학습내용
불균형 데이터 처리
1. 이상치 제거
import numpy as np
## 타겟 이상치(outlier)를 제거 / 95% 이상의 데이터 제거
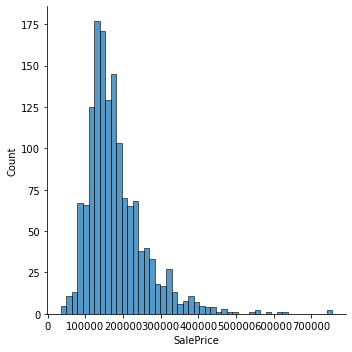
df['SalePrice'] = df[df['SalePrice'] < np.percentile(df['SalePrice'], 99.5)]['SalePrice']2. Log transform
회귀 문제의 경우 target값이 불균형일 경우 성능저하가 있을 수 있다. log transform을 해줌으로써 이를 어느 정도 해결해줄 수 있다.
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
from sklearn.compose import TransformedTargetRegressor
#방법1
plots['transformed']=np.log1p(target)
---
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestRegressor(random_state=2)
)
#방법2
tt = TransformedTargetRegressor(regressor=pipe,
func=np.log1p, inverse_func=np.expm1)
# inverse_func은 log1p를 이용하여 학습시키고 다시 exponential function을 통해 원래 값으로 되돌려줌
tt.fit(X_train, y_train)
tt.score(X_val, y_val)3. class weight
classification 모델에서 class 개수의 불균형이 있으면 제대로 학습이 되지않음. 이를 해결하기 위해 모델에(ex. tree) class weight를 줄 수 있음. 원리는 적은 class의 예측 실패시 큰 penalty를 주는 형태
pipe = make_pipeline(
OrdinalEncoder(),
# DecisionTreeClassifier(max_depth=5, class_weight='balanced', random_state=2)
DecisionTreeClassifier(max_depth=5, class_weight={False:custom[0],True:custom[1]}, random_state=2))
pipe.fit(X_train, y_train)
print('검증 정확도: ', pipe.score(X_val, y_val))번외
- likage : 데이터의 target을 통해 파생된 형태의 feature가 모델 학습에 사용되는 경우.
꽤 많은 데이터가 가지고 있는 문제로 이를 잘 해결하여 모델링해야함.
- pie chart
plt.figure(figsize = (8,6))
plt.pie(train['price_range'].value_counts(), labels = train['price_range'].value_counts().index,
autopct = "%.1f%%", shadow = True, startangle = 90)
plt.title('Price_range')
plt.show()