Servlet, JSP의 등장 이후 시스템 규모가 점점 커져갔다. 대량의 트래픽을 감당하기 위해 서버를 나누고, 여러 대의 서버와 DB가 데이터를 주고 받다보니 시스템 구조의 복잡성이 증가했다.
한 가지 요청을 위해 여러 서버나 DB가 개입해야 한다든지, 여러 db 요청이 오가야 한다든지, 요청 중 다른 요청을 동시에 처리해야 한다든지 등의 복잡한 기술이 요구되기 시작했다.
여러 시스템이 운용되다보니, 데이터가 오가는 데에 있어 보안이 취약해지는 부분이 생기기도 했다.
하지만 기업 내 한정된 개발자 풀 내에서 비즈니스 로직 뿐만 아니라 위의 문제와 요구를 해결하기는 쉽지 않았다.
이러한 문제를 해결하고자 나온 기술이 바로 이번 포스팅에 소개할 EJB이다.
EJB
EJB의 사상은 위에 제기된 여러 문제, 즉 로우 레벨의 기술에 대한 문제를 신경쓸 필요 없이 비즈니스 로직에만 집중할 수 있게 하는 데에 있다.
EJB는 독립적으로 개발한 컴포넌트를 배포하고, 서로 연동해 사용하는 컴포넌트 기반의 개발 모델을 제시했다. 이 컴포넌트를 기존 Java Beans(이하 빈)와 다른 Enterprise Java Beans, 줄여서 EJB라고 하는 것이다.
여기서 기존 빈과 EJB는 어떻게 다른가?
먼저 기존 빈은 무엇일까?
Java Beans
사실 별거 없고, 그냥 규칙을 따르는 클래스다.
주로 JSP에서 시각적 요소를 제어하는 객체의 형태를 띄며, 개발을 하고 있는 나에게 비슷한 형태라고 친다면 DTO와 VO와 비슷한 형태를 띄고 있다.
이 규칙은 다음과 같다.
- 직렬화된 클래스
- 내부 변수, 즉 property는 무조건 private로 되어 있어야한다.
- private된 property에 접근하기 위한 getter, setter 메서드를 가져야 한다.
- 3번에 정리한 메서드는 public이어야 한다.
이러한 빈의 형태를 예로 들어보면 다음과 같다.
//직렬화를 위해 다른 서버에도 동일한 class가 있어야 한다.
public class JavaBean {
private String prop; // property private
public String getProp() { // getter public
return Prop;
}
public void setProp(String prop) { // setter public
this.prop = prop;
}
}EJB vs Java Beans
그럼 EJB와의 차이점은 무엇일까?
물론 형태가 차이난다기보다, 목적과 동작이 다르다.
뭔가 정리가 잘 되어 있는 표길래 가져왔는데, 하나하나 뜯어보며 해석해보자.
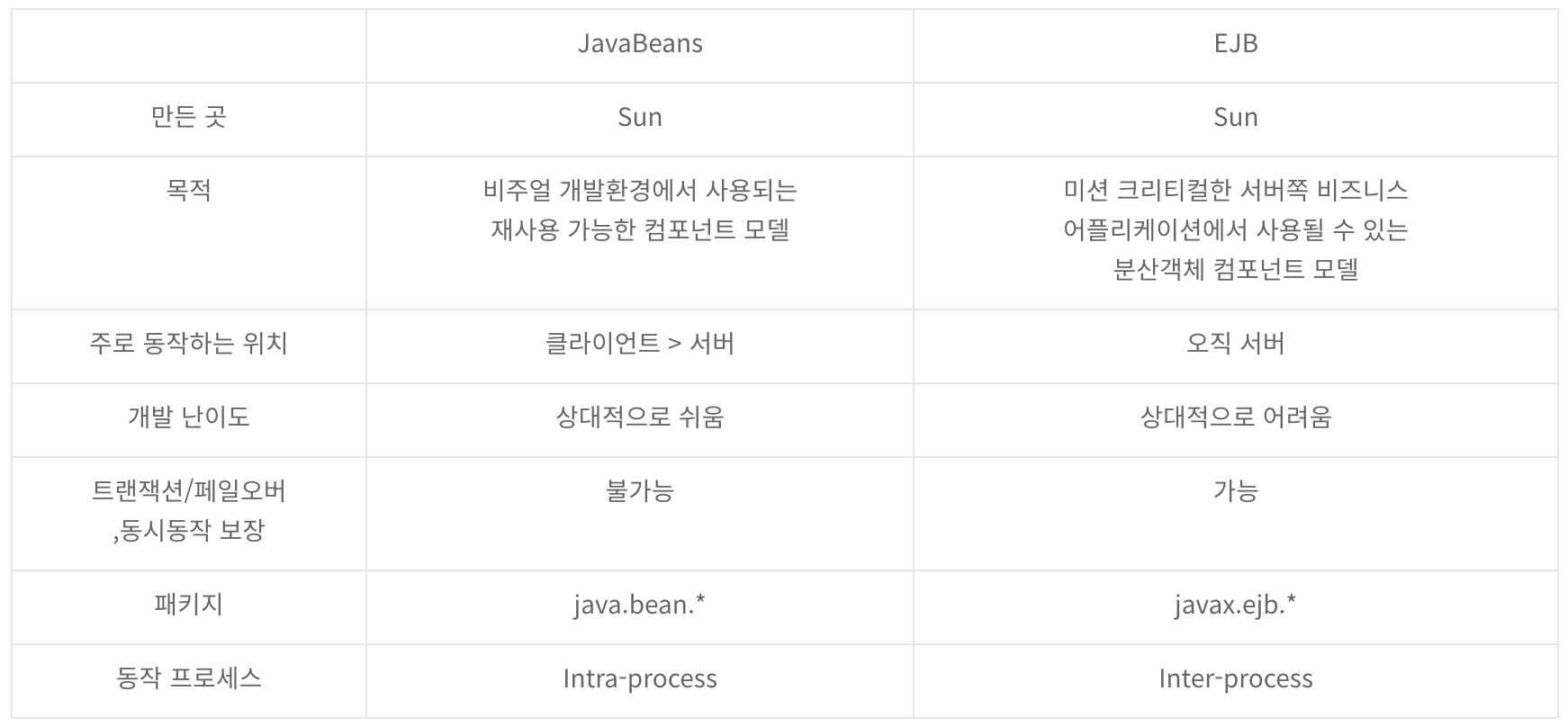
먼저 목적.
