Improving BERT Fine-Tuning via Self Ensemble and Self-Distillation[., 2020]
Knowledge-distillation
.png)
오늘 소개드릴 논문은 다음과 같습니다.
- Improving BERT Fine-Tuning via Self Ensemble and Self-Distillation
Summary
기존 연구에 따르면 BERT계열의 pre-trained language model을 가지고 fine-tuning하는 것은 NLP분야에서 효과적인 방법으로 알려져 있고, 이 방법은 여러 downstream task에 대해 좋은 성능을 보였음이 증명되어져 왔습니다.
Fine-tuning의 예시는 다음과 같습니다.
- Model structure를 변경
- Pre-train task에 대해 re-design
- External data 활용
본 연구에서는 Bert계열 model을 fine-tuning하는 방법으로서 self-ensemble, self-distillation을 제안합니다. 위 방법은 external data를 활용하지 않고 downstream task에 대해 좋은 성능을 보였습니다.
Introduction
BERT계열의 pre-trained model(e.g., XLNet, RoBERTA)은 여러 NLP task에 대해 좋은 성능을 보였습니다.
(e.g., text classification, question answering, natural language inference)
pre-trained model을 downstream task에 대해 적용하는 방법은 다음과 같습니다.
- Feature extraction
- Fine-tuning
본 연구는 두 가지 방법 중, fine-tuning을 통해 downstream task의 성능을 개선하는데 초점을 두었습니다.
Related work
BERT는 label이 없는 large corpus를 가진 dataset을 통해 pre-train하고, MLM/NSP task에 널리 사용되는 모델로 알려져 있습니다.
BERT는 model size에 따라 크게 2가지로 정의됩니다.
- BERT-base : 12-layer transformer encoder
- BERT-large : 24-layer transformer encoder
BERT's contribution
- Bidirectionally trained(양방향으로 학습)
- One-direction(단방향) 언어 모델에 비해 언어 맥락, 흐름에 대해 좀 더 잘 파악
- Masked LM(MLM)
- NSP(Next Sentence Prediction) → 연속해서 다음 단어를 예측
- MLM(Masked Language Model) : 문장의 일부분을 무작위로 마스킹후, 마스킹된 부분을 예측하기 위해 문장 전체를 이용 → token과 다음 token을 동시에 고려
Method
저자는 fine-tuning방법으로 ensemble, knowledge distillation을 제안합니다.
Ensemble BERT
일반적인 ensemble learning에서 적용되는 voting방법에 대해 설명하도록 하겠습니다.
우선 pre-trained BERT를 여러개 가져와 seed값만 차별화하고 각 model에 대해 fine-tuning을 진행합니다.
.png)
예를 들어 개의 BERT로 ensemble을 진행한다면, 각 BERT model의 가지는 parameter는 아래와 같이 표현됩니다.
.png)
그 다음 각 model의 output를 aggregation이후, 가장 높은 확률을 뱉어주는 output을 선택하는 방식으로 동작합니다. 그러나 이 방법은 여러개의 BERT를 모두 학습시켜야 하므로 computing cost가 많이 듭니다.
위 문제의 해결방안으로 저자는 Averaged bert를 제안하였습니다.
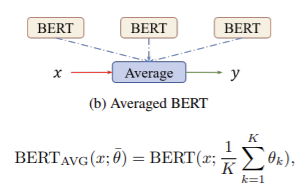
Averaged bert는 ensemble model의 cost를 줄이는 방법으로, 각 fine-tuned된 model의 parameter의 average를 학습에 사용할 parameter로 결정합니다.
→ It has better computational and memory cost than Voted bert(majority voting의 경우, cost가 많이 듬.)
Self-Distillation-Averaged(SDA)
.png)
저자는 Ensemble방법에 self-distillation을 더한 SDA라는 방법을 제안합니다.
SDA의 동작 과정에 대해 살펴보도록 하겠습니다.
우선, 각 time step에서 학습될 BERT가 있다고 가정을 해보겠습니다. (t-3, t-2, t-1, t)
-
Student model : 현재 시점(t)에서의 BERT
-
Teacher model : 이전 시점(t-3, t-2, t-1)에서의 BERT의 parameter(student model's parameter)를 평균낸 BERT
- 즉, teacher model은 이전 시점에서의 student model의 정보를 aggregation.
- Teacher model의 paramter()는 moving average방식으로 update를 진행
Objective function
Notation
-
Student BERT :
-
Teacher BERT :
-
: 이전 step model들의 parameter를 평균낸 값
Self-Distillation-Averaged(SDV)
Ensemble방법으로 self-voted-ensemble을 적용한 방법
Objective function
- 나머지는 SDA랑 동일
Experiments
Datasets (text data, NLI data)
.png)
Text classification
- IMDB : Internet Movie dataset(sentiment analysis)
- train/val : 25000
- AG's news : 496,835개의 news article dataset
- DBPedia : 각 wikipedia 문서의 title, abstract만 있는 14개의 class로 구성
- Yelp : Yelp dataset challenge datasets
- 유저의 평점 데이터로 구성되어 있음(1~5)
Natural Language inference
- SNLI : Stanford nlp corpus dataset
- 570k개의 english sentence로 구성되어 있음
- MNLI : Multi-genre natural language inference
- 433k개의 sentence로 구성되어 있음
.png)
- BERT-Base model에 적용되는 여러 방법론들 → fine-tuning에 미치는 영향
- Self-ensemble method : BERT(vote), BERT(avg)
- Self-ensemble + Self-distillation : BERT(sdv), BERT(sda)
앙상블 기반 BERT의 경우, baseline 성능을 능가함.
Conclusions
- External data없이 BERT를 fine-tuning하는 방법으로 self-ensemble, self-distillation을 제안함
- Self-ensemble
- ensemble model의 parameter를 평균내는 방식으로 average bert를 제안
- Self-distillation
- 이전 스텝의 student model의 parameter를 teacher model으로 정의
- 현재 시점의 student model에게 knowledge를 transfer해줌
- 모델의 성능을 향상시킴과 동시에, computing cost를 최대한 줄이는 결과를 도출함
BERT에 knowledge distillation을 적용한 distill BERT
- 작은 capacity를 가진 model로 effetive한 성능을 낸 논문
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[Sanh., 2020]
