1. Parameter update schemes
x += learning_rate * dx
- SGD가 속도가 느린이유?
- 이에 대한 개선 방법?
- momentum update : conversion을 촉진한다.
v = mu * v - learning_rate *dx
mu는 마찰 가속도로 - Nesterov momentum update(nag)
- momentum step을 미리 계산해서 사용함
- AdaGrad update
- SGD의 보완
- cache로 나눠줌
- 모든 파라미터들이 동일 rate가 아니라 cache가 빌딩업되어 각각 다른 값의 영향을 받음
- 문제점 : 시간에 따라 step사이즈가 바뀜. learning rate가 0에 가까워짐
- RMSProp update
- step 사이즈를 0으로 줄어가는 AdaGrad의 단점들을 보완함
- decay rate를 도입함
- cache값을 점점
- Adam update
- RMSProp + momentum 결합 형태
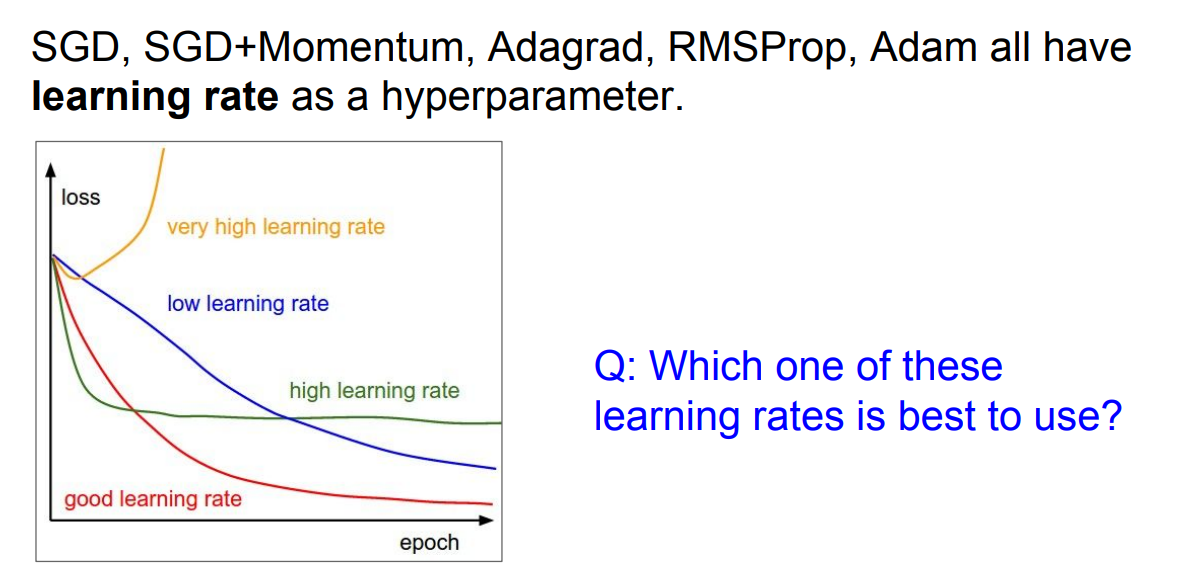
- 이중에 어떤것도 최선이 아니다
- learning rate은 시간에 따라서 decay하는 것이 최적이다.
- 초기 다소 큰 learning rate을 적용하고 => 빠른 conversions
- 서서히 learning rate을 decay해주면서 값을 작게 만들어준다.
- step decay : epoch 마다 일정한 간격의 learning rate를 감소시키는 방법
- exponential decay : 주로 이것이 쓰임
- 1/t decay
- 최근에는 default로 Adam이 쓰이는 추세
1st order optimization method : gradient(경사)정보만 상한 것
- SGD, SGD+momentum, Adagrad, RMSProp, Adam이 해당
2nd order optimization method : Hessian을 통해 경사, 곡면의 구성을 알 수 있음
- 학습이 필요없이 바로 최저점을 갈 수 있음
- 그래서 learning rate이 필요 없다.
- 장점 : conversion가 빠름, no hyperparameter(learning rate)
- 단점 : Deep Neaural Net에서 현실적으로 사용이 어렵다
- 큰 단위 행렬 연산 + 역행렬 계산이 필요하기 때문
- BGFS
- L-BFGS : 메모리 사용을 하지 않아 가끔 사용됨, full batch에서 잘 작동하지만 mini batch에서 작동하지 않는다. 즉, full batch상태에서는 사용해 볼만 하다.
2. Model ensembles
- 단일이 아닌 복수개의 독립적인 모델을 학습하여 이들의 결과의 평균을 내줌
- 그러면 성능이 2% 향상이 가능함
- 단점 : 여러개 모델 관리 필요, avaerage 해야 하니까 속도가 느려진다.
- 파라미터간의 앙상블도 성능향상에 가능하다 why stwp 사이즈가 너무 클때 average 하다보면 사이즈가 작아지기 때문
3. Regularization(Dropout)
- 일반 fully connect에서 일부 노드들을 랜덤하게 0으로 설정하면 노드간 연결이 끊긴 것같은 효과가 나옴
-forward pass와 같이 역전파에서도 dropout 된 노드들은 0되어 죽어버 loss function에 영향을 주지 않음, 가중치에 영향을 주지 않음 - 하나의 노드가 약간씩 중복을 가지면서 같이 관찰하면서 학습한다.
- Dropout도 또하나의 앙상블이다.
- 가중치를 공유하는 각각의 모델의 파라미터값을 평균낸 것이라고 해석할 수 있다.
- test 때는 모든 노드가 살아 있으며 기댓값 만큼의 scale 값을 곱해줌
