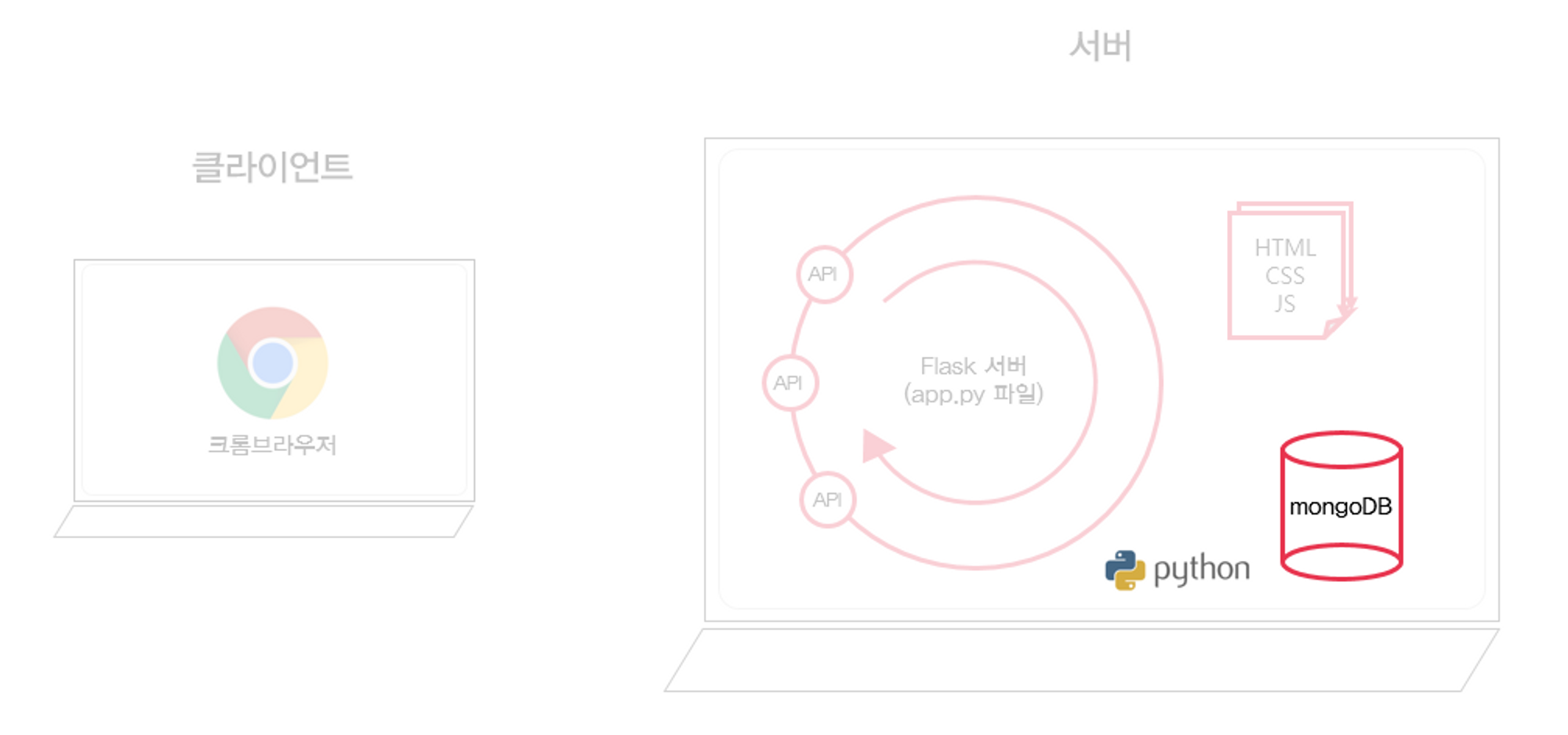
오늘은 파이썬을 이용해 정보를 크롤링해와서 몽고디비에 저장하는 걸 해보자
Python
기초 문법
python 문법은 이미 알고있음 나중에 따로 시리즈로 정리하자
가상환경
같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않기 위해, 파이썬 배포 패키지들을 설치하거나 업그레이드하는 것을 가능하게 하는 격리된 실행 환경
- 쉽게 말하자면 프로젝트별로 패키지를 관리할 수 있게 해주는 것
venv 생성
python -m venv venv (맥은 python3)
venv 활성화
프로젝트에 가상환경을 활성화한 후 필요한 패키지를 설치하면 된당
- 윈도우:
./venv/Scripts/activate - 맥:
source venv/bin/activate
venv 비활성화
deactivate
requests 패키지
설치
pip install requests
사용
import requests # requests 라이브러리 설치 필요
r = requests.get('url') # get방식으로 url에서 데이터를 가져옴
rjson = r.json() # 데이터를 json 형태로 변환
print(rjson)크롤링(혹은 스크래핑)
웹 페이지의 구조를 분석하고 파악하여 필요한 데이터를 추출해 내는 행위
필요한 모듈
bs4
기본 코드
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')bs4 사용법
- 개발자 도구를 통해 원하는 태그에서 copy selector 가져오기
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
# 태그안의 텍스트 가져오기
태그.text
# 태그안의 속성 가져오기
태그['속성]meta tag
해당 문서에 대한 정보인 메타데이터(metadata)를 정의할 때 사용
- 언제나
<head>요소 내부에 위치 - 크롤링시 문서 정보를 가져올때 주로 보게됨
<head>
<meta charset="UTF-8">
<meta name="keyword" content="HTML, meta, tag, element, reference">
<meta name="description" content="HTML meta tag page">
<meta name="author" content="TCPSchool">
<meta name="viewport" content="width=device-width, initial-scale=1.0"> <!-- 모든 장치에서 웹 사이트가 잘 보이도록 뷰포트(viewport)를 설정 -->
<title>HTML meta tag</title>
</head>Open Graph(og)
어떤 HTML 문서의 메타정보를 쉽게 표시하기 위해서 메타정보에 해당하는 제목, 설명, 문서의 타입, 대표 URL 등 다양한 요소들에 대해서 사람들이 통일해서 쓸 수 있도록 정의해놓은 프로토콜이며 페이스북에 의하여 기존의 다양한 메타 데이터 표기 방법을 참조하여 만들어졌다
- 예시: 카카오톡 링크 공유시 뜨는 사진, url, 설명글은 모두 og 태그에서 가져온 정보들!

<meta property="og:type" content="website">
