NLP(Natural language processing)
자연어 처리 - 형태소 분석
- 형태소 : 언어의 최소 의미 단위
from konlpy.tag import Kkma
kkma = Kkma()# sentences : 마침표가 없어도 문장 구분 가능
kkma.sentences('한국어 분석을 시작합니다 재미있어요~~')# nouns : 명사 분석
kkma.nouns('한국어 분석을 시작합니다 재미있어요~~')# pos : 형태소 분석
kkma.pos('한국어 분석을 시작합니다 재미있어요~~')from konlpy.tag import Hannanum
hannanum = Hannanum()hannanum.nouns('한국어 분석을 시작합니다 재미있어요~~')hannanum.morphs('한국어 분석을 시작합니다 재미있어요~~')hannanum.pos('한국어 분석을 시작합니다 재미있어요~~')from konlpy.tag import Okt
t = Okt()t.nouns('한국어 분석을 시작합니다 재미있어요~~')t.morphs('한국어 분석을 시작합니다 재미있어요~~')t.pos('한국어 분석을 시작합니다 재미있어요~~')워드클라우드
워드클라우드 - 이상한 나라의 앨리스
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Imagetext = open('./06_alice.txt').read()
alice_mask = np.array(Image.open('./06_alice_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add('said')alice_maskstopwordsimport matplotlib.pyplot as plt
import platform
path = 'C:/Windows/Fonts/malgun.ttf'
from matplotlib import font_manager, rc
if platform.system() == 'Darwin':
rc('font', family = 'AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family = font_name)
else:
print('Unknown system... sorrry')
get_ipython().run_line_magic('matplotlib', 'inline')# 앨리스 그림
plt.figure(figsize=(8, 8))
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
# interpolation='bilinear' : 이미지 블럭과 블럭 사이에 어떻게 이을 것인지 설정(?)
plt.axis('off')
plt.show()# WordCloud 모듈은 자체적으로 단어츨 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있다
wc = WordCloud(background_color='white', max_words=2000,
mask=alice_mask, stopwords=stopwords)
wc = wc.generate(text)
wc.words_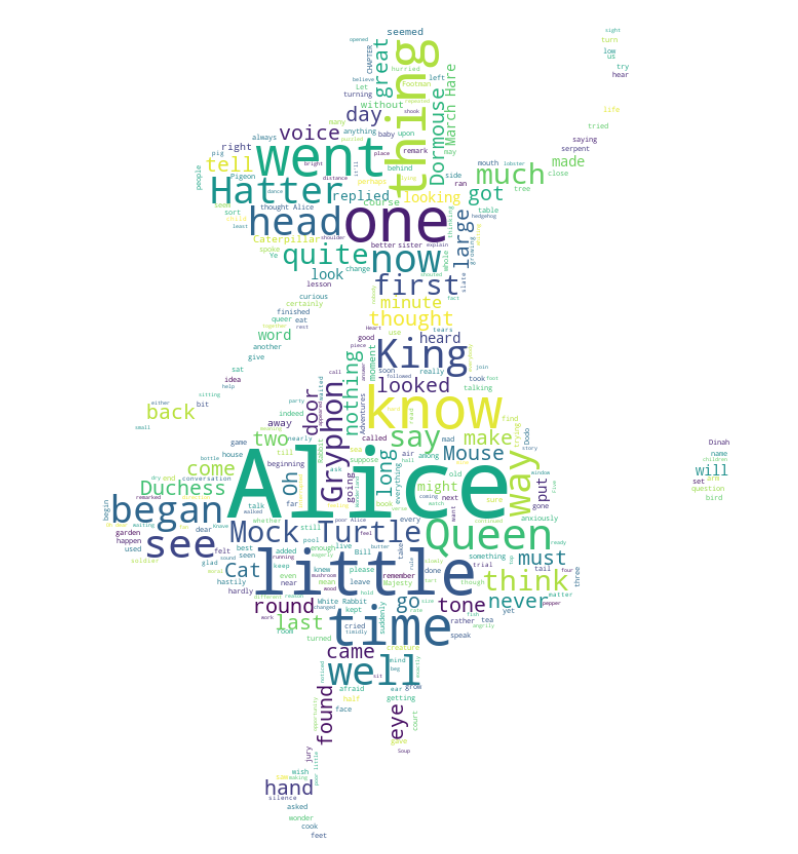
워드클라우드 - 스타워즈
# Star Wars
text = open('./06_a_new_hope.txt').read()
text = text.replace('HAN', 'Han')
text = text.replace("LUKE'S", 'Luke')
mask = np.array(Image.open('./06_stormtrooper_mask.png'))# stopwords : 문장에서는 자주 등장하지만 실제 의미 분석을 하는데는 기여 하지 못하는 단어들..
