.
사랑하는 연인과 문자 메시지를 나누는 상황을 가정해 볼까요? (어라 왜 눈물이..😭)
보통 사랑이 넘치는 커플의 경우 문자에 ❤️가 많이 나타날 것이고, ㅗ와 같이 욕을 의미하는 문자는 거의 나타나지 않을 것입니다.
이때 자주 사용하는 ❤️라는 문자 정보에 3 bits를 할당하고, 거의 쓰지 않는 ㅗ 문자에는 1 bits를 할당한다면, 이것을 "효율적이다"라고 할 수 있을까요?
당연히 이 방식은 효율적이지 않습니다. 많이 쓰는 정보의 길이가 길기 때문에 총 사용하는 크기, 즉 자원량이 매우 커지기 때문이죠.
따라서 자주 쓰는 ❤️에 1 bits를 할당하여 최대한 자원을 아끼고, 효율적으로 정보를 관리해야 합니다.
이에 확률 개념을 적용하여 "정보의 빈도수에 따른 확률"을 기반으로 확률이 큰 정보의 길이는 짧게, 확률이 작은 정보의 길이는 길게 하는 것이 엔트로피가 정의하는 "최소 평균 자원량"의 의미라고 할 수 있습니다.
섀넌은 엔트로피를 정의하면서 자원량에 대한 lower bound (하계)를 제시하였습니다. 즉, 아무리 코딩을 효율적으로 한다고 해도 섀넌이 정의한 값보다 작게 코딩할 수는 없다는 뜻이죠.
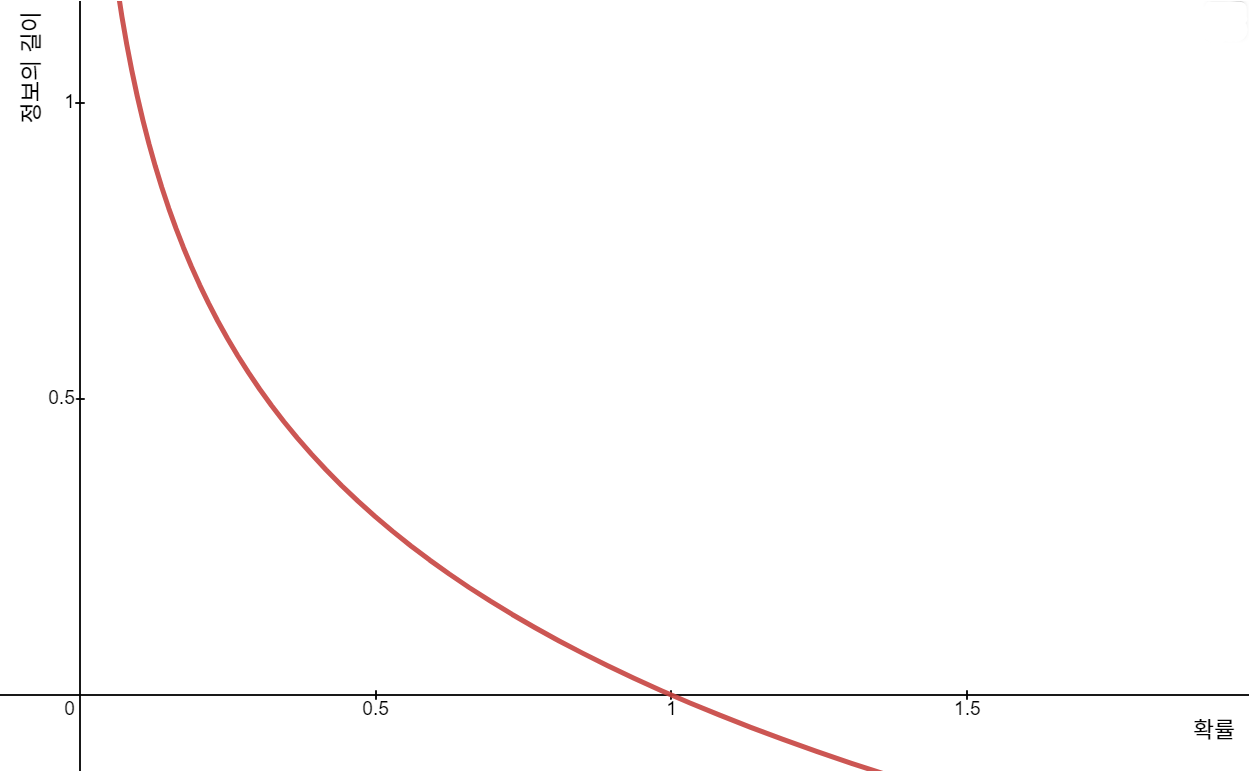
앞에서 말한 엔트로피의 개념을 그래프로 표현한 것입니다.
