The Loss Function
- 손실함수는 대상의 실제값과 모델이 예측하는 값 사이의 차이를 측정 (실제값과 예측값의 차이)
- 손실(loss)를 최소화하여 모델을 효과적으로 학습
대표적인 손실 함수
- 회귀 분석
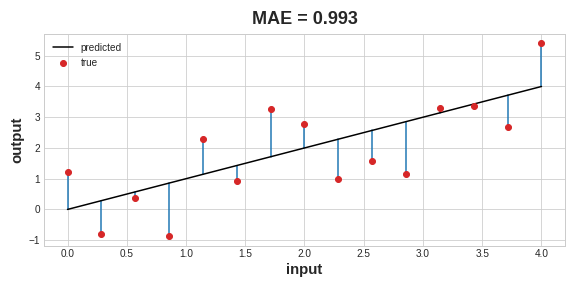
- 회귀 분석의 대표적인 손실함수는 평균 절대 오차또는 MAE
- MAE는 abs(true- pred)로 구함
- 전체 MAE는 모든 데이터에 대한 절대적인 차이의 평균
- 평균 제곱 오차 (MSE) 또는 Huber loss (Keras에서 사용가능)
- 분류분석
- 교차 엔트로피 손실 함수(Cross - Entropy Loss)
The Optimizer
Stochastic Gradient Descent
📌 Gradient
- 가중치가 어느 방향으로 가야하는지 알려주는 백터(vector)
- loss가 변하도록 가중치를 변경하는 법을 알려줌.
- gradient를 최소화해야 함으로써 loss를 최소화해야 함.
- 미니배치는 데이터셋에서 무작위로 추출된 샘플이기 때문에 Stochastic Gradient Descent에서 Stochastic(우연하게 결정됨)이라는 단어를 사용한다
- 가중치를 조절하여 손실을 최소화하는 알고리즘
- 네트워크를 단계적으로 훈련하는 반복 알고리즘
- 데이터 샘플링 및 네트워크를 통한 예측 (예측값 산출)
- 예측값과 실제값 사이의 손실을 측정
- 손실이 작은 것으로 가중치를 조정
- 손실이 가장 작을 때 까지 작업 반복
