[딥러닝-Classification] 뇌종양 이미지 멀티 클래스 분류-02(cam,gradcam Heatmap, 설명가능 AI)
03번째 게시물
03번째 게시물입니다. 이번 게시물에서는 딥러닝 이미지 Classification 결과를 도출할 때에 어떠한 영역을 보고 y라는 class를 예측하였는지 Heatmap형식으로 표현하는 cam, gradcam 기능에 대해서 간단하게 알아보겠습니다.
02번째 게시물에서 실습한 뇌종양 이미지 classification결과를 가지고 gradcam을 도출하여 class를 결정지을 때 주요 판단영역을 도출해보겠습니다.
1. cam
논문 : Learning Deep Features for Discriminative Localization
저자 : Zhou, Bolei, et al. "Learning deep features for discriminative localization." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
위 논문의 내용을 간단하게 요약하면 아래와 같습니다.
1) CNN network는 별도의 위치 정보를 제공하지 않더라도 Object detector역할을 할 수 있습니다.
2) 하지만 Fully-connected layer를 거치면 c x h x w 형태의 Feature(pixel)들이 flatten되어 위치정보가 소실되어서 위와 같이 detector역할을 수행할 수 없게 됩니다.
3) 만약 Fully-connected layer들이 아닌 GAP(Global Average Pooling)로 층을 쌓게 되면 파라미터개수를 줄이게 되면서 위치정보를 전달할 수 있게 되고 퍼포먼스 또한 괜찮게 나옵니다.
4) GAP층을 쌓기 전 Featuremap과 GAP 이후 각 class에 대한 가중치w를 곱해주면 한개의 Heatmap이 도출되고 이것들을 Feature map 개수 k만큼 구하고 더하게 되면 최종 Heatmap(cam)이 도출 됩니다.
결국에는 이미지를 CNN으로 Classification할 때에 단순히 확률 값만 보고 class를 어떻게 도출했는지 보기보다는 Heatmap형식으로 class를 판단할 때 주로 보게되는 pixel영역을 표시하는 것이군요.
다만 CAM은 GAP를 사용할 때에만 사용이 가능하므로 국소적인 영역에서 Heatmap을 얻을 수 있겠네요.
2. gradcam
논문 : Grad-cam: Visual explanations from deep networks via gradient-based localization
저자 : Selvaraju, Ramprasaath R., et al. "Grad-cam: Visual explanations from deep networks via gradient-based localization." Proceedings of the IEEE international conference on computer vision. 2017.
위 논문의 내용을 간단하게 요약하면 아래와 같습니다.
gradcam에서는 개별 Feature map이 class를 결정지을 때 가지는 평균(특정 Feature map 에서 모든 pixel의 gardient 평균)gradient 값을 Feature map에 곱한 뒤 존재하는 Feature map을 모두 합하여 Heatmap을 형성합니다.
결국에는 Feature map과 gradient만 있으면 되니 CNN에서 CAM과 같이 GAP를 사용해야하는 구조적 한계를 벗어날 수 잇습니다.
3. 실습
02 번째에서 실습한 뇌종양데이터로 gradcam heat-map을 도출해보겠습니다.
전체코드
import os
import cv2
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn.functional as F
import pandas as pd
import albumentations as A
from torchvision import models
from PIL import Image
from torchinfo import summary
from torch.utils.data import Dataset, DataLoader
from albumentations.pytorch.transforms import ToTensorV2
from pytorch_grad_cam.gradcam import CAM
from pytorch_grad_cam.utils.image import show_cam_on_image
# dataset class
class dataset(Dataset):
def __init__(self, data,phase):
self.x = data[0] #numpy image
self.y = data[1] #one-hot-encoding label
self.phase = phase
def __len__(self):
return len(self.y)
def __getitem__(self, index):
single_x = self.x[index]
single_y = self.y.iloc[index]
single_y = torch.tensor(single_y)
self.augmentor = self.augmentation()
augmented = self.augmentor(image=single_x)["image"]
normalizated = self.normalization(augmented)
return normalizated, single_y
def augmentation(self):
pipeline = []
if self.phase == "train":
pipeline.append(A.HorizontalFlip(p=0.5))
pipeline.append(A.RandomBrightnessContrast(p=0.5))
pipeline.append(A.CenterCrop(height=300,width=300,p=1))
pipeline.append(ToTensorV2(transpose_mask=True, p=1))
else:
pipeline.append(A.CenterCrop(height=300,width=300,p=1))
pipeline.append(ToTensorV2(transpose_mask=True, p=1))
return A.Compose(pipeline, p=1)
def normalization(self, array):
normalizated_array = (array - array.min()) / (array.max() - array.min())
return normalizated_array
class network(nn.Module):
def __init__(self, class_num):
super().__init__()
self.class_num = class_num
self.init = torch.nn.Conv2d(in_channels=1, out_channels=3, kernel_size=(1, 1))
self.model = models.resnet18(pretrained=True)
self.gradlayer = self.model.layer4[-1]
self.num_ftrs = self.model.fc.in_features
self.model.fc = nn.Linear(
in_features=self.num_ftrs, out_features=self.class_num
)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
output = self.init(x)
output = self.model(output)
output = self.softmax(output)
return output
