개요
ML 모델을 만들 때 좋은 성능을 내는 모델을 찾아내기 위한 실험을 여러 번 한다
이 경우 실험 조건과 결과를 기록하는 것이 필수인데, 메모장이나 스프레드시트 같은 것들을 사용하곤 한다.
하지만 실험 인원이 많아지면 각자의 실험 코드가 달라지거나 모델 버저닝을 까먹을 수 있다.
또한 퍼라마터 수가 많아지면 기록이 귀찮게 된다.
ML 모델의 실험, 배포를 쉽게 관리해주는 도구 중 하나가 바로 MLflow이다.
MLflow의 핵심 기능들
-
실험 관리와 트래킹
머신러닝 관련 실험들의 metric, loss 등 실험 내용들을 추적하여 각 실험들의 내용과 결과를 저장해준다.
하나의 MLflow 서버를 두고 여럿이서 각자 자기 실험을 한 곳에 저장할 수도 있다.
실험 내용 뿐만 아니라 실험에 사용한 코드, 하이퍼파라미터, 가중지 파일 등도 저장할 수 있다. -
Model registry
MLflow로 실험을 진행한 모델들을 model registry라는 저장소에 등록할 수 있다.
이 때 버저닝이 자동으로 기록되고, 저장소에 등록된 모델은 다른 사람들에게 쉽게 공유가 가능하다.
ML 실험의 github나 도커 같은 역할을 한다. -
Model Serving
model registry에 등록된 모델을 REST API 형태의 서버로 Serving할 수가 있다.
MLflow Components
MLflow는 4가지 component를 제공한다.
-
Tracking : ML 실험의 파라미터, 코드 버전, metrics, artifact들을 로깅한다. MLflow tracking은 어느 환경에서나 사용할 수 있으며, 결과를 로컬에 저장하거나 서버에 저장해 다른 동료들과 공유할 수 있다.
-
Projects : ML코드를 재사용하기 위한 표준 포맷. 소스 코드가 저장된 폴더일 수도 있고 git repo가 될 수 도 있다. 재현 가능하게 하기 위해 의존성 같은걸 적어놓음
-
Models : 모델을 모델 파일과 코드로 저장. 다양한 플랫폼에 배포 가능한 여러 도구를 제공한다.
-
Registry : 모델 저장소
MLflow tracking 실습
MLflow tracking에 대해서 간단하게 실습해보자
우선 MLflow experiment 라는 것을 생성해주어야 한다.
$ mlflow experiments create --experiment-name my-experimentmlflow experiments list를 입력하면 도커 리스트처럼 experiment들의 리스트와 저장된 디렉토리를 볼 수 있다.
experiments를 생성하면 현재 디렉토리 아래에 mlruns 폴더가 생성되는 것을 볼 수 있다.
그런 다음 MLflow project라는 MLflow를 사용한 코드의 메타 정보를 저장하는 것을 만들어야 한다.
보통은 MLproject라는 파일과 실험 코드가 들어있는 형태이다.
logistic_regression
├── MLproject
└── train.py
그럼 아래의 커맨드를 입력하면 MLflow project 폴더 안의 실험이 아까 만든 experiment에 tracking되고 저장된다.
mlflow run logistic_regression --experiment-name my-experiment --no-conda뒤에 --no-conda라고 conda를 사용하지 않겠다 명시했는데 이러면 현재 사용하고 있는 환경에서 그냥 실행된다.
하지만 보통 여럿이서 실험을 돌릴 때에는 환경을 통일하는 것이 대부분이다.
MLflow는 이러한 상황에도 대비해 conda.yml 파일을 만들어주면 자동으로 해당 yaml에 적혀있는 대로 콘다 가상환경을 만들어 거기 안에서 실험을 진행한다.