# https://wikidocs.net/22530
stopwords = set(STOPWORDS)
stopwords.add('int')
stopwords.add('ext')# Word Cloud 설정 지정
wc = WordCloud(
max_words=1000, mask=mask, stopwords=stopwords, margin=10,
random_state=1).generate(text)
default_colors = wc.to_array()# 그레이톤으로 그리기 위한 색상함수 정의
import random
def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)
# 그리기
plt.figure(figsize=(12, 12))
plt.imshow(
wc.recolor(color_func=grey_color_func, random_state=3), interpolation='bilinear')
plt.axis('off')
plt.show()
육아 휴직 관련 법안
import nltk# KoNLPy는 대한민국 법령을 가지고 있다
from konlpy.corpus import kobill
files_ko = kobill.fileids()
doc_ko = kobill.open('1809890.txt').read()doc_ko# Okt 엔진으로 명사 분석
from konlpy.tag import Okt
t = Okt()
tokens_ko = t.nouns(doc_ko)
tokens_ko# nltk를 사용하여 토큰(빈도수 포함) 분석
ko = nltk.Text(tokens_ko, name='대한민국 국회 의안 제 1809890호')print(len(ko.tokens)) # returns number of tokens (document length)
print(len(set(ko.tokens))) # returns number of unique tokens
ko.vocab() # returns frequency distributionplt.figure(figsize=(12, 6))
ko.plot(50)
plt.show()# 한글 stopword는 상황에 따라 설정해야 하여, 수기로 설정
stop_words = ['.', '(', ')', ',', "'", '%', '-', 'X', ').', 'x', '의', '자', '에', '안',
'번', '호', '을', '이', '다', '만', '로', '가', '를']ko = [each_word for each_word in ko if each_word not in stop_words]
koko = nltk.Text(ko, name='대한민국 국회 의안 제 1809890호')
plt.figure(figsize=(12, 6))
ko.plot(50) # plot sorted frequency of top 50 tokens
plt.show()# 특정 단어의 빈도수 조사
ko.count('초등학교')plt.figure(figsize=(12, 6))
ko.dispersion_plot(['육아휴직', '초등학교', '공무원'])ko.concordance('초등학교')# 연어 : 연어(連語, collocation)란 "함께 위치하는 단어들"(co + location)이란 뜻으로, 어휘의 조합 또는 짝을 이루는 말
# http://ko.talkenglish.com/how-to-use/collocations.aspx
ko.collocations()data = ko.vocab().most_common(150)
# for win : font_path - 'c:/Windows/Fonts/malgun.ttf'
wordcloud = WordCloud(
font_path='C:/Windows/Fonts/malgun.ttf',
relative_scaling = 0.2, # relative_scaling : wordcloud별 간격(?)
background_color='white').generate_from_frequencies(dict(data))
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
나이브베이즈 분류
- 나이브베이즈 분류 : 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기의 일종
Naive Bayes Classifier를 이용한 감성분석 - 영어
# 영어
from nltk.tokenize import word_tokenize
import nltk# naive bayes 분류기는 지도학습이라 정답을 알려주어야 한다
train = [('i like you', 'pos'),
('i hate you', 'neg'),
('you like me', 'neg'),
('i like her', 'pos')]train[0]all_words = set(word.lower() for sentence in train for word in word_tokenize(sentence[0]))
all_words# 말 뭉치 대비해서 단어가 있고 없음을 표기
t = [({word : (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t# naivebayes 분류기 훈련
# like가 있을 때, positive할 확률이 1.7:1이다
# 이렇게 각 단어별로 독립적으로 확률을 계산하기 때문에 naive하다고 한다
classifier = nltk.NaiveBayesClassifier.train(t) # train() : sklearn의 fit과 같은 것
classifier.show_most_informative_features()# 학습 결과로 테스트 진행
test_sentence = 'i like MeRui'
test_sent_feature = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_feature# 결과 : positive
classifier.classify(test_sent_feature)Naive Bayes Classifier를 이용한 감성분석 - 한글
from konlpy.tag import Okt
pos_tagger = Okt()# 정답을 알고 있는 문장으로 훈련용 데이터를 주기
train = [
('메리가 좋아', 'pos'),
('고양이도 좋아', 'pos'),
('난 수업이 지루해', 'neg'),
('메리는 이쁜 고양이야', 'pos'),
('난 마치고 메리랑 놀거야', 'pos')]# 전체 말뭉치 생성
all_words = set(word.lower() for sentence in train for word in word_tokenize(sentence[0]))
all_wordst = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
tclassifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()test_sentence = '난 수업을 마치면 메리랑 놀거야'test_sent_feature = {
word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_featureclassifier.classify(test_sent_feature)# 형태소 분석을 한 후 품사를 단어 뒤에 붙여넣기
def tokenize(doc):
return ['/'.join(t) for t in pos_tagger.pos(doc, norm = True, stem = True)]train_docs = [(tokenize(row[0]), row[1]) for row in train]
train_docs# 말뭉치 생성
tokens = [t for d in train_docs for t in d[0]]
tokensdef term_exists(doc):
return {word: (word in set(doc)) for word in tokens}train_xy = [(term_exists(d), c) for d, c in train_docs]
train_xyclassifier = nltk.NaiveBayesClassifier.train(train_xy)test_sentence = [('난 수업을 마치면 메리랑 놀거야')]test_docs = pos_tagger.pos(test_sentence[0])