def split_feature_label(file_path):
label = file_path.split("\\")[1]
img = Image.open(file_path).convert("L")
img_array = np.array(img, dtype=np.uint8)
return img_array, label
def fileopen_splitdata_labeling(dir):
train_data = {"numpy": [], "label": [],"shape_h":[],"shape_w":[]}
val_data = {"numpy": [], "label": [],"shape_h":[],"shape_w":[]}
test_data = {"numpy": [], "label": [],"shape_h":[],"shape_w":[],"test_path":[]}
train_shape = np.zeros(2)
val_shape = np.zeros(2)
test_shape = np.zeros(2)
for (directory, _, filenames) in os.walk(dir):
if "Training" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
train_shape = train_shape + img_array.shape
train_data["numpy"].append(img_array)
train_data["label"].append(label)
train_data["shape_h"].append(img_array.shape[0])
train_data["shape_w"].append(img_array.shape[1])
elif "Validation" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
val_shape = val_shape + img_array.shape
val_data["numpy"].append(img_array)
val_data["label"].append(label)
val_data["shape_h"].append(img_array.shape[0])
val_data["shape_w"].append(img_array.shape[1])
elif "Testing" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
test_shape = test_shape + img_array.shape
test_data["numpy"].append(img_array)
test_data["label"].append(label)
test_data["shape_h"].append(img_array.shape[0])
test_data["shape_w"].append(img_array.shape[1])
test_data["test_path"].append(file_path)
train_avg_shape = train_shape / len(train_data["numpy"])
train_hmin_shape = min(train_data["shape_h"])
train_wmin_shape = min(train_data["shape_w"])
val_avg_shape = val_shape / len(val_data["numpy"])
val_hmin_shape = min(val_data["shape_h"])
val_wmin_shape = min(val_data["shape_w"])
test_avg_shape = test_shape / len(test_data["numpy"])
test_hmin_shape = min(test_data["shape_h"])
test_wmin_shape = min(test_data["shape_w"])
print(f"\n\n###데이터 셋 별 평균 이미지 크기 확인###\n!!!!WARNING!!!!")
print(f"1. train데이터 평균 이미지 크기 : {train_avg_shape}, min_h : {train_hmin_shape}, min_w : {train_wmin_shape}")
print(f"1. val데이터 평균 이미지 크기 : {val_avg_shape}, min_h : {val_hmin_shape}, min_w : {val_wmin_shape}")
print(f"1. train데이터 평균 이미지 크기 : {test_avg_shape}, min_h : {test_hmin_shape}, min_w : {test_wmin_shape}")
print(f"image shaped 300 x 300 안되면 제거, crop을 300 x 300 으로 실시예정")
train_df = pd.DataFrame(train_data)
val_df = pd.DataFrame(val_data)
test_df = pd.DataFrame(test_data)
train_df.drop(index=train_df[train_df["shape_h"]<300].index,inplace=True)
train_df.drop(train_df[train_df["shape_w"]<300].index,inplace=True)
val_df.drop(index=val_df[val_df["shape_h"]<300].index,inplace=True)
val_df.drop(index=val_df[val_df["shape_w"]<300].index,inplace=True)
test_df.drop(index=test_df[test_df["shape_h"]<300].index,inplace=True)
test_df.drop(index=test_df[test_df["shape_w"]<300].index,inplace=True)
train_df.reset_index(inplace=True)
val_df.reset_index(inplace=True)
test_df.reset_index(inplace=True)
train_df_numpy = train_df["numpy"]
val_df_numpy = val_df["numpy"]
test_df_numpy = test_df["numpy"]
train_label = pd.get_dummies(train_df["label"])
val_label = pd.get_dummies(val_df["label"])
test_label = pd.get_dummies(test_df["label"])
test_path = test_df["test_path"]
final_train_data = (train_df_numpy,train_label)
final_val_data = (val_df_numpy,val_label)
final_test_data = (test_df_numpy,test_label)
print("\n####크기 수정####")
return final_train_data, final_val_data, final_test_data, test_path
if __name__ == "__main__":
dir = "C:/Users/PC_1M/Desktop/코딩/kaggle_data/BrainTumor/Brain Tumor MRI Classfication/"
train_batch = 16
val_batch = 1
test_batch = 1
lr = 0.01
step_size = 20
gamma = 0.5
total_epoch = 30
save_path = "C:/Users/PC_1M/Desktop/코딩/model/brain_tumor_epoch100.pt"
train_data, val_data, test_data,test_path = fileopen_splitdata_labeling(dir=dir)
