1. 개요
- 병렬 처리는 명령어를 병렬로 동시에 처리하는 것을 의미한다.
🎈 병렬처리 하는 방법
🚨 실행 할 수 있는 코어를 여러 개를 두는 방법
🚨 쓰레드를 여러 개 하는 방법
🚨 그리고 기본 명령어를 여러 개를 수행시키는 방법 - 최근 멀티코어 등이 더 중요해진 이유는 저전력-그린 IT와 발열문제 해결을 위함이다.
- 상대적으로 낮은 hz의 CPU Core 다수를 이용하므로 Throughput을 증가시키고 발열을 줄이는 개념이다.
- 병렬 처리에는 파이프라인, 슈퍼스칼라 등의 명령어 전달 방식 차이가 있고 병렬 컴퓨팅 방식으로 SMP, MMP, LCMP 등이 있다.
2. 기본 명령어 수행과정에서의 한계
-
CPU가 하나의 명령(Operation)을 처리하는 과정은 다음과 같다.

1) Fetch Instruction : 메모리에서 명령을 가져온다 2) Decode Instruction : 명령을 해석한다 3) Execute Instruction : 명령을 수행한다 4) Write Back : 수행한 결과를 기록한다 -
이 과정에서 각각 하나의 클럭을 소비하므로 하나의 명령을 수행 하는 데는 4Clock이 필요하다.
-
하나의 명령을 처리하는 데는 다음과 같이 계산할 수 있다.
-
단위 시간에 하나의 명령만 처리할 수 있다. 즉, 읽기(FI)에서 읽어온 명령을 해석(DI)단계로 넘겨주면 FI를 처리하는 유닛은 DI, EI, WB를 진행하는 동안 놀게 된다!!
3. 기본 명령어 한계 극복 파이프라인
-
기본적인 구조에서 비효율적인 부분을 극복하기 위한 한가지 방법을 제시한다.
-
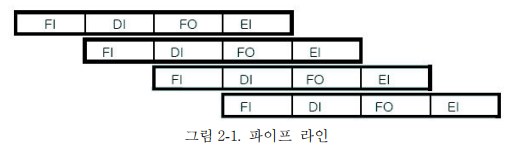
한 명령어를 처리하는 기본 유닛들의 효율성을 높이는 방법으로 하나의 클럭에 유닛의 동작을 중첩시키는 기술로써 아래의 그림과 같이 표현된다.
-
이렇게 한 명령의 처리 시간 동안에 다른 명령들을 중첩시켜서 수행하는 것을 파이프 라이닝이라고 한다.
-
아래는 파이프 라이닝의 성능을 높이는 방법을 정리한 것이다.
특징 설명 분기 예측(Branch Prediction) 프로그램 실행 도중 "GoTo"와 같은 분기 명령이 발생할 경우 메모리 상이 분기할 곳을 추측하는 기능 추측 실행(Speculative Execution) 메모리 상의 분기된 곳으로 직접 이동하지 않고, 그곳에 있을 것을 예측하여 처리하고 계속 다른 명령을 실행하는 기능 다중 명령 스케쥴링 다수개의 명령어 수행 시 사전예약에 의해 충돌을 회피하여 실행하는 기능
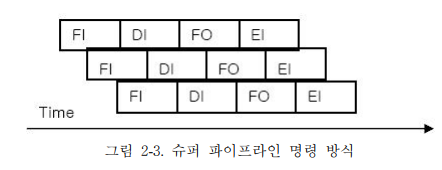
4. 슈퍼파이프라인
- Clock Cycle 축소를 통한 효율화한다.
- Pipeline의 단계를 세분화하여 Clock Cycle을 줄이는 방식으로 효과적인 병렬처리를 위해 몇 가지 동작을 명령어 수행과정에서 각 단계를 엇갈리게 중첩하는 기술이다.
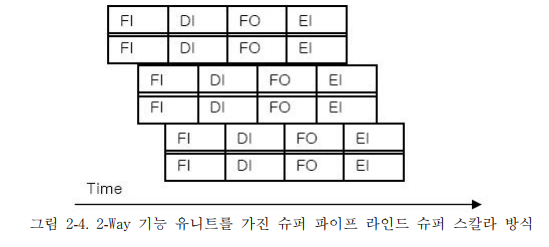
5. 슈퍼파이프라인드 슈퍼스칼라
- 슈퍼스칼라 + 슈퍼파이프라인이다.
