😢 스터디노트 (Machine Learning 9)
Boosting Algorithm
-
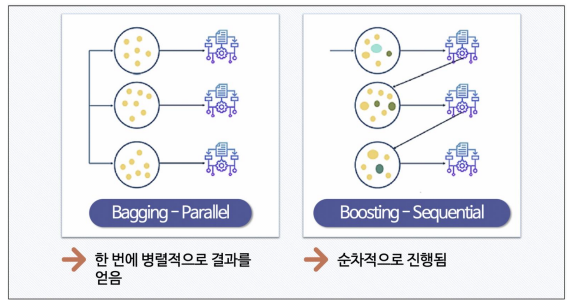
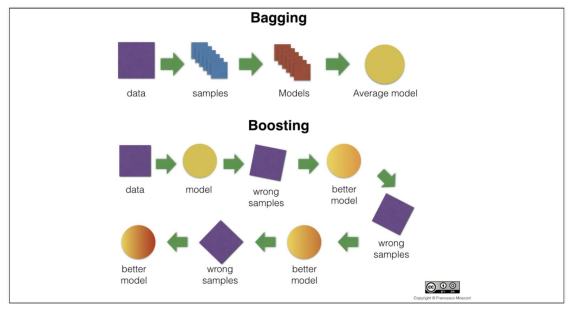
앙상블 기법 : Voting, Bagging, Boosting, 스태깅 등으로 나눈다. 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식. 보팅과 배깅의 차이점은 보팅은 각각 다른 분류기, 배깅은 같은 분류기를 사용. 대표적인 배깅 방식이 랜덤 포레스트이다
-
Boosting : 여러 개의 (약한)분류기가 순차적으로 학습을 하면서 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식. 예측 성능이 뛰어나서 앙상블 학습을 주도하고 있다 → 그래디언트부스트, XGBoost, LightGBM 등
-
배깅과 부스팅의 차이
- Adaboost :
Adaboost - STEP1) 순차적으로 가중치를 부여해서 최종 결과를 얻음. AdaBoost는 DecisionTree 기반의 알고리즘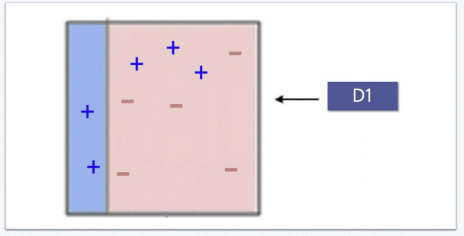
Adaboost - STEP2) Step1에서 틀린 +에 가중치를 인가하고 다시 경계를 결정
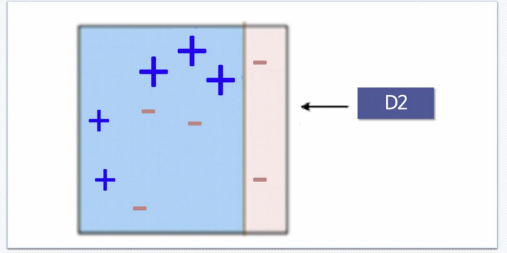
Adaboost - STEP3) 다시 놓친 -에 가중치를 인가하고 다시 경계를 결정
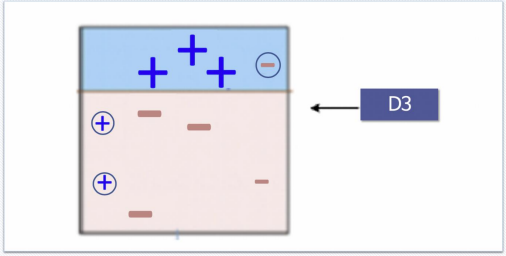
Adaboost - STEP4) 앞서 결정한 경계들을 합침
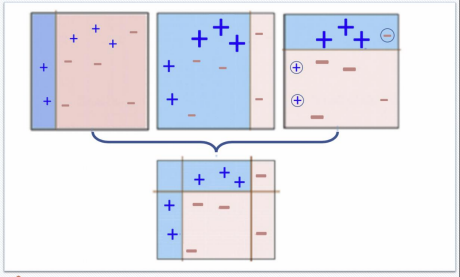
- 부스팅 기법
- GBM Gradient Boosting Machine : AdaBoost 기법과 비슷하지만, 가중치를 업데이트할 때 경사하강법(Gradient Descent)을 사용
- XGBoost : GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐
- LightGBM : XGBoost보다 빠른 속도를 가짐
wine 데이터
# wine 데이터
# 데이터 읽기, 컬럼 생성
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine.head()wine['taste'] = [1 if grade > 5 else 0 for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']# 직접 StandardScaler 적용
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_sc = sc.fit_transform(X)
X_sc# Scaler 적용 후에 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_sc, y, test_size=0.2, random_state=13)# 모든 컬럼의 히스토그램 조사
# 잘 분포되어 있는 컬럼이 좋을 때가 많다
import matplotlib.pyplot as plt
%matplotlib inline
wine.hist(bins=10, figsize=(15, 10))
plt.show()# quality별 다른 특성이 어떤지 확인
column_names = ['fixed acidity', 'volatile acidity', 'citric acid',
'citric acid', 'residual sugar','chlorides', 'free sulfur dioxide',
'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
print(df_pivot_table)# quality에 대한 나머지 특징들의 상관관계
# 상관계수는 절대값으로 봐야 함
corr_matrix = wine.corr()
print(corr_matrix['quality'].sort_values(ascending=False))# taste 컬럼의 분포
