
간단한 정리
Attention Is All You Need는 구글에서 2017년 12월 6일에 발표한 논문이다.
기존에 존재했던 recurrence와 convolution가 아닌 Attention mechanism에 기반한 Transformer를 제안한다.
저자는 제안한 메소드에 대해 3가지의 장점을 제시한다.
- 좋은 성능
- 병렬화의 가능화
- 병렬화를 통한 학습시간 감소
해당 게시글에선
배경 👉 메소드 👉 실험 결과
순서로 정리해보고자 한다.
📌배경
기존 recurrence 기반의 모델(RNN, LSTM, GRU)들은 sequential data에 좋은 성능을 보여줬다.
아래 그림과 같이 이전 상태($$ h_n $$)
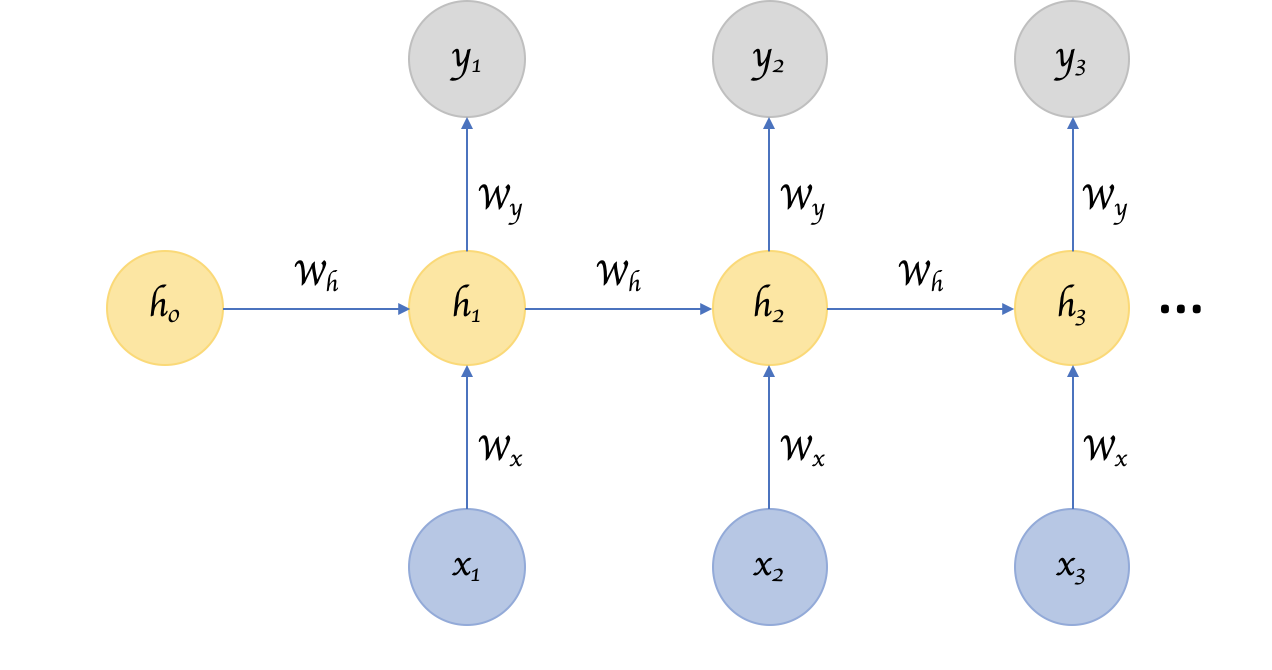
recurrence 기반의 모델들의 장점은
- 좋은 성능
이 있으며 단점으로는
- 많은 연산량
을 꼽을 수 있다.
Transformer는 recurrence 모델의 장점을 살리며, 단점을 상쇄하고자
attention mechanism을 도입한다.
결과적으로, 짧은 시간 안에 학습이 가능하면서 동시에 성능도 좋은 모델이 바로 Transformer 인 셈이다.