- 이 방식은 슈퍼 스칼라를 통해서 여러 개를 중첩하고 Clock Cycle 내에 명령어를 한 개 이상 처리함으로써 슈퍼파이프라인의 효율성을 동시에 갖는 방식이다.
6. 분산 실행을 통한 효율화 VLIW(Very Long Instruction Word)
-
동시에 수행될 수 있는 명령어들을 컴파일 수준에서 추출하여 하나의 명령어로 압축하여 실행은 여러 개의 기능유니트(ALU)에 의해 분산되어 실행하는 방식이다.
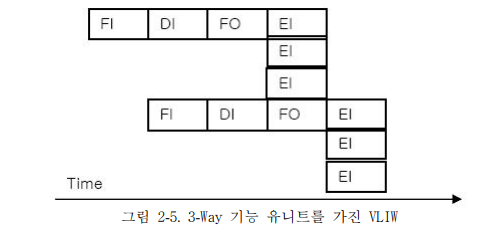
-
VLIW 방식은 컴파일러가 동시실행 가능 명령어들을 검출해 하나의 명령어로 압축하여 동시수행한다.
-
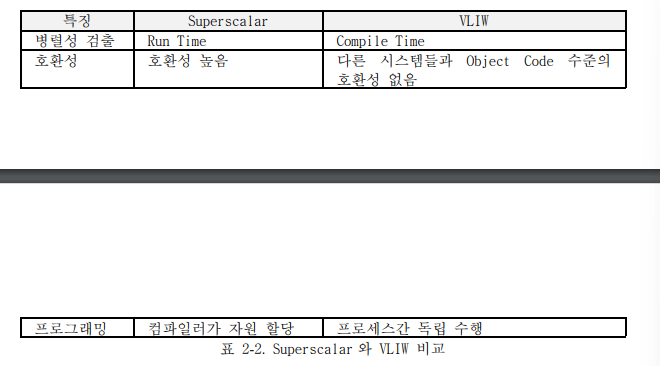
일정 크기의 VLIW명령어로 압축되므로 기존 H/W, S/W와의 호환성 결여 발생 가능하다. 예측이 상대적으로 쉬운 과학 계산 분야, 3차원 그래픽 처리, 멀티미디어 가속 등의 단순 자료의 반복처리에 활용된다. VLIW 프로세서는 덜 복잡하고 더 작고 높은 클럭 속도를 낸다. VLIW 특징과 Superscalar의 비교는 아래와 같다.
7. 파이프라이닝 기법의 문제점과 보완책
-
Pipelining 기법의 문제점은 병렬수행의 동작이 서로 독립적이어야 한다는 점이다.
-
분기나 점프 명령어의 오동작 우려가 있고, 명령어 수행결과가 다음 명령어에 영향을 미칠 시 처리가 어렵다.
-
이러한 문제점에 대해서 아래와 같은 보완책이 있다.
보완책 내용 하드웨어적 중복 프로그램 흐름상의 명령어를 모두 인출 분기 목적지 선인출 조건분기 명령어와 분기 목적지 명령어를 모두 인출 분기 예측 분기 발생빈도의 확률적인 추측에 의해 명령어 인출 지연 분기 분기 명령어를 지연시키는 방법 Cache 분리 메모리 참조시간을 줄이기 위해 명령어 Cache와 Data Cache 분리
000000 여기까지 정리함
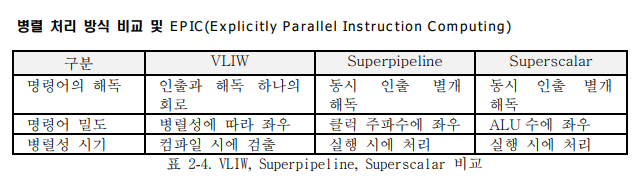
-
EPIC는 컴파일러가 소스 코드로부터 명시적 병렬성을 찾아 병렬처리가 가능하도록 기계어 코드 생성 병렬 수행된다.
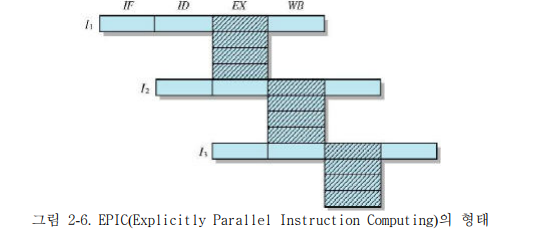
-
대용량 처리 및 분산 컴퓨팅 환경이 계속해서 필요함에 따라서 적용이 되고 있고, 범용성 응용분야에서의 연구가 되고 있다. 과학 계산의 분야에서는 좋은 성능을 발휘한다.