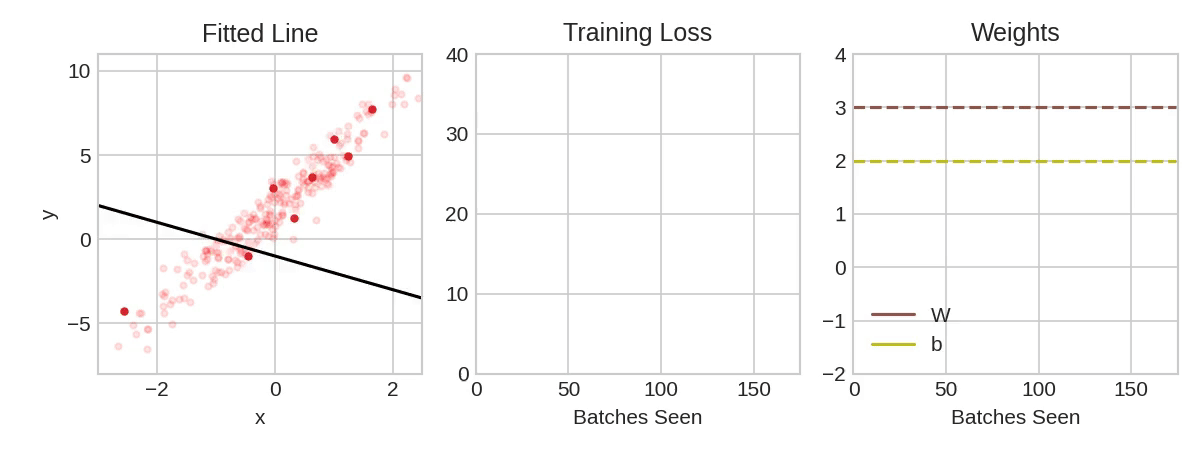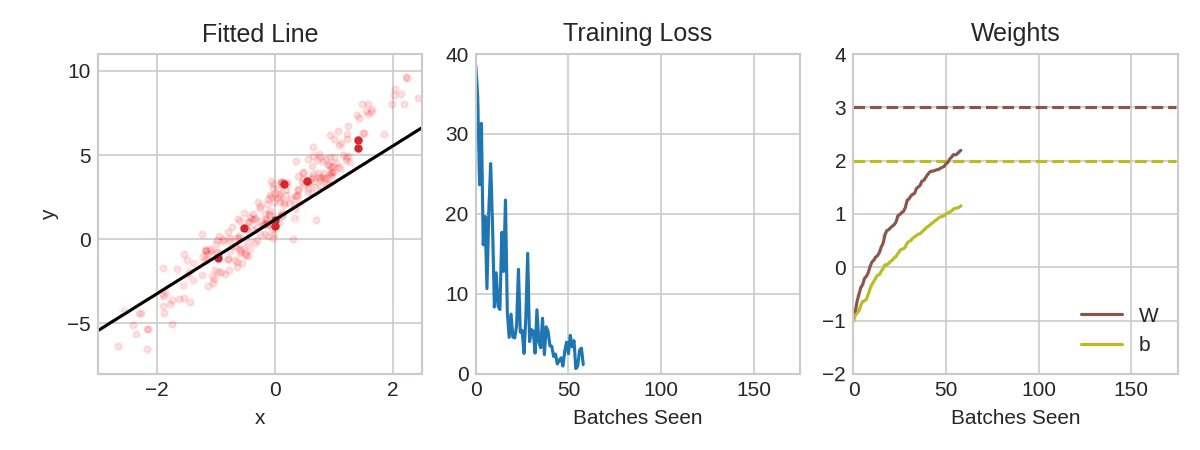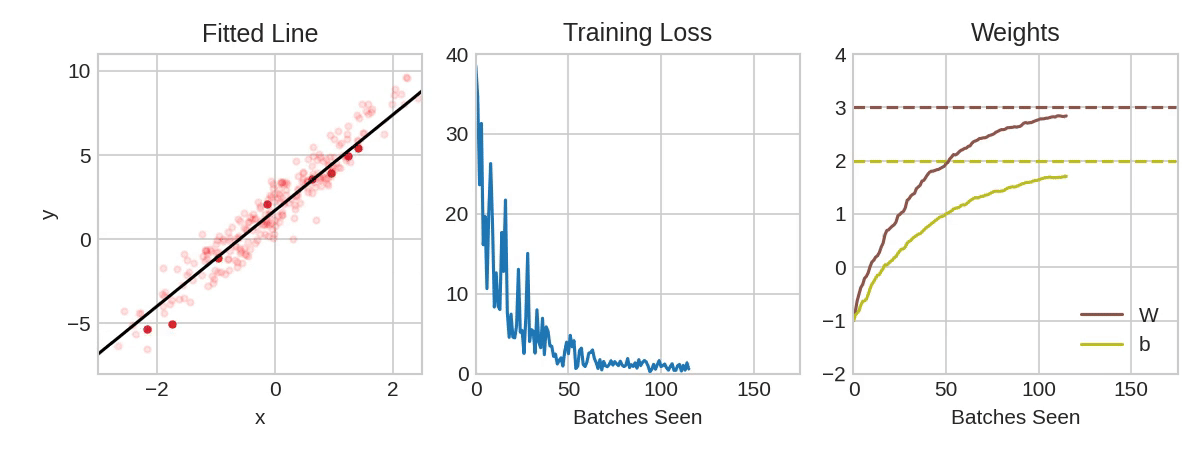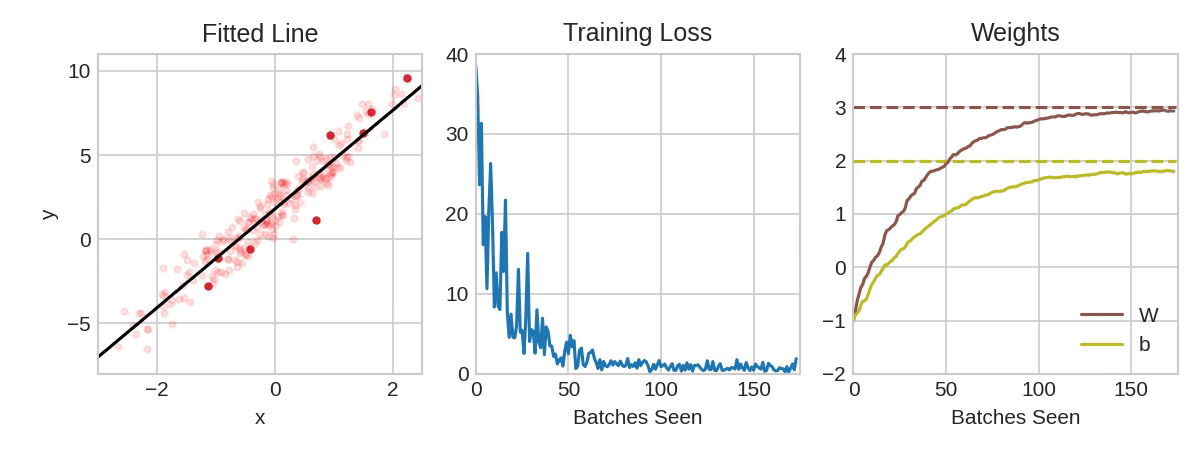
확률 경사 하강법 신경망 훈련
위 애니메이션에서는 실제값과 훈련값 사이의 차이가 가장 작아지는 조건을 찾는 과정을 표현
- 훈련 데이터의 전체 round를 에포크(evoke)라고 함. 에포크의 수는 네트워크 훈련 횟수
- 반복의 훈련 데이터 샘플은 미니배치(mini-batch)라고 함
Learning Rate and Batch Size
- SGD(Stochastic Gradient Descent)에서 각 배치에 대한 가중치 업데이트가 전체적인 이동이 아닌 작은 방향으로만 이루어짐
- 작은 이동의 크기는 학습률(learning rate)에 의해 결정
- 학습률이 작을수록 네트워크는 가중치가 최적 값으로 수렴하기까지 더 많은 미니배치를 볼 필요가 있음
최적화 알고리즘
- 학습률과 미니배치의 크기는 SGD 훈련에 큰 영향을 미치는 것은 매개변수
- 매개변수 간의 최적의 관계를 구하기 위하여 최적화 알고리즘을 사용하기 때문에 광범위한 파라미터 검색을 할 필요 없음
- 대표적인 최적화 알고리즘으로는 adam이 있음
Adding the Loss and Optimizer
- model 생성 후 , loss와 최적화를 적용하는 코드
compile과정에서 파라미터로 설정됨compile이후에fit과 같은 함수를 통해 모델을 학습한다.
model.compile(
optimizer="adam",
loss="mae",
)
참고

공부에는 끝이 없다