학습내용
Elbow 방법
cluster들의 SSE 계산을 통해 k를 결정하는 방법
for i in range(2,11):
kmeans = KMeans(n_clusters = i, random_state=42)
labels = kmeans.fit_predict(points)
points['label'] = labels
for j in range(len(pd.Series(labels).unique())):
plt.scatter(points[points['label']==j]['x'], points[points['label']==j]['y'])
plt.title('cluster : '+str(i))
plt.show()
SSE.append(kmeans.inertia_)
sil_score.append(silhouette_score(points, labels, metric='euclidean'))출력예시
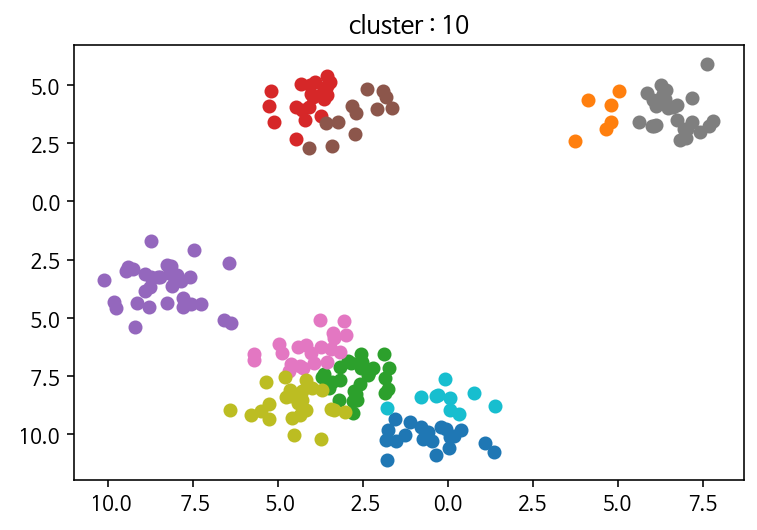
#elbow 방법
plt.plot([2,3,4,5,6,7,8,9,10],SSE, marker='o', color = 'r')
plt.title('cluster 수에 따른 SSE')
plt.show()
#elbow 지점 5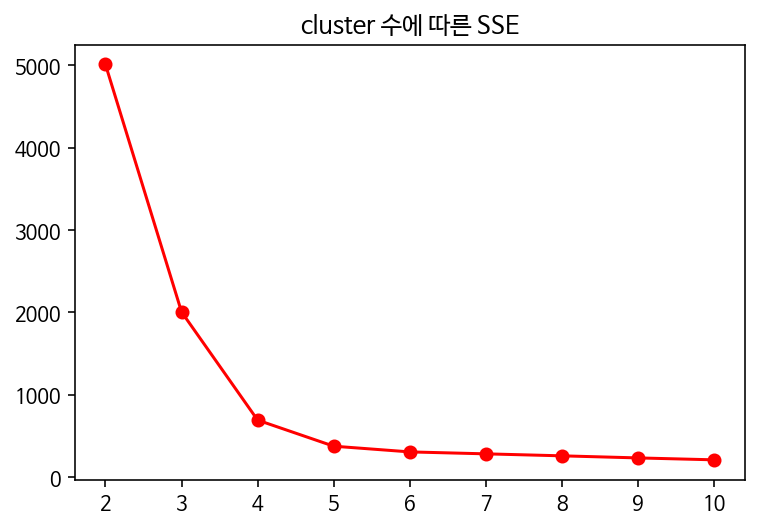
silhouette
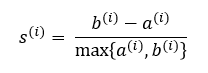
위의 수식으로 silhouette값이 계산되며 b는 cluster간의 거리, a는 cluster내의 거리이다. 최적의 k로 설정된 cluster는 silhouette값이 1에 가깝다.
from sklearn.metrics import silhouette_score, silhouette_samples
#sample은 개별 데이터에 대한 실루엣값, 이를 평균내면 score임
silhouette_score(data, 클러스터링으로 예측된 결과, metric = 'euclidean'
silhouette_sample(data, 클러스터링으로 예측된 결과, metric = 'euclidean'#silhouette
plt.plot([i for i in range(2,11)], sil_score, marker='o', color = 'green')
plt.title('cluster 수에 따른 silhouette')
plt.show()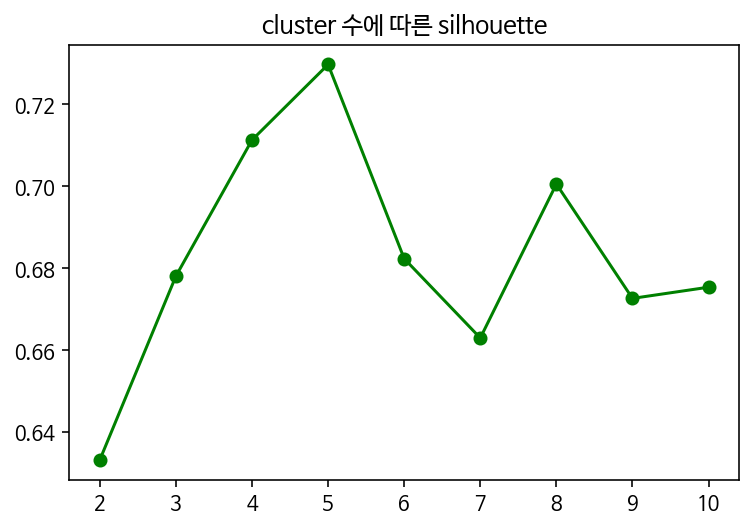
추가내용
pca 가능 범위는 샘플의 개수도 영향을 끼침
샘플의 크기가 feature 수 보다 작을 경우 샘플의 크기보다 높은 차원으로 pca불가능
eigenvector를 생성하지 못해서 그런 것으로 생각됨