-
병렬컴퓨터 기술의 핵심으로 프로세스 내 Pipeline 기능 세분화 다수의 동기화된 프로세서(Array Processor)이용 기술은 계속 발전 될 것이다.
8. 하이퍼 쓰레딩의 개념
- 하이퍼 쓰레딩(Hyper threading)은 하나의 CPU 내에서 두 개의 CPU 처럼 처리하는 가상 기술이다.
- Hyper Threading은 그래픽 및 동영상 편집의 작업 시 타 작업의 병행처리 욕구가 증대되는 상황에 고가의 Core를 추가하는 방법이 아닌 적은 비용으로 유사한 효과를 이루기 위한 방법 중 하나이다.
- Clock만 높이는 것이 아니라 CPU의 유휴자원을 최대한 활용하는 방식으로 인텔에서 발표한 것이다.
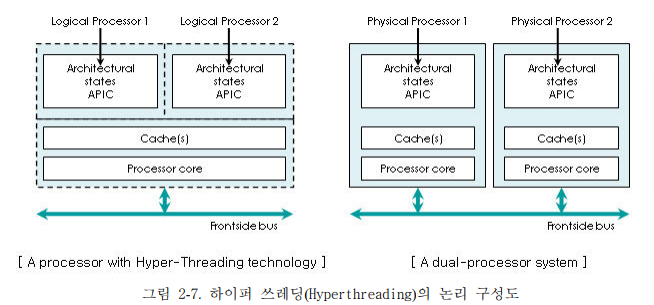
9. 하이퍼 쓰레딩(Hyper Threading)의 특징
- 프로세스의 논리적인 분할을 통해 자원공유의 부하를 감소시키고 병렬 처리 및 다중 프로세싱을 통해서 CPU 능력이 향상된다. 프로세스 동기 제어 시 발생하는 Mutex 및 Context Switching 부하는 감소된다.
- Hyper Threading의 문제점은 발열량 및 전력소모가 증가되고 Dual Core에 이르는 수준은 아니나 소프트웨어 라이센스에 대한 이의 제기가 소규모 발생 일부 응용 영역(그래픽, 자료복사)에 국한된 성능 향상을 보인다.
- Hyper Threading 비교 및 향후 전망은 사실상 이 기술을 발표한 인텔에서도 이제는 듀얼 코어나 코어 2 듀오라는 방식의 실제 물리적 이중 또는 사중 코어로 발전하고 있어서 실용성 면에서는 큰 의미는 없다. CPU의 발전 과정상에서 기억해야 할 정도이다.
10. 병렬 컴퓨팅
- 다수 Processor들이 다수 프로그램 또는 단일 프로그램의 분할된 부분들을 분담하여 동시에 처리하는 컴퓨터를 말하며 대용량 고사양의 컴퓨터 프로세싱의 요구에 따라서 발전되어온 컴퓨팅 방식이다.
- 병렬 컴퓨터용으로 작성된 프로그램은 작업을 동시에 처리하는 특수의 처리 장치에 골고루 분담시킴으로써 처리 속도를 향상시키고 단위 시간당 작업량을 증가시킬 수 있다.
11. 컴퓨터 분류별 특징
- 기본적인 명령 처리에서 병렬 처리까지 컴퓨터의 처리 형태에 따른 기준은 아래와 같이 나눌 수 있다.

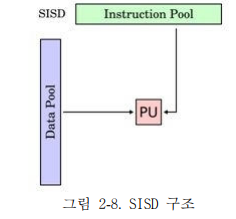
1) SISD(Single Instruction Single Data)
- 고전의 폰노이만 방식에서 구조로써 한번에 한 개씩 명령어와 데이터를 순차처리한다.
- 실행과정을 여러 단계로 나누어 중첩시켜서 실행속도를 높이는 Pipelining 기법을 사용한다.
- 파이프라인, 슈퍼스칼라 등의 명령어의 병렬처리를 통해서 효율성을 높인다.