class_num = len(set(train_data[1]))
train_dataset = dataset(train_data,phase="train")
val_dataset = dataset(val_data,phase="val")
test_dataset = dataset(test_data,phase="test")
print("\n###데이터셋 정의완료###")
train_dataloader = DataLoader(train_dataset, batch_size=train_batch,shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=val_batch)
test_dataloader = DataLoader(test_dataset, batch_size=test_batch)
print("###데이터로더 정의완료###")
model = network(class_num=class_num)
print("###모델 정의 완료(resnet18)###\n", summary(model))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device=device)
print(f"\n### The device is --{device}-- that we use ###")
phase = input(str("Do you want to train ? (y or n) : "))
if phase == "y":
optimizer = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(
optimizer=optimizer, step_size=step_size, gamma=gamma
)
criterion = nn.CrossEntropyLoss()
total_loss = {"Train": [], "Val": []}
for epoch in range(total_epoch):
model.train()
epoch_train_loss = 0.0
for batch_index in (train_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels.float()
optimizer.zero_grad() # 초기화
if device == "cuda":
inputs.to(device=device)
outputs = model(inputs)
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
batch_train_loss = loss.item() # loss만 가져오기
print(batch_train_loss)
# print(batch_train_loss)
loss.backward() # 역전파 기록 저장
optimizer.step() # 업데이트
epoch_train_loss += batch_train_loss
avg_train_loss = epoch_train_loss / len(train_dataloader)
model.eval()
val_epoch_loss = 0.0
for batch_index in (val_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels.float()
with torch.no_grad():
outputs = model(inputs)
loss = criterion(outputs, labels)
val_batch_loss = loss.item()
val_epoch_loss += val_batch_loss
avg_val_loss = val_epoch_loss / len(val_dataloader)
total_loss["Train"].append(avg_train_loss)
total_loss["Val"].append(avg_val_loss)
print(
f"epoch : {epoch} The train loss is {avg_train_loss}, valid loss is {avg_val_loss}"
)
scheduler.step()
torch.save(model.state_dict(),save_path)
x = np.arange(1, total_epoch + 1)
plt.plot(x, total_loss["Train"], "r", label="train")
plt.plot(x, total_loss["Val"], "b", label="val")
plt.legend()
plt.title("Tumor Deeplearning")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
elif phase == "n":
test_results = []
grad_image = []
model = network(class_num=class_num)
model.load_state_dict(torch.load(save_path))
model.eval()
cam = CAM(model=model,target_layer=model.gradlayer,use_cuda=False)
for i,batch_index in enumerate(test_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels[0]
result1 = torch.where(labels == labels.max())[0]
with torch.no_grad():
outputs = model(inputs)[0]
result2= torch.where(outputs == outputs.max())[0]
test_result = True if result1 == result2 else False
test_results.append(test_result)
grayscale_img = cam(input_tensor=inputs)
rgb_img = np.array(inputs).squeeze()
rgb_img = cv2.cvtColor(rgb_img,cv2.COLOR_GRAY2RGB)
visualization = show_cam_on_image(img=rgb_img,mask=grayscale_img)
cam_PIL = Image.fromarray(visualization)
save_grad_path = test_path[i].split(".jpg")[0]+".png"
cam_PIL.save(save_grad_path,format="png")
ok = test_results.count(True)
ng = test_results.count(False)
accuracy = ok / (ok+ng)
print(f"Test 결과 OK 개수:{ok}, NG개수:{ng}, 정확도 : {accuracy}")
gradcam 추가코드
from pytorch_grad_cam.gradcam import CAM
from pytorch_grad_cam.utils.image import show_cam_on_image
cam = CAM(model=model,target_layer=model.gradlayer,use_cuda=False)
grayscale_img = cam(input_tensor=inputs)
rgb_img = np.array(inputs).squeeze()
rgb_img = cv2.cvtColor(rgb_img,cv2.COLOR_GRAY2RGB)
visualization = show_cam_on_image(img=rgb_img,mask=grayscale_img)
cam_PIL = Image.fromarray(visualization)
save_grad_path = test_path[i].split(".jpg")[0]+".png"
cam_PIL.save(save_grad_path,format="png")
-
두가지 모듈을 import 합니다.