빈은 비주얼 개발 환경에서, 즉 GUI나 JSP 개발에서 사용되는 객체 모델이라고 할 수 있다.
그리고 EJB는 서버 비즈니스 로직에서 활용되는 분산 객체 컴포넌트이다.
그러다보니, 동작하는 위치의 비중이 달라진다.
개발 난이도는 빈은 객체 컴포넌트를 만드는 것이기에 비교적 쉽다.
EJB는 비교적 어려운데, 복잡한 설정 파일을 건드릴 일이 잦다.
트랜잭션, 페일오버에 대해선 말할 것도 없다. EJB가 이거 안정적으로 하려고 나온 애니까,,
나온 김에, 두 가지 EJB의 강력한 기능에 대해 짚어보자.
트랜잭션
사전적 정의로, 쪼갤 수 없는 업무 처리의 최소 단위라고 한다.
개발 중 마주칠 수 있는 예로 들어본다면, 내가 어느 게시물에 접속했을 때 조회 수가 오르게 된다. 이와 함께 오른 조회 수를 가져와 화면에서 볼 수 있어야 한다.
결국 서버에서 처리해야 하는 sql쿼리는 두 가지이다.
- 조회 수 올리기(insert)
- 조회 수 가져오기(select)
2번 동작을 하지 않고 임의로 +1한 값을 가져오는 것도 분명 가능은 하겠지만, 만약 1번 동작이 제대로 기능하지 않은 상태에서 2번 동작만 실행되거나 임의로 1을 더한 값을 가져온다면, 데이터베이스에는 내가 접속한 조회수가 적용되지 않아 제대로 쌓이지 않은 조회수를 제공하게 될 것이다.
또한 1번 동작 후 서버 문제로 인해 접속에 어려움을 겪는 등 2번 동작이 원활히 이뤄지지 않는 상황이 발생할 경우, 내가 조회를 하지 못한 게시글의 조회 수가 올라가는 것은 정확하지 않은 정보이다.
결국 내가 명령한 1, 2번 동작은 두 가지 모두 적용되거나, 모두 적용되지 않아야 한다. 이를 보장하는 것을 트랜잭션이라고 한다.
페일오버
페일오버의 정의는 컴퓨터 서버, 시스템, 네트워크 등에서 이상이 생겼을 때 예비 시스템으로 자동전환되는 기능이다.
EJB는 여러 컨테이너에 클러스터링(하나의 데이터를 분산시키는 기능)을 통해 페일오버와 load balancing(하나의 노드가 처리할 일을 여러 노드로 나누어 최적의 퍼포먼스를 내게 하는 것)을 보장한다.
다시 EJB를 소개하는 맥락으로 돌아와서, 검색을 하다보면 나오는 특징이 있다.
- 인스턴스 풀링
- 트랜잭션
- 의존성 관리
- 컴포넌트 생성 및 소멸, 보안, Threading 등의 서비스를 제공하는 컨테이너
인스턴스 풀링은 객체를 미리 생성해두고, 메모리에 저장해 사용 준비 상태를 유지하는 것이다. 트래픽이 많이 몰릴 때 객체를 생성하는 것보다, 서버 시작과 동시에 생성을 하는 것이 서버 안정성에 더 좋기 때문이다.
또한 안정적이고 신뢰성 있는 분산 시스템을 위해 트랜잭션 기능을 보장한다. 이는 EJB 컨테이너가 작동하는 모든 메서드에 대해 적용한다.
의존성 관리는 EJB의 상태를 사용 여부에 따라 자동으로 활성화를 관리한다.
그리고 이러한 기능들을 자동으로 처리하는 EJB 컨테이너가 EJB 사양의 대표적 기능과 특징이라고 할 수 있다.
그래서 결론적으로,
EJB는 서버 사이드에서 비즈니스 로직을 처리하는 분산형 컴포넌트이다.
규모가 큰 시스템의 로우 레벨 기술에 대한 처리를 위해 만들어졌으며, 대표적으로 트랜잭션, 보안과 같은 분산 시스템에서의 연결 및 데이터 무결성 관리를 처리하는 사양이다.
EJB 자체가 정리하기에 꽤나 큰 사양이라, 두 개의 포스팅으로 나눈다. 다음 포스팅에는 EJB의 컨테이너, EJB의 종류, 동작 원리에 대해 다뤄보겠다.