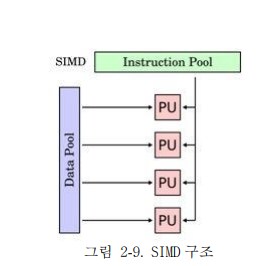
2) SIMD(Single Instruction Multi Data)
- 단일 CPU와 다중 ALU를 갖춘 구조이다. 다수의 ALU로 구성되고 이들은 모두 하나의 제어장치가 통제되고 명령어 실행과정에서 서로 다른 Data를 사용한다. 벡터 컴퓨터 어레이 컴퓨터라고도 한다.
3) MISD(Multiple Instruction stream Single Data Stream)
- 여러 개의 처리기가 하나의 데이터 스트림에 대하여 서로 다른 명령어를 실행하는 구조인데, 현실적으로 구현되기 어렵고 적용사례도 없는 구조이다.
4) MIMD(Multiple Instruction Multiple Data)
- 다중 프로세서로 구성, 서로 다른 명령어와 데이터를 처리한다. 프로세서간 연결 방법에 따라 SMP, MPP, LCMP 등이 있다. 약결합 방식과 강 결합 방식으로 나뉜다.
- 약 결합 방식은 각각의 처리기가 각각의 local memory를 가진 독립적인 구조이다. 처리기 사이의 데이터 교환이 많지 않을 경우에 사용한다. 강 결합 방식은 각각의 처리기가 하나의 공유 메모리를 사용하는 구조로써 처리기 사이의 데이터 교환이 빈번하게 발생할 때 유리한 구조이다.
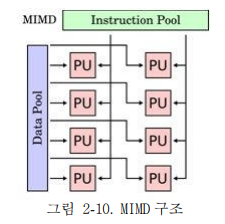
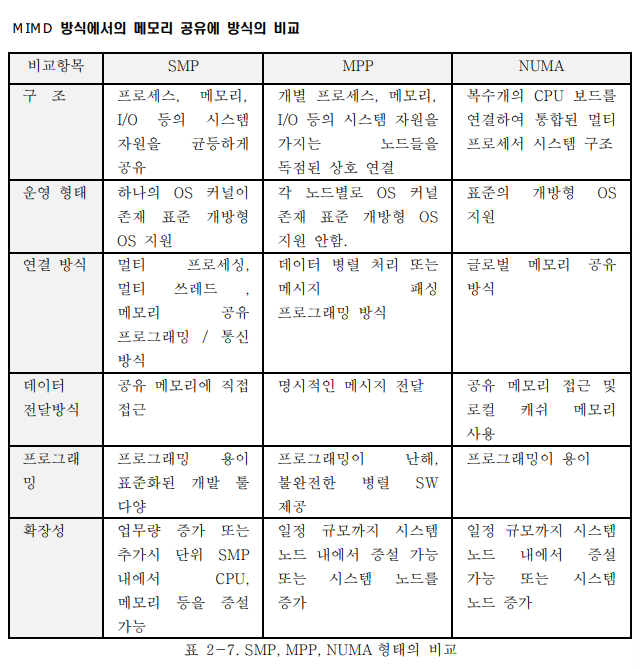
12. MIMD 방식의 종류
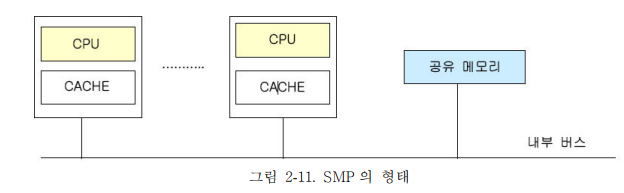
1) SMP(Symmetric Multi Processing)
- SMP는 단일 처리기 시스템에서 나타나는 성능의 한계를 극복하기 위해 여러 개의 처리기를 공유 버스나 상호연결망에 연결시켜 놓은 시스템이라고 할 수 있다. 단일 OS와 단일 Memory로 구성된 완전 공유 구조이다. 모든 CPU가 모든 시스템 자원을 공유하며, CPU 간 데이터 정합성 작업이 필요하다.
- 각 CPU가 데이터를 공유하므로 대용량 OLTP 환경에 적합하다.
- SMP 시스템의 최대 장점은 프로그래밍 인터페이스가 기존 단일처리기 시스템과
동일하다는 점이다. 즉, SMP 시스템의 구조가 프로그래머에게는 투명하기 때문에
프로그램을 하는데 별도의 노력을 필요로 하지 않는다. - SMP 시스템은 캐쉬에 의한 버스 트래픽 증가 등의 이유로 공유 버스에 많은 부하가
발생하기 때문에 확장성이 큰 단점이다. 따라서 업계와 학계에서는 SMP 시스템의 확장성을
향상시키기 위해 다음과 같은 기법들이 연구 또는 구현되고 있다.
