Recommendatation
- 추천시스템
- 콘텐츠 기반 필터링 추천 시스템 : 사용자가 특정한 아이템을 선호하는 경우, 그 아이템과 비슷한 아이템을 추천하는 방식
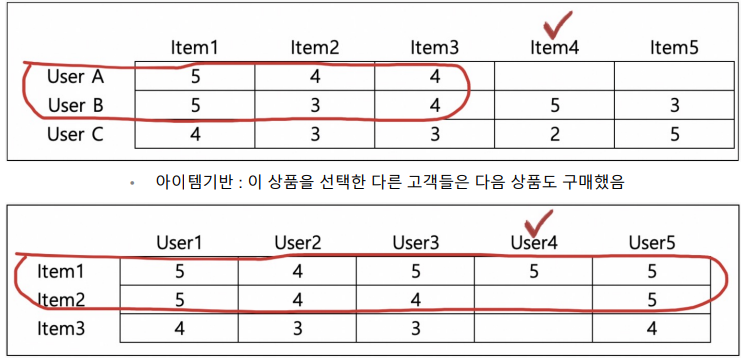
- 최근접 이웃 협업 필터링 : 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가. 사용자 기반 → 당신과 비슷한 고객들이 다음 상품도 구매했음
-
일반적으로는 사용자 기반보다는 아이템 기반 협업 필터링이 정확도가 더 높다
- 비슷한 영화를 좋아한다고 취향이 비슷하다고 판단하기 어렵거나
- 매우 유명한 영화는 취향과 관계없이 관람하는 경우가 많고
- 사용자들이 평점을 매기지 않는 경우가 많기 때문 -
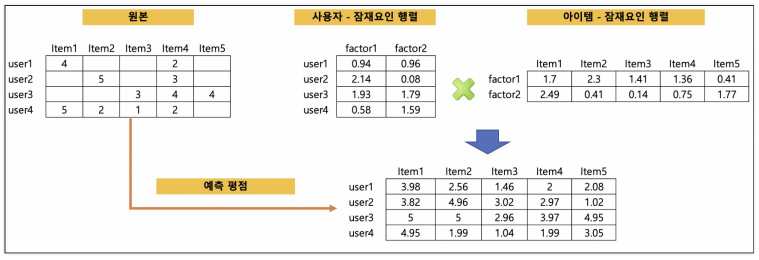
잠재 요인 협업 필터링 : 사용자 - 아이템 평점 행렬 데이터를 이용해서 '잠재요인'을 도출하는 것. 주요인과 아이템에 대한 잠재요인에 대해 행렬분해를 하고 다시 행렬곱을 통해 아직 평점을 부여하지 않은 아이템에 대한 예측 평점을 생성하는 것
콘텐츠 기반 필터링 실습 - TMDB5000 영화 데이터 세트
-
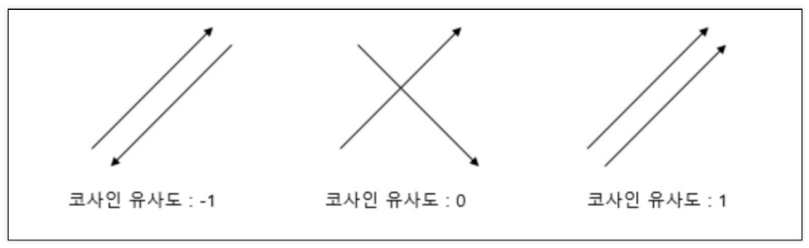
코사인 유사도
-
코사인 유사도 계산식

# 데이터 읽기
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
movies = pd.read_csv('./tmdb5000movies/tmdb_5000_movies.csv')
print(movies.shape)
movies.head()# 데이터 선택
movies_df = movies[['id', 'title', 'genres', 'vote_average',
'vote_count', 'popularity', 'keywords', 'overview']]
movies_df.head()# 데이터 주의사항
# genres와 keywords는 컬럼안에 dict형으로 저장됨
movies_df[['genres']][:1].valuestype(movies_df['genres'][0])movies_df['genres'][0]# 문자열로 된 데이터 변환
from ast import literal_eval
code = "(1, 2, {'foo':'bar'})"
codetype(code)literal_eval(code)type(literal_eval(code))# genres와 keywords의 내용을 list와 dict으로 복구
from ast import literal_eval
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
movies_df.head()# dict의 value 값을 특성으로 사용하도록 변경
movies_df['genres'] = movies_df['genres'].apply(lambda x : [y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x : [y['name'] for y in x])
movies_df[['genres', 'keywords']][:2]# genres의 각 단어들을 하나의 문장(띄어쓰기로 구분된)으로 변환
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x : (' '.join(x)))