📌메소드
📍전체 구조
일단 Transformer의 전반적인 형태부터 소개를 한 후, 세부적인 기능들이 어떻게 작용하는지 알아보도록 하겠다.
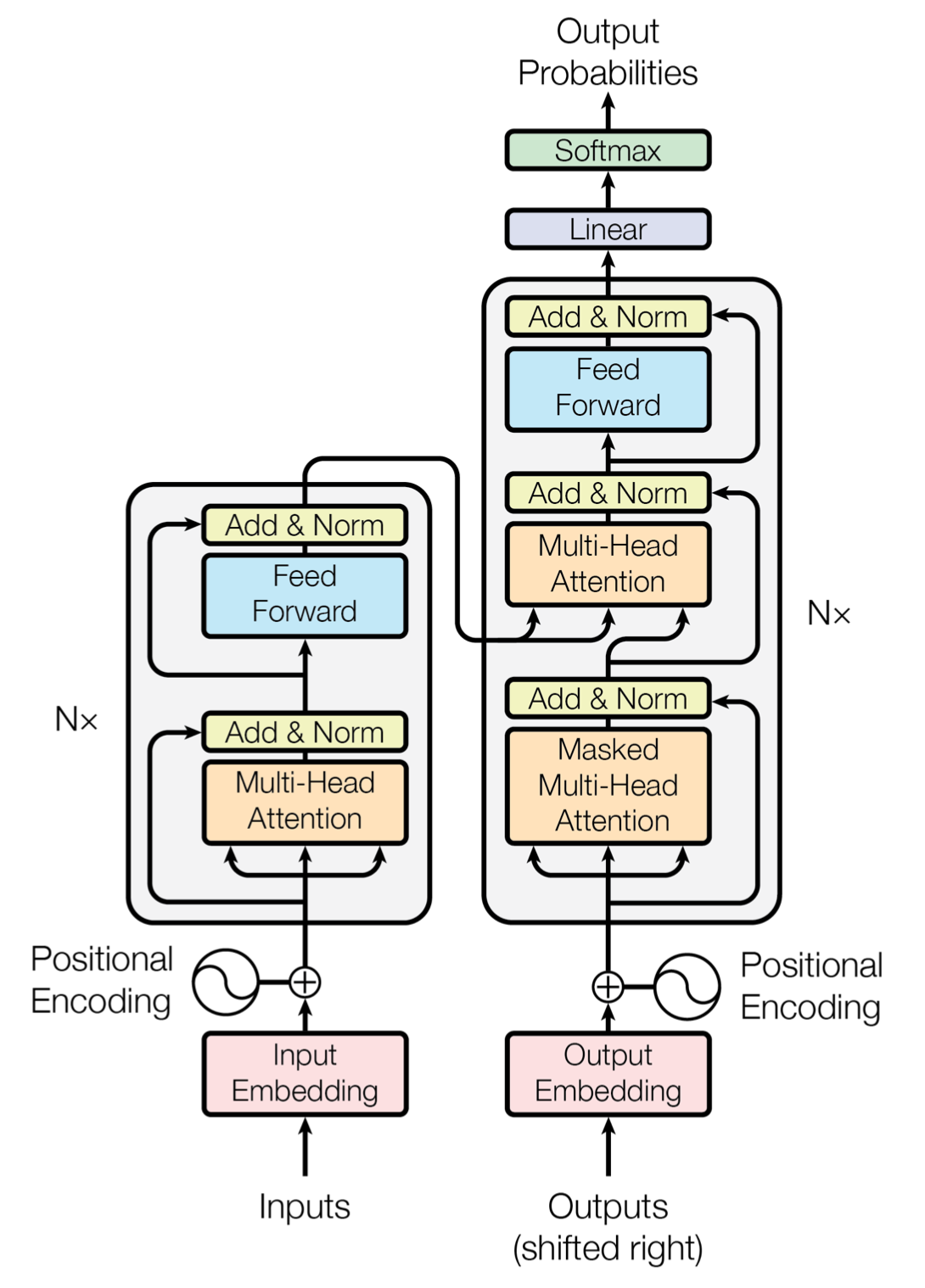
Transformer의 전반적인 형태는 위 그림과 같다.
