
캐시란?
어떤 요청에 대한 결과를 저장해놓는 임시 저장소이다. 반복되는 요청이 있을때 그 요청이 동일한 결과를 반환한다면 도입을 고려하는게 좋다. 그럼 따로 로직을 태우지않고 임시 저장소에 있는 결과를 바로 반환하기때문에 성능향상을 기대할 수 있다.
스프링에서의 캐싱
스프링답게 구현 기술에 종속되지 않도록 캐싱 자체를 추상화 시켜놨고
구현체는 알아서 갈아끼우면 된다. 간단하게 사용방법을 말하자면
-
설정클래스에
@EnableCaching을 붙여서 캐시 관련 설정을 스프링이 자동구성 할 수 있게 하면 어노테이션으로 쉽게 캐시를 사용할 수 있게된다. -
캐시 관련된 애노테이션이 붙은 메소드는 AOP로 인한 프록시가 생성되어서 메소드호출을 가로채는데, 이때 붙은 애노테이션에 맞는 캐시로직을 덧붙여서 실행한다.
대표적인 애노테이션 세개만 알아보자@Cacheable:CacheHit이면 메소드의 리턴값을,CacheMiss이면 기존 로직을 실행해서 저장소에 채운다.@CacheEvict: 영어사전에 치면Evict 쫓아내다이렇게 나온다. 말 그대로 캐시를 쫓아내고, 메소드의 키 값에 해당하는 캐시만 제거한다. 모두 제거하려면 allEntries 엘리멘트를 추가하면 된다.@CachePut
-> 저장만 한다, 캐시값을 갱신할때 사용하면 좋다.
적용기