<meta property="og:url" content="https://example.com/page.html">
<meta property="og:title" content="Content Title">
<meta property="og:image" content="https://example.com/image.jpg">
<meta property="og:description" content="Description Here">
<meta property="og:site_name" content="Site Name">
<meta property="og:locale" content="en_US">
<meta property="og:image:width" content="1200">
<meta property="og:image:height" content="630">mongoDB
DB 개괄
DB의 종류
RDBMS(SQL)
- 행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사
- 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이
- 틀이 정해져 있어 데이터를 조금 더 빠르게 가져올 수 있음
- 대신 정해진 틀로만 데이터를 저장 가능
- 대기업같이 비즈니스가 잘 안바뀌는 곳에서 자주 사용
예) MS-SQL, My-SQL 등
No-SQL(Not Only SQL)
- 딕셔너리 형태로 데이터를 저장
- 고로 데이터 하나 하나 마다 같은 값들을 가질 필요 없음
- 자유로운 형태의 데이터 적재에 유리
- 대신 일관성이 부족할 수 있음
예) MongoDB
클라우드
광대한 네트워크를 통하여 접근할 수 있는 가상화된 서버와 서버에서 작동하는 프로그램과 데이터베이스를 제공하는 IT 환경
- 요즘은 클라우드 서비스를 통해 DB를 사용하는 추세
pymongo
파이썬으로 mongoDB를 사용할 수 있게 해주는 라이브러리
import
from pymongo import MongoClientmongoDB 연결
client = MongoClient('여기에 URL 입력')url 가져오기
mongodb+srv://test:<password>@cluster0.d9duesr.mongodb.net/?retryWrites=true&w=majority
👆🏻요 아이를 가져올 것임
- mongoDB Atlas 접속
- database로 가서 cluster의 connect버튼 클릭
- Drivers 클릭
- connection string 복사
- 비밀번호 수정!!!!
db 생성
# 'DBName'라는 db 생성
db = client.DBName데이터 삽입
# 'users'라는 collection에 데이터 하나 삽입
db.users.insert_one({'name':'영희','age':30})데이터 조회
# 모든 데이터 뽑아보기( _id 값은 제외)
all_users = list(db.users.find({},{'_id':False}))
# 특정 데이터 뽑기
user = db.users.find_one({})데이터 수정
# 특정 데이터 수정
db.users.update_one({'name':'영수'},{'$set':{'age':19}})데이터 삭제
# 특정 데이터 삭제
db.users.delete_one({'name':'영수'})
공부한 내용은 바로바로 기록하자!