import seaborn as sns
sns.countplot(x= wine['taste'], data=wine)
plt.show()# 다양한 모델을 한번에 테스트 ★★★
from sklearn.ensemble import (AdaBoostClassifier, GradientBoostingClassifier,
RandomForestClassifier)
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append(('RandomForestClassifier', RandomForestClassifier())) # 튜플형으로 넣기
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))
models# 결과 저장 작업 ★★★
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle = True) # shuffle = True : 나누기 전에 데이터 섞기(?)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())results# cross-validation 결과를 일목요연하게 확인하기
# 지금은 randomForest가 유리해보인다
fig = plt.figure(figsize=(14, 8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()# 테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))kNN
- kNN : 새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제. k는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치
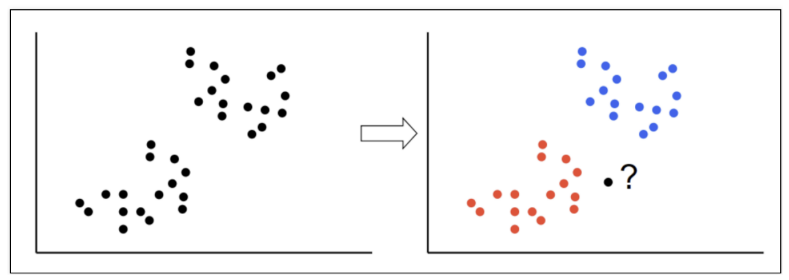
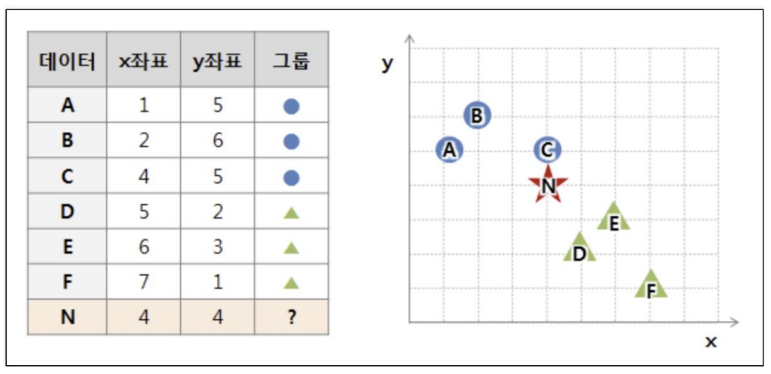
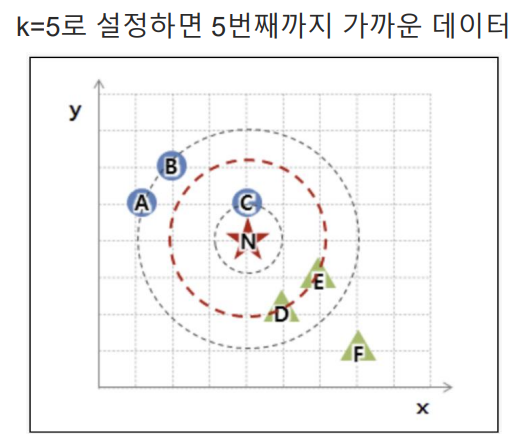
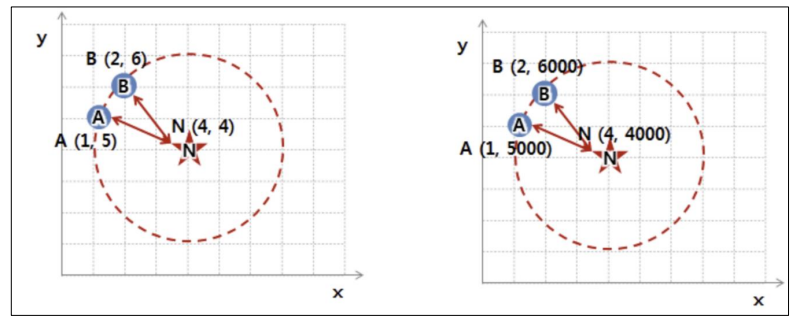
- 유클리드 기하 : 거리 계산
- 단위에 따라 바뀔 수도 있다 → 표준화 필요
- 장단점
- 실시간 예측을 위한 학습이 필요하지 않다
- 속도가 빨라진다
- 고차원 데이터(데이터가 많거나 컬럼의 수가 많은 경우)에는 적합하지 않다
kNN 실습 - iris 데이터
# iris 데이터
from sklearn.datasets import load_iris
iris = load_iris()from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size=0.2, random_state=13,
stratify=iris.target)# kNN 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)# accuracy
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
print(accuracy_score(y_test, pred))# 간단한 성과
# confusion_matrix : https://wikidocs.net/194464
# classification_report : https://wikidocs.net/193994
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))GBM - Gradient Boosting Machine
- GBM : 부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습 - 예측하면서 잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해가는 방식. GBM은 가중치를 업데이트할 때 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이이다
