.png)
오늘은 2021년 IEEE winter conference에 accepted된 paper를 소개하도록 하겠습니다. 논문은 다음과 같습니다.
- Title : Noise as a Resource for Learning in Knowledge distillation
- Link : https://arxiv.org/abs/1910.05057
Summary
Knowledge distillation framework에 noise를 더하였을때, 어떠한 effect가 있는지 확인한 논문입니다. 본 연구에서는 3가지의 방법을 제안하였습니다. 저자가 제안한 방법은 다음과 같습니다.
- Fickle Teacher
- Soft Randomization
- Messy Collaboration
Related work
본론을 설명하기 앞서 간략하게 Related work에 대해 살펴보도록 하겠습니다.
FGSM
- [Nicholas Carlini and David Wagner, 2017].
.png)
Figure 1 : FGSM
팬더 image에 small noise를 주었다고 가정해본다면, 사람은 팬더(panda)라고 생각할 수 있지만 neural network는 이를 긴팔원숭이(gibbon)로 잘못 예측하는 오류를 범합니다. 저자는 이러한 adversarial example에 대해서 강건함을 보장해주는 방법으로 FGSM을 제안하였습니다. 수식은 아래와 같습니다.
Adversarial example = =
- 의 gradient를 계산한 다음 sign값을 취해주고 을 곱해주어 image에 noise를 준다.
Objective function
loss를 최대로 만드는 adversarial example에 대한 의 값이 최소가 되도록 학습을 진행합니다.
PGD는 위에서 설명한 FGSM과 달리 여러 step 반복해서 attack을 진행합니다.
Related work
Knowledge distillation [Hinton et al. 2015]
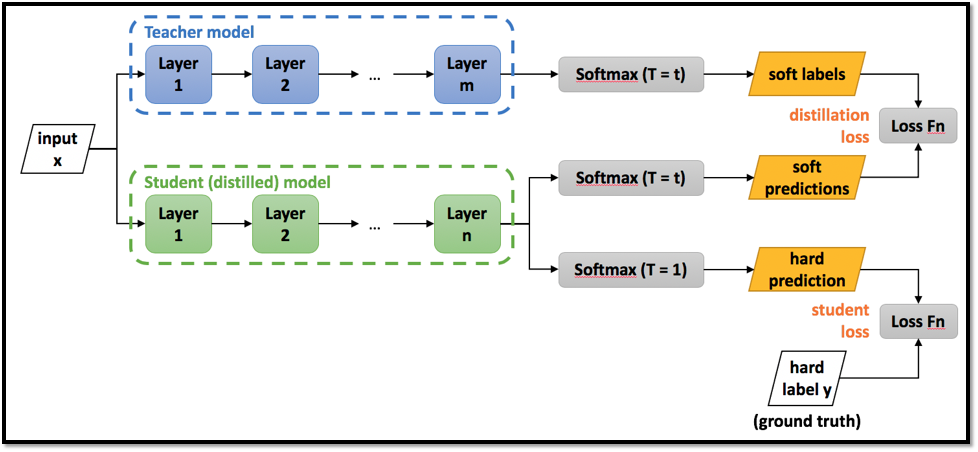
Figure 2 : Knowledge distillation Framework
Hinton이 제안한 knowledge distillation은 teacher model의 output(soft labels)과 student model의 output(soft predictions)의 kl divergence loss를 minimize함과 동시에, hard predictions, hard label(ground truth)간의 cross entropy loss를 minimize 하는 방향으로 학습을 진행합니다.
Objective function
Method
다음은 저자가 제안한 Method에 대해 살펴보도록 하겠습니다.
Soft Randomization
.png)
Figure 3 : Soft Randomization
첫번째 설명드릴 방법은 soft randomization입니다. soft randomization은 input data에 gaussian noise를 적용한 방법입니다. 수식은 아래와 같습니다.
- Teacher model의 input : raw data
- Student(distilled) model의 input : raw data + gaussian noise
즉, teacher model에는 raw image(ground truth)가 입력으로 들어가고 student model에는 gaussian noise가 가해진 image가 입력으로 들어갑니다.
Objective function
Experiment settings
- Hyper parameter(, ) : 는 0.9, = 4
- Model : Wide-Residual Network
Messy Collaboration
.png)
Figure 4 : Messy Collaboration
2번째로 설명드릴 방법은 Messy Collaboration입니다. Messy collaboration은 teacher model로부터 student model로 knowledge를 distill하는동안, 특정 확률로 input data가 가지는 label을 다른 label로 변경하는 방법을 의미합니다. 이때 특정 label이 선택될 확률은 각 class별로 동일합니다. (uniform distribution)
Experiments
Hyper parameter
- Optimizer : SGD with 0.9 momentum
- Epoch : 200
Model
- Teacher Network : WRN-40-2
- Student Network : WRN-16-2
Datasets
- Train : CIFAR-10
- Test : CIFAR-10, CINIC, SVHN
Experiment Results
.png)
Figure 5 : iid(CIFAR-10) / ood data(CINIC, SVHN)에 대한 test accuracy
용어설명
GA(baseline) : input data에 gaussian augmentation을 적용한 경우.
- Student Network : WRN-16-2을 사용하여 train 및 test를 진행
- Baseline : Knowledge distillation 적용하지 않음.
SR : knowledge distillation에 soft randomization을 적용한 경우.
- 에 따른 test accuracy
- iid뿐만 아니라, ood에 대해서도 전반적으로 성능 향상을 보임.
.png)
Figure 6 : PGD attack sigma값에 따른 robustness visualization
- PGD attack을 가할 step size : 20
- = 0.2일때, iid, ood에 대해 soft randomization이 좀 더 robust함
.png)
Figure 7 : CIFAR-10/SVHN에 corruption rate / noisy label rate → test accuracy
- Noisy label : messy collaboration( true label을 다른 label로 변경)
- Corruption rate : teacher model output에 corruption을 줌.
실험해석
- Model : wrn-40-2, wrn-16-2
- Messy collaboration을 적용 → baseline에 비해 성능 향상.
- iid, ood data 모두 성능 향상.
Conclusion
본 연구에서는 raw image에 noise를 추가함으로써, iid/ood data에 대해 좀 더 robust함을 확인하였습니다.
- Soft randomization → input data + gaussian noise
- Messy collaboration → label change