movies_df.head()# 문자열로 변환된 genres를 CountVectorize 수행
# countvectorize : https://wikidocs.net/33661
# ngram_range : 단어 묶음 설정
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
print(genre_mat.shape)# 문장의 유사도 측정을 하는 방법 중 하나인 코사인 유사도 측정을 수행
# confusion_matrix와 비슷하게 해석하면 된다.
from sklearn.metrics.pairwise import cosine_similarity
genre_sim =cosine_similarity(genre_mat, genre_mat) # 두 메트릭스끼리 similarity를 구함
print(genre_sim.shape)
print(genre_sim[:2])# genre_sim 객체에서 높은 값 순으로 정렬
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
# [:, ::-1] : argsort()가 array 정렬 기능이고, ascending 정렬 기능이 없어 [:, ::-1]하면 순서가 뒤집힌다(?..)
print(genre_sim_sorted_ind[:1])# 추천 영화를 DataFrame으로 반환하는 함수
def find_sim_movie(df, sorted_ind, title_name, top_n = 10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
silmilar_indexes = sorted_ind[title_index, :(top_n)]
print(silmilar_indexes)
silmilar_indexes = silmilar_indexes.reshape(-1)
return df.iloc[silmilar_indexes]
# 영화 대부와 유사한 영화는?
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title', 'vote_average']]# 다시 데이터 탐색
# 평점과 평점을 매긴 횟수를 보면 문제 데이터가 보인다.
movies_df[['title', 'vote_average',
'vote_count']].sort_values('vote_average', ascending=False)[:10]- 영화 선정을 위한 가중치를 선정

# 영화 선정을 위한 가중치 선정
# 영화 전체 평균평점과 최소 투표 횟수를 60%지점으로 지정
C = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
print('C: ', round(C, 3), 'm: ', round(m, 3))# 가중치가 부여된 평점을 계산하기 위한 함수
def weighted_vote_average(recode):
v = recode['vote_count']
R = recode['vote_average']
return ((v/(v+m)) * R) + ((m/(m+v) * C))# 다시 계산
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df.head()# 전체 데이터에서 가중치가 부여된 평점 순으로 정렬한 결과
movies_df[['title', 'vote_average',
'weighted_vote', 'vote_count']].sort_values('weighted_vote', ascending=False)[:10]# vote_average와 weighted_vote를 비교해보면 가중치가 적용되어 값이 바뀌어 있음
movies_df.tail()movies_df[movies_df['vote_count'] < 10]# 전체 데이터에서 가중치가 부여된 평점 순으로 정렬
movies_df[['title', 'vote_average',
'weighted_vote', 'vote_count']].sort_values('weighted_vote', ascending=False)[:10]# 유사 영화를 찾는 함수 변경
def find_sim_movie(df, sorted_ind, title_name, top_n = 10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
silmilar_indexes = sorted_ind[title_index, :(top_n*2)]
silmilar_indexes = silmilar_indexes.reshape(-1)
silmilar_indexes = silmilar_indexes[silmilar_indexes != title_index]
return df.iloc[silmilar_indexes].sort_values('weighted_vote', ascending = False)[:top_n]# 대부와 유사한 영화 찾기
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title', 'vote_average', 'weighted_vote']]아이템 기반 최근접 이웃 협업 필터링
-
영화의 평점을 매긴 사용자와 영화 평점 행렬 등의 데이터
-
이중에서 1MB짜리 small 데이터 이용
# 데이터 읽기
import pandas as pd
import numpy as np
movies = pd.read_csv('./ml-latest-small/movies.csv')
ratings = pd.read_csv('./ml-latest-small/ratings.csv')
print(movies.shape)
print(ratings.shape)# movie에는 영화제목, 장르
movies.head()# rating에는 영화 평점이 사용자별로 영화별로 존재
ratings.head()- raw 데이터를 정리해야 한다.
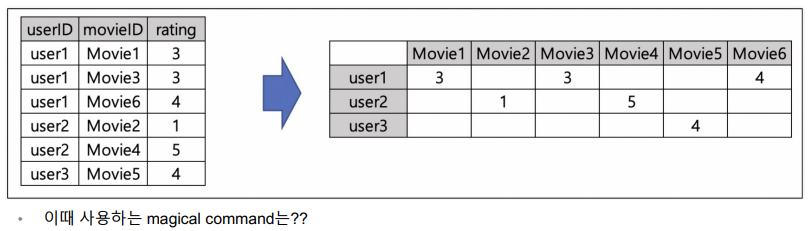
# rating raw 데이터 정리 필요
# pivot_table
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
ratings_matrix.head()# ratings와 movie를 movieID 기준으로 결합
ratings_movies = pd.merge(ratings, movies, on='movieId')
ratings_movies.head()# 다시 pivot_table 이용하여 정리
ratings_matrix = ratings_movies.pivot_table('rating', index='userId', columns='title')
ratings_matrix.head()# nan을 0으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix.head()# 유사도 측정을 위해 행렬의 transpose
ratings_matrix_T = ratings_matrix.transpose()
ratings_matrix_T.head()# 유사도 측정 결과
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
item_sim_df = pd.DataFrame(data=item_sim,
index=ratings_matrix.columns, columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df.head()# 대부와 유사한 영화는?