-
cam 객체를 생성합니다. input으로는 생성한 model과 target_layer를 입력합니다. 여기서 network를 객체를 생성할 때에 restnet18의 경우
self.gradlayer = self.model.layer4[-1] 으로 gradcam을 그리는데 필요한 featuremap을 인스턴스 속성에 저장합니다.
(gradcam 모듈 기터브 주소입니다. 여기서 전이 모델 별로 targetlayer를 다르게 network 인스턴스에 저장해야합니다. https://github.com/jacobgil/pytorch-grad-cam)
-
grayscale_img 값으로 cam인스턴스에 input_tensor(배치로 넘어오는 초기 이미지)값으로 입력한 결과를 반환합니다. 이 결과 값이 heatmap입니다!!
정말간단하게 gradcam을 도출했네요! -
show_cam_on_image 클래스로 인스턴스를 생성하여 배경화면이 되는 rgb_img와 mask(grayscale_img)를 합성하여 save_grad_path에 합성된 이미지를 저장합니다.
이제 결과를 확인해볼 차례입니다.
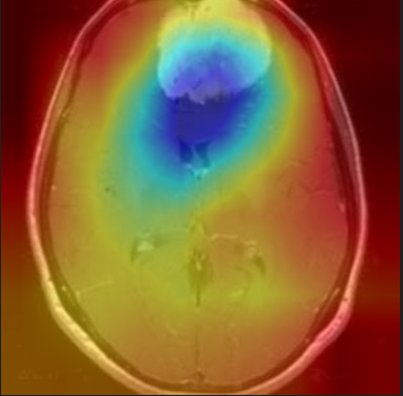
1) meningioma_tumor
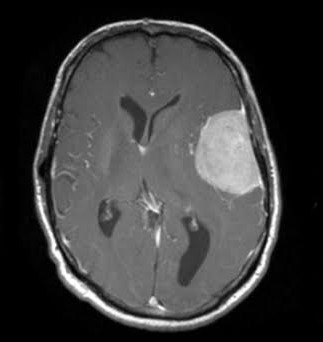 ,
, 
오른쪽 종양부분을 집중적으로 보고 meningioma_tumor라고 판단을 내렸네요
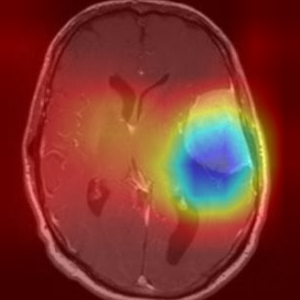
2) pituitary_tumor
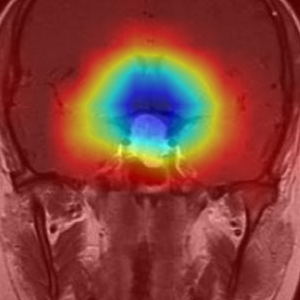
가운데 하얀부분을 보고 pituitary_tumor라고 판단을 내렸네요
3) glioma_tumor
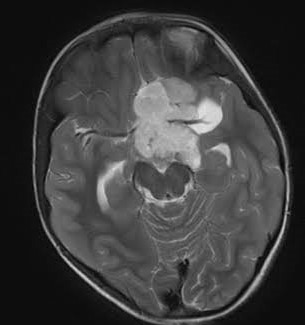
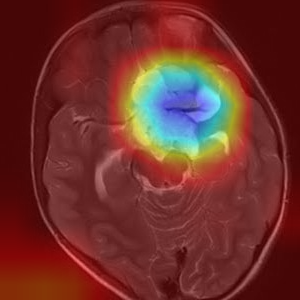
큰 면적의 하얀부분을 보고 glima_tumor라고 판단을 내렸습니다.
정상적으로 gradcam이 잘 도출되네요!!
간단한 gradcam 모듈을 통해서 class를 판단할 때에 단순히 확률 값만 보는 것이 아니라 주로 어느 영역을 보고 class를 판단했는지 알 수 잇습니다.
+추가
1) 이미지별로 크기가 너무 다르다보니 300x300 크기가 안되는 이미지들은 이상치로 간주하여 train,valid,test에 제외 하는 코드를 추가했습니다.
3) centor crop 크기 역시 300x300으로 지정했습니다
4) pipeline에 train일 경우만 aug가 적용되도록 지정했습니다.
이미지 classification 하실 때 참고하시면 좋을 것 같습니다.