왼쪽 덩어리(?)인 Encoder와 오른쪽 덩어리인 Decoder로 구성되어 있다.
각 Encoder와 Decoder는 비슷한듯 다른 구조로 설계되어 있다.
비슷한 점으로는 Attention이라는 연산과 Feed Forward라는 연산이 존재한다는 점이다.
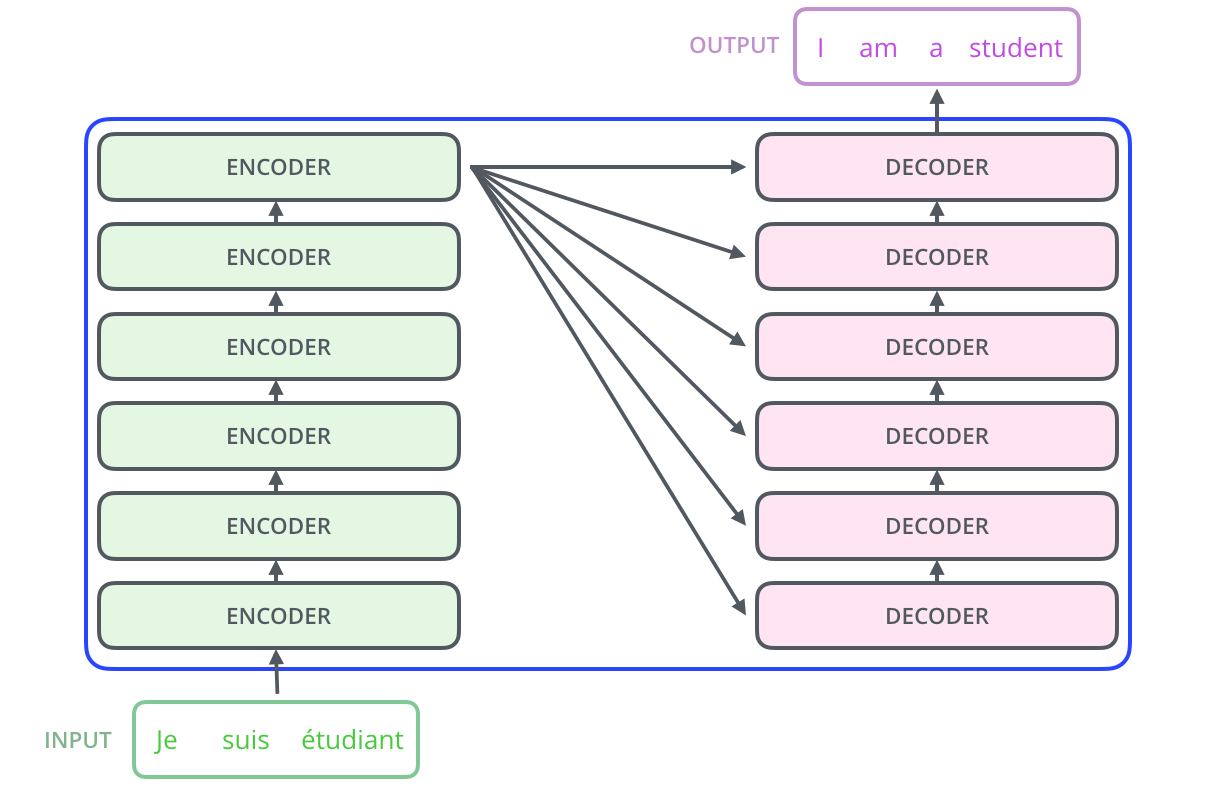
위 그림 상에는 한개의 encoder가 한개의 decoder로 정보를 전달하는 것으로 표현되어 있으나,
실제 해당 논문에서 설계한 Transformer는 input에 대해 6개의 encoder를 통과시킨 후,
6개의 decoder에 뿌려주는 형태를 띄고 있다.(아래 그림 참고)
📍Attention
Attention은 위에서 확인했듯, Encoder와 Decoder 둘 다에서 역할을 하고 있었다.