test_docsclassifier.show_most_informative_features()test_sent_feature = {word : (word in tokens) for word in test_docs}
test_sent_featureclassifier.classify(test_sent_feature)자연어 처리 - 문장의 유사도 측정 count vectorize
- CountVectorizer : sklearn이 제공하는 문장을 벡터로 변환하는 함수
# CountVectorizer : sklearn이 제공하는 문장을 벡터로 변환하는 함수
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)# 거리를 구하는 것으로 지도학습X(라벨이 필요하지 않다)
contents = ['상처받은 아이들을 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람들은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아']# 형태소 분석 엔진은 Okt
from konlpy.tag import Okt
t = Okt()# # 한글은 형태소 분석이 필수이다
contents_tokens = [t.morphs(row) for row in contents]
contents_tokens# 형태소 분석된 결과를 다시 하나의 문장씩으로 합친다
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize# 벡터라이즈 수행
# 4개의 문장에 전체 말뭉치의 단어가 17개였다
X = vectorizer.fit_transform(contents_for_vectorize)
Xnum_sample, num_features = X.shape
num_sample, num_features# 확인
vectorizer.get_feature_names_out()X.toarray().transpose()# 테스트용 문장
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize# 벡터로 표현
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
# 단순히 기하학적인 거리 사용
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())dist = [dist_raw(each, new_post_vec) for each in X]
distprint('Best post is ' , dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is --> ', contents[dist.index(min(dist))])# 관건은 벡터로 잘 만드는 것과 만들어진 ㅣ벡터 사이의 거리를 잘 계산하는 것
for i in range(0, len(contents)):
print(X.getrow(i).toarray())
print('-'*40)
print(new_post_vec.toarray())자연어 처리 - 문장의 유사도 측정 tfidf vectorize
- TF-IDF : 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법 (참고 : https://wikidocs.net/31698)
from sklearn.feature_extraction.text import TfidfVectorizerX = vectorizer.fit_transform(contents_for_vectorize)
num_sample, num_features = X.shape
num_sample, num_featuresX.toarray().transpose()new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()# 두 벡터의 크기를 1로 변경한 후 거리 측정
# 한쪽 특성이 도드라지는 것을 막을 수 있다
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())
dist = [dist_norm(each, new_post_vec) for each in X ]
print('Best post is ' , dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is --> ', contents[dist.index(min(dist))])네이버 지식인 검색 결과에서 유사한 문장 찾기
import urllib.request
import json
import datetimedef gen_search_url(api_node, search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display' + str(disp_num)
return base + node + param_query + param_start + param_dispdef get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
print('[%s] Url Request Success' % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))client_id = '<개인 id>'
client_secret = '<개인 password>'
url = gen_search_url('kin', '파이썬', 10, 10)
one_result = get_result_onpage(url)
one_resultone_result['items'][0]['description']def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>', '')
return input_strdef get_description(pages):
contents = []
for sentences in pages['items']:
contents.append(delete_tag(sentences['description']))
return contentscontents = get_description(one_result)
contents# 형태소 분석
from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Okt
t = Okt()
vectorizer = CountVectorizer(min_df=1)contents_tokens = [t.morphs(row) for row in contents]
contents_tokens# 형태소 분석 단위로 띄어쓰기
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorizeX = vectorizer.fit_transform(contents_for_vectorize)
Xnum_samples, num_features = X.shape
num_samples, num_featuresvectorizer.get_feature_names_out()new_post = ['파이썬을 배우는데 좋은 방법이 어떤 것인지 추천해주세요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorizenew_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())dist = [dist_raw (each, new_post_vec) for each in X]
distprint('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is --> ', contents[dist.index(min(dist))])
min(dist)# Normalize
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())dist = [dist_norm(each, new_post_vec) for each in X]
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is --> ', contents[dist.index(min(dist))])어렵...
💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