로그 함수의 뒤집어진 형태와 같으므로 의 형태를 가집니다.
다만 비트 (0 또는 1)로 표현해야 하고, 확률에 대한 함수이므로 의 형태가 될 것입니다.
이론과는 달리, 실제로 주어지는 정보는 "완전히 랜덤"합니다. 따라서 엔트로피는 기댓값 (Expected Value)의 형태로 정의해야 합니다.
간단히 말해 기댓값은 나올 수 있는 값 확률의 합인데, "나올 수 있는 값"은 축, 정보의 길이에 해당합니다.
최종적으로 섀넌이 정의한 엔트로피는 다음과 같습니다.
최소 평균 자원량 - 엔트로피
 출처 : ThatsMaths
출처 : ThatsMaths
엔트로피가 "최소" 평균 자원량을 의미하기 때문에, 이 값이 최대로 커지는 상황은 최악의 상황일 것입니다.
모든 정보를 골고루 사용하도록 프로그래밍된 AI가 아닌 이상 자주 쓰는 정보와 덜 자주 쓰는 정보가 있기 마련입니다.
그런데 이를 고려하지 않고 모든 정보에 대한 확률을 uniform하게 정의해버리면 자주 쓰지 않는 정보의 크기가 불필요하게 커지기 때문에 효율은 극도로 나빠집니다.
따라서 모든 확률이 uniform할 때 엔트로피 값은 최대가 되며, 이 상황이 최악의 상황이라고 할 수 있습니다.
여담으로, 확률이 contiguous할 때는 대신 자연로그 을 사용하여 엔트로피를 정의하며, 확률이 가우시안 분포일 때가 최악의 상황입니다.
2. 교차 엔트로피 (Cross Entropy)
엔트로피는 이론상 완벽한, 이상적인 값인 반면, cross entropy는 실제 적용에 관련된 부분이 많습니다.
정보가 실제로 따르는 확률분포인 대신 코딩 시 적용한 확률분포 를 포함한 것이 cross entropy입니다.
여기서 는 실제로 따르는 확률분포, 는 내가 적용한 확률분포를 의미합니다.
실제 값인 가 이상적인 값 에 가까워질수록 cross entropy 값은 작아지고, 더욱 효율적으로 정보를 관리한다는 것을 의미하게 됩니다.
3. KL-divergence
KL-divergence는 "내가 짠 코드의 비효율적인 정도"를 나타냅니다.
이때 기준이 되는 값은 이상적인 값인 "엔트로피"이고, 이를 cross entropy와 비교한 값이 KL-divergence의 값이 됩니다.
4. Mutual Information
이는 KL-divergence의 식을 변형한 형태와 비슷합니다.
KL-divergence 식은 "실제로는 확률분포 를 따르지만, 를 따른다고 오해해서 짰다."를 의미합니다.
이와 비슷하게 mutual informaion은 다음을 의미합니다.
"실제로는 와 가 서로 독립이 아닌데, 독립이라고 오해해서 짰다."
(와 가 독립일 경우 가 성립함)
즉, 두 확률분포가 독립일 때와 독립이 아닐 때의 차이가 mutual information이고, 이 값이 클수록 "독립이 아닌 정도"가 큰 것입니다.
두 확률분포가 독립이라면 이므로 mutual informaion의 값은 0이 될 것입니다.
또한,
"mutual information이 크다 == 확률분포 사이에 서로 겹치는 부분이 많다"
마무리
다음 포스트에서는 딥러닝 수식을 이해하는 데 필요한 수학적인 부분을 다룹니다. (스칼라를 벡터로 미분하는 방법 등)
