지도학습과 비지도 학습에 따른 Basic API
- estimator : 지정한 모델을 의미
- estimator.fit : 모델을 학습
- estimator.predict를 할 수 있는 것은 분류, 회귀, 군집화(clustering)가 있음
- estimator.transform을 할 수 있는 것은 전처리, 차원축소, feature selection, feature extraction이 있음
최적의 모델학습을 위한 파라미터 튜닝 방법
Grid-search
- 파라미터 값을 순차적으로 입력하여 가장 높은 성능을 보이는 파라미터를 찾는 방법
- 어떤 조합이 모델에 가장 적합한지 판단
- 검증하고자 하는 하이퍼 파라미터의 수치를 정하고 그 조합을 모두 검증하는 방식
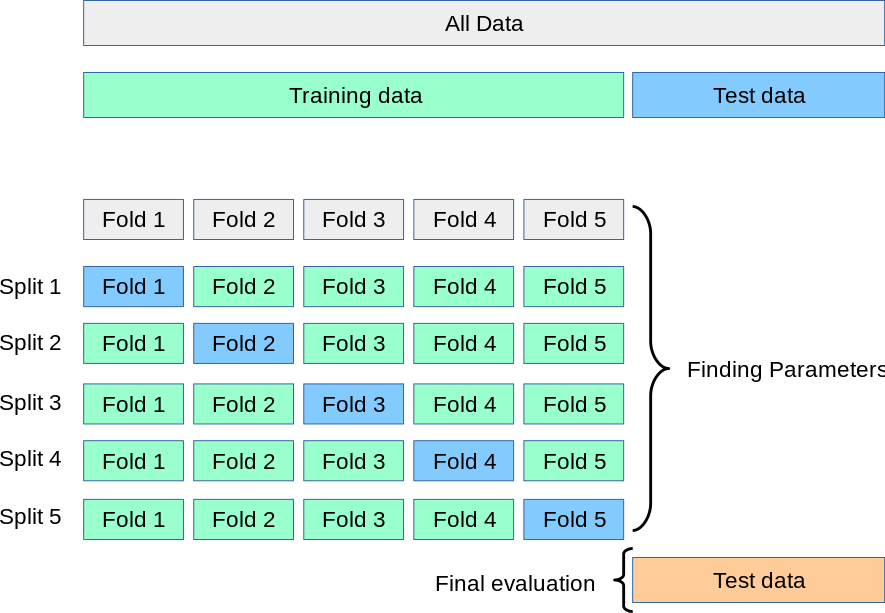
대표적인 방법! Cross-validation
- 어떤 파라미터가 최선의 모델을 만드는 지 알아내기 위한 Grid-search의 한 방법
- 모델이 얼마나 성능이 좋은지 검증하는 방식
Randomized search
- 랜덤서치는 그리드 서치에 비해 더 쉽고 넓게 범위를 찾는다.
- 그러므로, grid-search 보다 우선적으로 하는 것이 좋다
- 검증하고자 하는 하이퍼 파라미터들의 값 범위를 지정하면 무작위로 값을 지정하여 조합을 모두 검증!
(https://cms-ml.github.io/documentation/optimization/model_optimization.html)
(https://scikit-learn.org/stable/modules/cross_validation.html)
- 모델 학습 검증을 위해 사용
- 효과적인 학습을 위해 검증 데이터(validation data)를 사용
- 여러 검증 데이터를 사용하여 fit을 여러번하여 각각의 fold에 있는 점수들의 평균을 통해 가장 좋은 점수를 가진 모델과 파라미터를 찾는 방식
- 각 fold에서 한 set만 테스트용으로 사용하고 나머지 set은 학습용으로 사용
텍스트 데이터 분석
Bag of word representations
- 문장을 벡터화(토큰화)
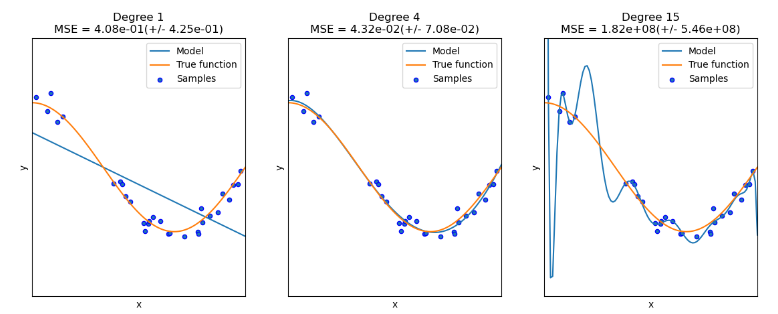
모델학습에 따른 overfiting & underfiting
(https://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html)
- overfiting : 훈련 데이터셋에 익숙해져 있으나, 새로운 데이터에는 적용하지 못하는 현상
- underfiting : 훈련 데이터 학습이 충분하지 않음
- 최적의 모델 학습은 두 개념 사이에서 최적의 선(sweet spot)을 찾는 것
모델에 따른 과적합과 과소적합
- decision tree : depth가 깊어지면 과적합문제가 발생할 수 있음 . 너무 낮을 경우 과소적합 발생 우려
- random forest : decision tree를 여러개를 이용하여 모델 성능을 향상하는 방법
참고
- scikit - learn
- grid search
- randomized search

공부에는 끝이 없다