해당 논문에서는 2가지 Attention을 사용했다고 한다.
첫번째는 Scaled dot attention이다.
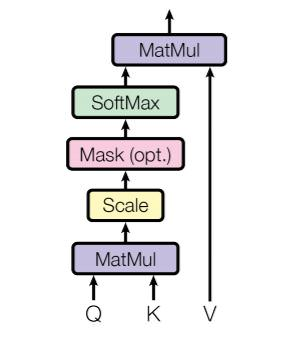
일단 attention의 input은 query, key, value이다.
이들을 이용해 output을 도출한다.
query와 key는 의 차원을 가진 벡터이며
value는 의 차원을 가진 벡터이다.
attention 연산은 다음 그림과 같이 연산된다.
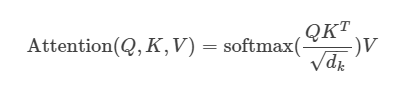
두번째 Multi-head attention은 기본 attention 연산과 유사하게 진행된다.
기존의 attention은 전체 dimension에 대해서 하나의 attention만 적용시켰다.
하지만 Multi-head attention은 전체 dimension을 로 나눠서 attention을 번 적용시키는 방법이다.
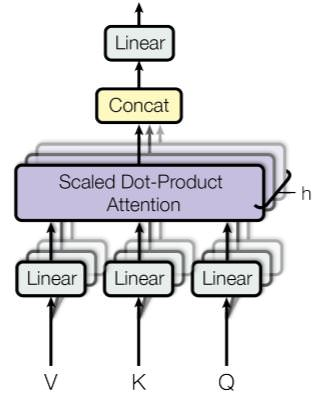
그렇다면 Transformer에서는 attention이 어떻게 적용될까?
- decoder에서 사용된 attention의 query들은 이전 decoder layer에서 가져온다.
그리고 encoder에서 온 key, value를 사용한다. - encoder의 attention에 들어가는 모든 query, key, value는 같은 sequence에서 온다.
이를 self-attention이라고 한다.
📍Feed-Forward Networks
feed-forward networks는 다음 그림과 같은 연산을 진행한다.
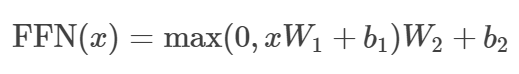
📍Embeddings and Softmax
입력에 대해서 다른 모델들과 동일하게 token으로 변환하여 사용한다.
입력 token을 의 차원으로 바꿔주고 softmax를 취해준 후 decoder의 결과 값을 predicted next token으로 다시 linear transformation해서 변환해준다.
📍Positional Encoding
기존 convolution, recurrence 기반의 모델들은 데이터의 위치를 고려해준다.
하지만 attention은 위치를 고려하지 않으므로, positional encoding이라는 것을 추가해줘야 한다.
transformer에서 사용하는 positional encoding은 다음과 같다.
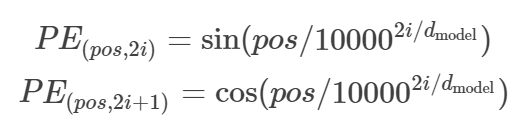
📌실험 결과
학습에는 WMT 2014 English-German 데이터 셋을 사용했다.
450만 개의 영어-독일어 문장 쌍이 있다.
WMT 2014 English-French도 사용됐다.
360만 개의 문장 쌍이 존재한다.
학습 시 25000개의 token을 포함하는 문장 쌍을 하나의 batch로 사용한다.
Optimizer는 Adam을 사용하였으며 정규화는 세가지 방식을 사용한다.
- Residual dropout
- Attention dropout
- label smootiong
결과적으로 WMT 2014 English-German에 대해서 이전보다 2 높은 28.4 BLEU를 기록했으며
8개의 GPU로 8일 동안 학습시켜 41.8점의 BLEU state-of-the-art 단일 모델이다.
[참고자료]
https://arxiv.org/abs/1706.03762
https://wdprogrammer.tistory.com/72
