
20211027
1. Linear layer
Linear 레이어: 선형 변환 활용 → 데이터를 특정 차원으로 변환
더 높은 차원으로의 변환은 데이터를 더 풍부하게 표현할 수 있게 하고, 반대의 경우 데이터를 집약할 수 있다.
-
Linear 레이어는
(입력의 차원, 출력의 차원)에 해당하는 Weight를 가짐 -
Parameter: 모든 Weight의 모든 요소 (지나치게 많은 Parameter는 과적합을 가져올 수 있음)
-
훈련(Training): 가장 적합한 Weight를 알아서 찾아가는 과정
-
편향(Bias)
-
선형변환된 값 + b로 표현
-
편향이 없다면 파라미터를 변화시켜도 정확하게 근사할 수 없을 수 있음
-
2. Convolution layer
수십 개의 필터를 중첩해서 목적에 도움이 되는 정보는 선명하게, 그렇지 않은 정보는 흐리게 만드는 필터를 훈련을 통해 찾는 역할.
Convolution 레이어는 필터 구조 안에 Locality 정보가 보존됨.
불필요한 파라미터 및 연산량을 제거하고 훨씬 정확하고 효율적으로 정보를 집약.
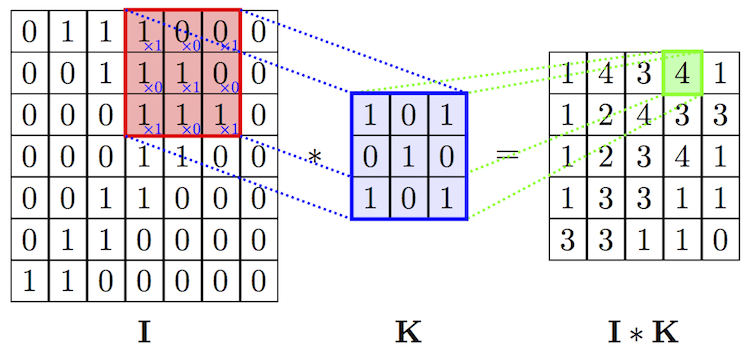
출처: AIFFEL FUNDAMENTALS_SSAC2 20. 딥러닝 레이어의 이해(1) Linear, Convolution-
Stride: 필터를 몇 칸씩 이동시킬지 지정
-
Padding
-
input 테두리에 0을 추가하여 입력의 형태 유지
-
모서리의 픽셀도 내곽 픽셀처럼 취급되어 해당 정보를 활용할 수 있게 함
-
-
(필터의 개수 x 필터의 가로 x 필터의 세로)로 이루어진 웨이트를 가짐
4. Pooling layer
-
필터 사이즈가 너무 작으면 유의미한 정보를 담아내기 어려울 수 있으며, 파라미터는 줄지만 object가 필터 경계선에 걸려 인식이 불가할 수 있음
-
필터 사이즈를 키우게 되면 파라미터 사이즈와 연산량이 커질 뿐 아니라, Accuracy도 떨어지게 될 가능성이 높음
Receptive Field(수용 영역)
입력 데이터의 수용 영역이 충분히 커서 object의 특성이 충분히 포함되어 있어야 정확한 detection 가능
Max Pooling layer
효과적으로 Receptive Field를 키우고, 정보 집약 효과 극대화.
영역 안에서 가장 큰 값을 뽑아냄
-
translational invariance 효과
-
이미지는 약간의 상하좌우 시프트에도 내용상 동일한 특징을 가짐
-
동일한 특징을 안정적으로 잡아낼 수 있는 긍정적 효과 → 오버피팅 방지, 안정적인 특징 추출 효과
-
-
Non-linear 함수와 동일한 피처 추출 효과
-
중요한 피처만을 상위 레이어로 추출
-
분류기의 성능을 증진시키는 효과
-
-
Receptive Field 극대화 효과
5. Decoder Layers for Reconstruction
-
Upsampling 레이어
-
Nearest Neighbor: 복원해야 할 값을 가까운 값으로 복제
-
Bed of Nails : 복원해야 할 값 0으로 처리
-
Max Unpooling : Max Pooling 때 버린 값으로 복원
-
참고 자료
Linear transformations and matrices | Essence of linear algebra, chapter 3
행렬과 선형변환(feat.마인크래프트 스티브) Linear Transformation