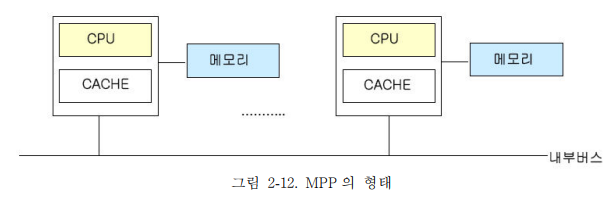
2) MPP(Massively Parallel Processing)
- MPP 는 노드별 각각의 CPU 와 전용 메모리로 구성되어 메모리를 공유하지 않는 구조이다.
다수의 CPU 들이 서로 독립적으로 작동하여 최고의 성능을 발휘하도록 하는 구성된
방식으로 프로세스와 메모리, 운영체제로 구성된 각각의 노드로 작동하여 시스템 확장
시에도 성능의 감소가 없다. - 주로 과학계산용 Application 이나 노드간 통신이 적은 분야에 사용한다. 확장성이 뛰어나고,
- 대용량의 DB 을 지원, 개발비용이 저렴하며, 많은 수의 프로세서 연결이 가능한 장점이 있다.
프로그램이 복잡하여 Application 개발, 이식 및 운용이 어렵고, 적용되는 시스템
소프트웨어가 많지 않은 단점이 있다.
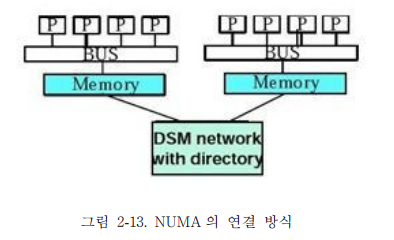
3) NUMA
NUMA 는 멀티 프로세싱 시스템에서 지역적으로는 메모리를 공유하며, 성능을 향상시키고,
시스템 확장성이 있도록 마이크로프로세서 클러스터를 구성하기 위한 방법이다. NUMA 는
SMP 시스템에서 사용된다.
SMP 시스템은 서로 밀접하게 결합되어, 모든 것을 공유하는 시스템으로서, 다중
프로세서들이 하나의 단일 운영체계 하에서 공통의 버스를 통해 각자의 메모리를 액세스한다.
SMP 의 한계는 마이크로프로세서가 추가됨에 따라, 공유 버스나 데이터 경로가 과중한
부하가 생기게 되어, 성능에 병목현상이 일어나는데 있다. NUMA 는 몇 개의
마이크로프로세서들 간에 중간 단계의 공유메모리를 추가함으로써, 모든 데이터 액세스가 주
버스 상에서 움직이지 않아도 되도록 한다.
NUMA 시스템은 MPP 의 Node 와 유사한 하나 이상의 Quad 로 구성된다. CC(Cache
Coherent) – NUMA : 하나의 운영체제가 탑재되는 단일 노드 개념으로 캐시 Coherence 를
하드웨어적으로 구현하여 메모리 접근 지연 시간을 단축시킬 수 있다. 분산된 메모리들이
결합하여 하나의 메모리를 구성하므로 데이터나 페이지의 복사본이 메모리들 사이에
존재하지 않는 구조이다
4) RMC(Reflective Memory Cluster)
RMC 방식은 Quad 마다 하나의 운영체제 복사본을 갖는 다수 Quad 로 구성된다. Quad
사이에 데이터의 복사나 이동 메커니즘이 있으며, Lock Traffic 연결망을 갖는 클러스터
시스템, 메모리 이동은 소프트웨어적이 일관성 기법을 이용하며, 운영체제의 간섭없이
데이터가 전송되어 메모리 접근 시간이 빠른다.
5) COMA(Cache-Only Memory Architecture)
CC-NUMA 구조처럼 단일 노드 개념에 하드웨어적 캐시 일치성을 갖지만 각 보드 내에
메모리를 갖지 않고 단지 큰 캐시로 구성된다. 장점은 확장성이 뛰어나고 1 개 이상의
Quad 로 구성된 NUMA 시스템을 대상으로 Clustering 기법을 적용하여 수평적으로 확장
가능하다. 지원되는 Application 및 시스템 소프트웨어가 적다는 단점을 가지고 있다.