일단 간략하게 알아봤는데 내 프로젝트에서는 책 전체조회랑 책 상세조회 api에 적용하면 좋을거 같았다. 왜냐하면 두 api는 많은 이용자가 요청하는 api인 동시에 계속 같은 결과를 반환하고 변경이 잘 일어나지않기때문이다.
주의할점
만약 캐싱되어있는 상태에서 DB의 값이 변경되면 캐싱된 데이터와 db의 값이 일치하지 않는 데이터 정합성 문제가 생길 수 있어서 전략을 잘 짜야한다. 내 프로젝트의 경우는 EC2 두개로 스케일 아웃을 해놓았기 때문에 스프링 캐시매니저 기본값인 ConcurrentMapCacheManager를 쓰면 두 EC2 인스턴스 각각 메모리안에 캐시를 저장하기 때문에 서버간 데이터 공유가 안된다. (로컬 캐싱 전략) 그래서 db에 있는 값이 변경될때 캐시에 있는 값과 db에 있는 값과 다를 수 있다. 그래서 나는 Redis를 캐시저장소로 써서 정합성을 맞췄다.(글로벌 캐싱 전략)
결과
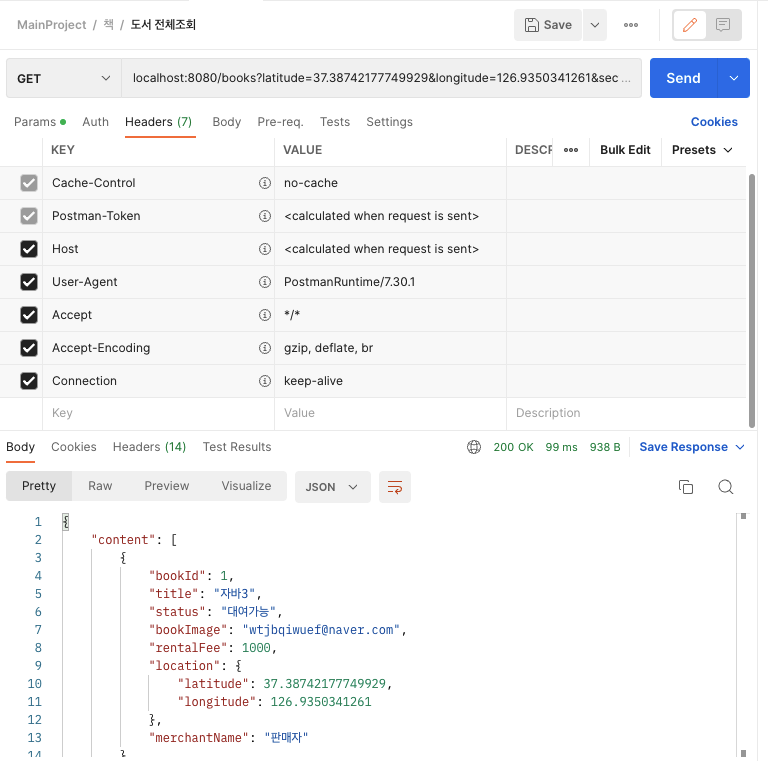
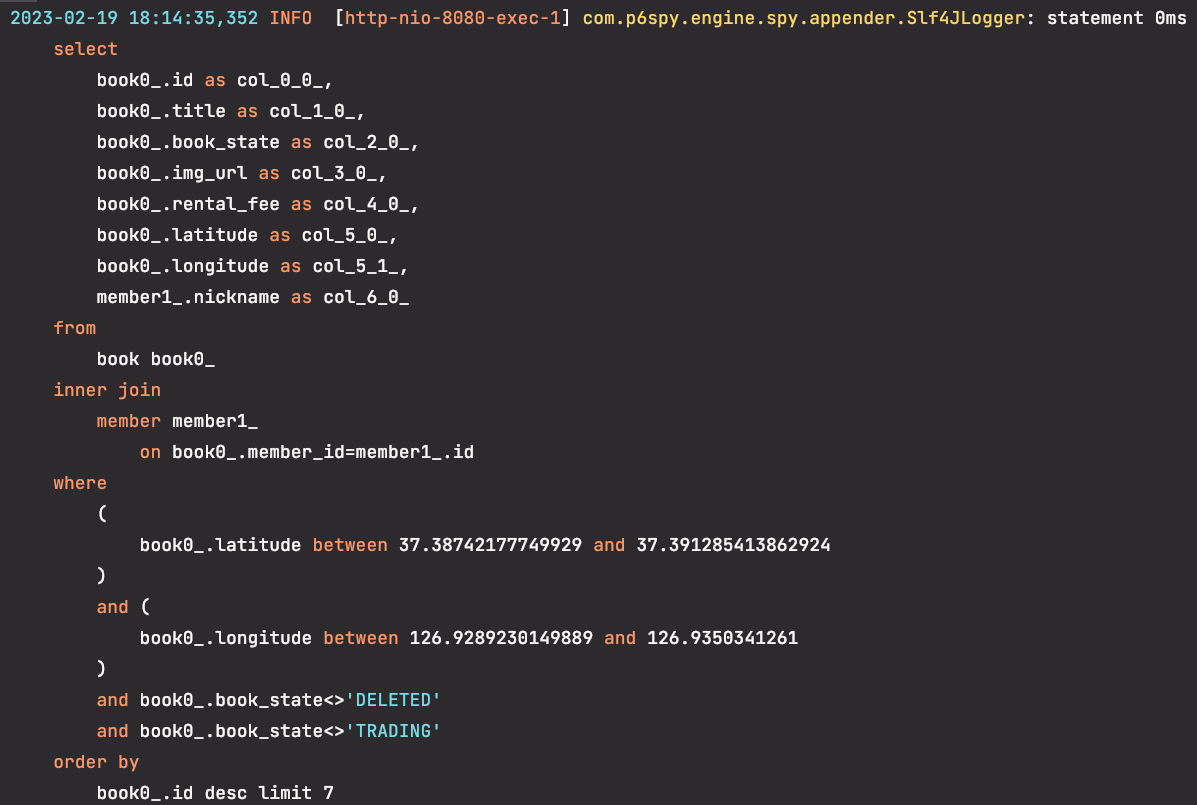
처음에는 조회 요청과 함께 쿼리가 나갔는데
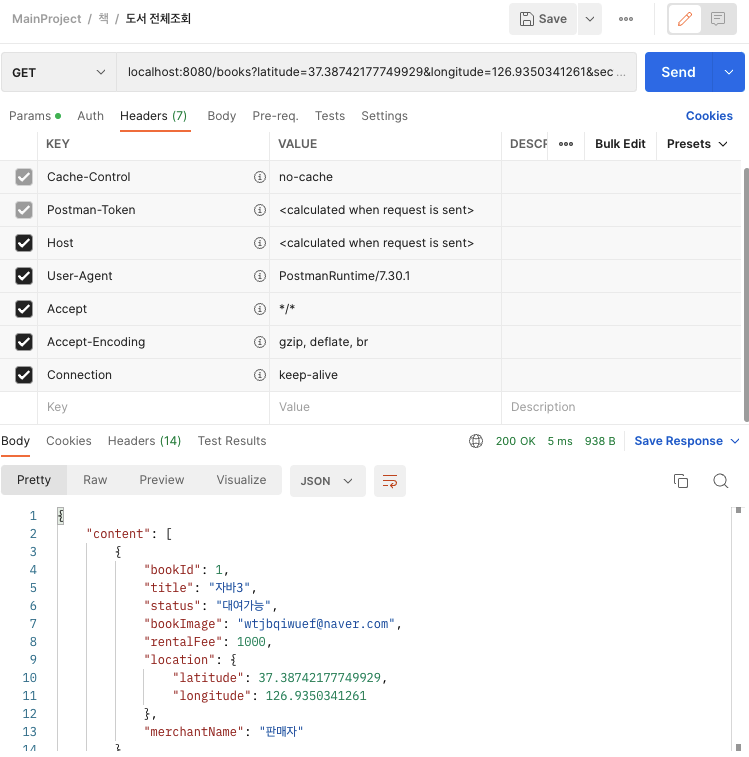
그다음 요청 부터는 조회쿼리가 나가지 않았고 응답시간도 99ms->에서 5ms로 매우 빨라졌다.