# HAR 데이터 읽기
import pandas as pd
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None,
names=['column_index', 'column_name'])
# sep='\s+' : 길이가 정해지지 않은 공백이 구분자인 경우에는 \s+ 정규식(regular expression) 문자열을 사용
# 참고 : https://datascienceschool.net/01%20python/04.02%20%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EC%9E%85%EC%B6%9C%EB%A0%A5.html
# names= : column이름 설정
feature_name = feature_name_df.iloc[:, 1].values.tolist()
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_test_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_name
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_test_url, sep='\s+', header=None, names = ['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])
# 필요 모듈 import
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')# acc가 1 %, 계산시간 388초
# 일반적으로 GBM이 성능 자체는 랜덤 포레스트보다 좋다고 알려져 있다
# sckit-learn의 GBM은 속도가 아주 느린 것으로 알려져 있다.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
print('ACC : ', accuracy_score(y_test, gb_pred))
print('Fit item : ', time.time() - start_time)# GridSearch
# 시간이 오래 걸림!! ★★★★★
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100, 500],
'learning_rate' : [0.05, 0.1]
}
start_time = time.time()
grid = GridSearchCV(gb_clf, param_grid=params, cv = 2, verbose=1, n_jobs=-1)
# cv : 교차검증을 위한 fold 횟수
# verbose : 돌아간 횟수, 수행 결과 메시지를 출력, verbose=0(default)면 메시지 출력 안함, verbose=1이면 간단한 메시지 출력, verbose=2이면 하이퍼 파라미터별 메시지 출력
# 출처 : https://www.inflearn.com/questions/62112/gridsearchcv%EC%97%90%EC%84%9C-verbose
grid.fit(X_train, y_train)
print('Fit time : ', time.time() - start_time)# best 파라미터
grid.best_score_grid.best_params_# test 데이터에서의 성능
accuracy_score(y_test, grid.best_estimator_.predict(X_test))XGBoost
-
XGBoost : 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나. GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결. 특히 병렬학습이 가능하도록 설계됨. XGBoost는 반복 수행 시마다 내부적으로 학습데이터와 검증 데이터를 교차검증을 수행. 교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능을 가지고 있음
-
주요 파라미터