item_sim_df['Godfather, The (1972)'].sort_values(ascending=False)[:6]# 인셉션과 유사한 영화?
item_sim_df['Inception (2010)'].sort_values(ascending=False)[1:6]Good Books recommendations
# 데이터 경로 확인
import numpy as np
import pandas as pd
import os
print(os.listdir('./good book recommendation/'))# books.csv
# ratings 1, 2, 3, 4, 5의 의미 → 별점별 사람들 좋아요 수
books = pd.read_csv('./good book recommendation/books.csv', encoding='ISO-8859-1')
books.head()# ratings.csv
# rating user_id, user_id가 준 rate
ratings = pd.read_csv('./good book recommendation/ratings.csv', encoding='ISO-8859-1')
ratings.head()# book_tags.csv
# book_id와 tag_id
book_tags = pd.read_csv('./good book recommendation/book_tags.csv', encoding='ISO-8859-1')
book_tags.head()# tags.csv
# tag_id와 tag_name
tags = pd.read_csv('./good book recommendation/tags.csv', encoding='ISO-8859-1')
tags.head()# book_tags와 tags를 merge
tags_join_DF = pd.merge(book_tags, tags, left_on='tag_id', right_on='tag_id', how='inner')
tags_join_DF.head()# to_read.csv
# user_id가 읽은 book_id
to_read = pd.read_csv('./good book recommendation/to_read.csv')
to_read.head()# books의 aurthors
books['authors'][:5]# aurthors로 Tfidf 수행
# Tfidf : 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치이다.
# https://wikidocs.net/31698
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=0, stop_words='english')
tfidf_matrix = tf.fit_transform(books['authors'])
tfidf_matrix# 유사도 측정
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim# The Hobbit의 index는 6
titles = books['title']
indices =pd.Series(books.index, index=books['title'])
indices['The Hobbit']# 유사도 값 호출
cosine_sim[indices['The Hobbit']]# 유사도 결과를 인덱스를 가진 list 형으로
cosine_sim[indices['The Hobbit']].shapelist(enumerate(cosine_sim[indices['The Hobbit']]))# 가장 유사한 책의 인덱스 찾기
sim_scores = list(enumerate(cosine_sim[indices['The Hobbit']]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores[:3]# 작가로 본 유사 책 검색
sim_scores = sim_scores[1:11]
book_indices = [i[0] for i in sim_scores]
titles.iloc[book_indices]# book에 tag 포함
books_with_tags = pd.merge(books, tags_join_DF,
left_on='book_id', right_on='goodreads_book_id', how='inner')
books_with_tags.head()# tag로 Tfidf
tf1 = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=0, stop_words='english')
tfidf_matrix1 = tf1.fit_transform(books_with_tags['tag_name'].head(10000))
cosine_sim1 = linear_kernel(tfidf_matrix1, tfidf_matrix1)
cosine_sim1# 추천 책을 반환하는 함수
titles1 = books['title']
indices1 = pd.Series(books.index, index=books['title'])
def tags_recommendations(title):
idx = indices1[title]
sim_scores = list(enumerate(cosine_sim1[idx]))
sim_scores = sorted(sim_scores, key=lambda x:x[1], reverse=True)
sim_scores = sim_scores[1:11]
book_indices = [i[0] for i in sim_scores]
return titles.iloc[book_indices]
# 태그로 찾아본 The Hobbit과 유사한 책
tags_recommendations('The Hobbit').head(20)# 임시로 book id마다 tag를 붙이기
temp_df = books_with_tags.groupby('book_id')['tag_name'].apply(' '.join).reset_index()
temp_df.head()# books에 합치기
books = pd.merge(books, temp_df, left_on='book_id', right_on='book_id', how='inner')
books.head()pd.Series(books[['authors', 'tag_name']].fillna('').values.tolist())# 저자이름과 태그 합치기
books['corpus'] = (pd.Series(books[['authors', 'tag_name']].fillna('').values.tolist()).str.join(' '))
books['corpus'][:3]
# Tfidf 수행
tf_corpus = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=0, stop_words='english')
tfidf_matrix_corpus = tf_corpus.fit_transform(books['corpus'])
cosine_sim_corpus = linear_kernel(tfidf_matrix_corpus, tfidf_matrix_corpus)
titles = books['title']
indices = pd.Series(books.index, index=books['title'])# 추천함수 만들기
def corpus_recommendations(title):
idx = indices1[title]
sim_scores = list(enumerate(cosine_sim_corpus[idx]))
sim_scores = sorted(sim_scores, key= lambda x:x[1], reverse=True)
sim_scores = sim_scores[1:11]
book_indices = [i[0] for i in sim_scores]
return titles.iloc[book_indices]
# Hobbit과 비슷한 책
corpus_recommendations('The Hobbit')# Twilight과 비슷한 책
corpus_recommendations('Twilight (Twilight, #1)')# 로미오와 줄리엣과 유사한 책
corpus_recommendations('Romeo and Juliet')💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