*(만약 conda.yml 이 없는데 --no-conda도 명시하지 않는다면 그냥 python 하나만 꼴랑 있는 가상환경에서 실험을 돌린다...)
logistic_regression
├── MLproject
├── conda.yml
└── train.py
conda.yml의 예시
name: tutorial
channels:
- defaults
dependencies:
- numpy>=1.14.3
- pandas>=1.0.0
- scikit-learn=0.19.1
- pip
- pip:
- mlflowconda 대신 전용 docker image를 통해 통일된 환경에서 실험을 돌릴 수도 있는데 이것은 나중에 살펴보자.
run을 하면 실험이 기록되고
$ mlflow ui를 실행하면 localhost:5000에 들어가 gui로 실험 시 사용한 커맨드, 결과, 파라미터 등등을 볼 수 있다.
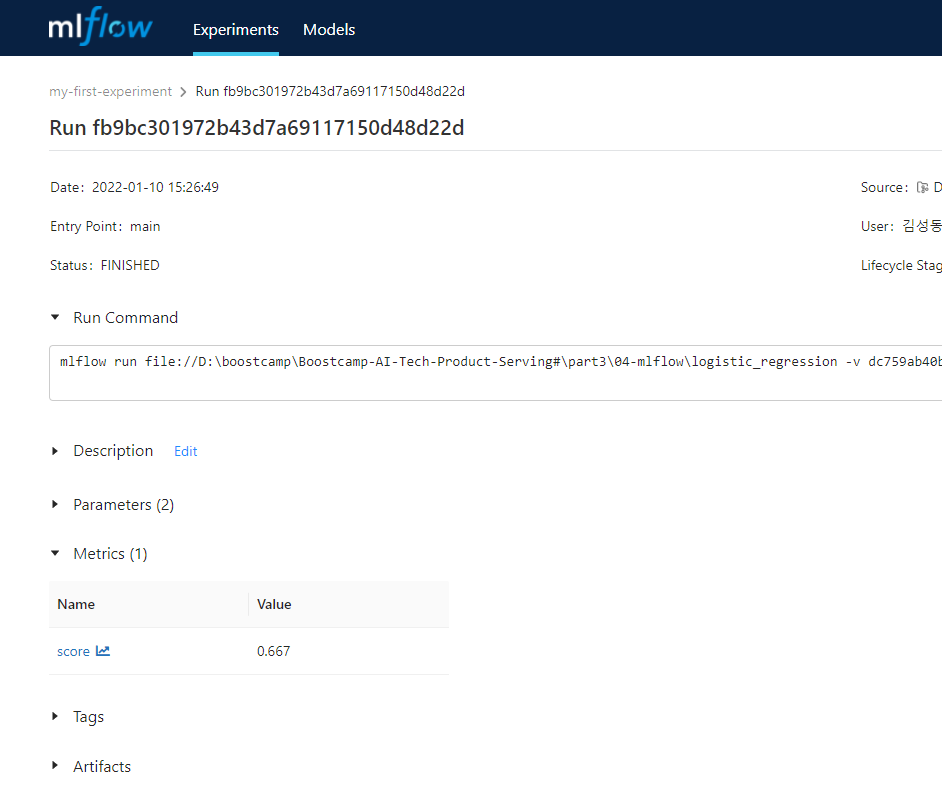
run할 때의 파라미터 지정
앞서 글에서의 실험에서는 train.py에 파라미터들이 고정되어 있어서 다른 파라미터를 사용하려면 train.py를 수정해 주어야만 했다.
MLProject 파일과 train.py를 아래와 같이 수정해주면 run을 돌릴 시 파라미터를 지정해줄 수가 있다.
#MLProject 파일
name: tutorial
entry_points:
main:
parameters:
solver:
type: string
default: "saga"
penalty:
type: string
default: "l2"
l1_ratio:
type: float
default: 0.1
command: "python train.py {solver} {penalty} {l1_ratio}"
lr = LogisticRegression(solver=sys.argv[1], penalty=sys.argv[2], l1_ratio=float(sys.argv[3]))$ mlflow run logistic_regression -P solver="saga" -P penalty="l1" -P l1_ratio=0.1