- nthread : CPU의 실행 스레드 개수를 조정. 디폴트는 CPU의 전체 스레드를 사용하는 것
- eta : GBM 학습률
- num_bosst_rounds : n_estimators와 같은 파라미터
- max_depth
# install
# pip install xgboost
# 에러가 날 경우, conda install py-xgboost
# xgboost는 설치해야 함
!pip install xgboost# 성능 확인
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
# 설정한 이유 : https://stackoverflow.com/questions/71996617/invalid-classes-inferred-from-unique-values-of-y-expected-0-1-2-3-4-5-got
start_time = time.time()
xgb = XGBClassifier(n_estimators = 400, learning_rate = 0.1, max_depth = 3)
xgb.fit(X_train.values, y_train)
print('Fit time : ', time.time()- start_time)accuracy_score(y_test, xgb.predict(X_test.values))# 조기 종료 조건과 검증 데이터 지정 가능
from xgboost import XGBClassifier
evals = [(X_test.values, y_test)]
start_time = time.time()
xgb = XGBClassifier(n_estimators = 400, learning_rate = 0.1, max_depth = 3)
xgb.fit(X_train.values, y_train, early_stopping_rounds=10, eval_set=evals)
print('Fit time : ', time.time() - start_time)accuracy_score(y_test, xgb.predict(X_test.values))LightGBM
- LightGBM : XGBoost와 함께 부스팅 계열에서 가장 각광받는 알고리즘. LGBM의 큰 장점은 속도. 단, 적은 수의 데이터에는 어울리지 않음(일반적으로 10000건 이상의 데이터가 필요하다고 한다). GPU 버전도 존재
# install for mac User
# brew install lightgbm
# pip install light gbm!pip install lightgbmimport numpy as np
from sklearn.preprocessing import LabelEncoder
# 라벨 인코더 생성
encoder = LabelEncoder()
# X_train데이터를 이용 피팅하고 라벨숫자로 변환한다
encoder.fit(X_train)
X_train_encoded = encoder.transform(X_train)
# X_test데이터에만 존재하는 새로 출현한 데이터를 신규 클래스로 추가한다 (중요!!!)
for label in np.unique(X_test):
if label not in encoder.classes_: # unseen label 데이터인 경우( )
encoder.classes_ = np.append(encoder.classes_, label) # 미처리 시 ValueError발생
X_test_encoded = encoder.transform(X_test)from lightgbm import LGBMClassifier
start_time = time.time()
lgbm = LGBMClassifier(n_estimators=400)
lgbm.fit(X_train.values, y_train, early_stopping_rounds=100, eval_set=evals)
print('Fit time : ', time.time() - start_time)
어렵..실행이 안됨;; 추후 다시 확인 필요 ㅠㅠ
💻 출처 : 제로베이스 데이터 취업 스쿨
