Introduction
AI가 발전하면서 자연의 이미지를 예술적으로 변환시키는 기술이 생겨나고 있는데(style transformer) 이런 이전의 기술들은 각 픽셀별 정보를 optimization/mapping하는 과정이다.
하지만 현실에서 화가들이 브러쉬로 한번에 한획씩 긋는 것 처럼 이 과정을 모방한다면 더욱 현실적인 그림이 탄생 할 것이다.
그렇다면 Sequence정보가 중요한데, texture가 풍부 할 수록 이과정은 정말 어려워 질 것이다. 이전의 연구들은 RNN,step-wise greedy search, RL등으로 이 문제를 해결하려고 했다.
이런 방법들은 다 각자의 단점이 존재한다!
이런 문제에 대해 이 논문은 sequence를 생성하는게 아니라 stroke set을 예측하는 문제로 바꾸려고 한다.
결과적으로 초기의 canvas(사용자 그림), 원래 이미지가 존재할 때 stroke set을 예측하여 canvas위에 rendering함으로써 (scale 다르게 k번 반복) canvas와 natural image의 차이를 최소화 하려한다.
하지만 이런 데이터를 얻는다는 것이 굉장히 힘들기 때문에 다음과 같은 self-training 방식을 채택한다.
1. random하게 선택된 stroke로 background를 만들어 canvas에 합친다.
2. random하게 선택된 stroke로 foreground를 만든 후에 canvas 위에 rendering한다.
Structure
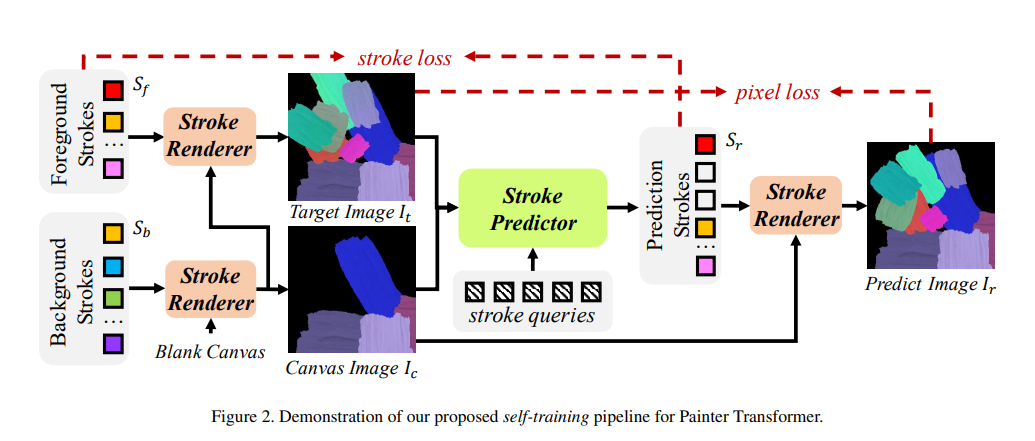
학습은 와 의 차이를 줄이도록 하습된다. 이 두 값을 기반으로 Stroke predictor가 Stroke set 을 만든다. 그 후에 Stroke Renderer가 의 각각의 원소에 대하여 canvas위에 stroke을 그린다. 위 과정을 식으로 나타내면
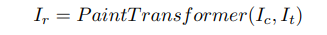
이 모델에서 stroke renderer은 학습가능한 파라미터를 가지지 않기 때문에 predictor만 학습시키면 되는데, 여기서 self-training을 사용한다.
각 iteration 마다
1. random sampling으로 background stroke set 와 foreground stroke set 를 생성한다.
2. stroke renderer를 사용하여 로 를 를 우에 rendering 하여 를 생성한다.
3. 해당 image를 가지고 pixel과 stroke level에서 loss를 구하여 optimization 한다
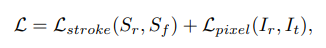
Stroke and Renderer
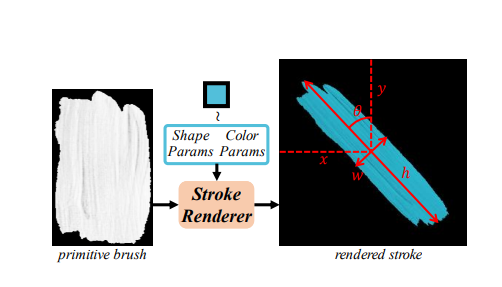
stroke는 기울어직 각도 , 색 정보 {r,g,b} 중심 좌표 정보{x,y} 로 총 8개의 parameter을 갖는다.
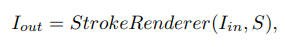
초기 stroke 정보(primitive brush)와 stroke parameter가 주어졌을 때 모양,위치,색등을 변경시킬 수 있다.
rendering과정은 다음과 같다.
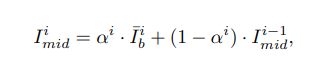
해석 : 는 i번 째 stroke의 binary 마스크로 i번 째 stroke에 대하여 모양을 따라가고 나머지 부분은 i-1번 째 까지의 canvas를 따르겠다.
Stroke Predictor
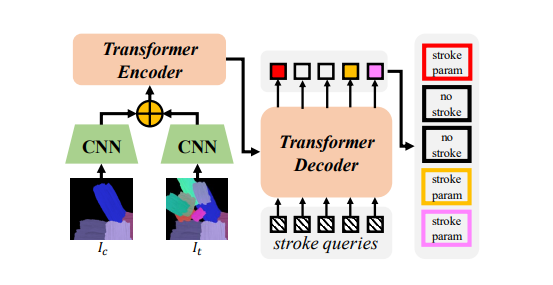
predictor은 imtermediate canvas와 target canvas의 difference를 줄이는 방식으로 진행된다. 해당 과정은 transformer(DETR)의 방식에서 영감을 얻는다.
1. 와 를 cnn을 통해 각각 feature extracting을 진행한다.
2. learnable position encoding 과 concat된 후에 flatten되어 encoder에 들어간다.
3. n개의 learnable stroke query를 사용하는 decoder를 거친 후 2개의 branch의 FC layer를 지난다.
결과적으로 Stroke parameter 와 각각의 stroke에 대한 confidence를 얻을 수 있다. 여기서 confidence에 대하여 임계값 이상인 값에 대하여 1,0 이진으로 나누는 neuron을 추가하였고, 이 과정은 미분이 불가능하기 때문에 sigmoid함수를 사용한다.
Loss Function
Pixel Loss:
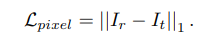
pixel 단위의 loss는 단순히 L1 loss를 사용한다
Stroke L1:
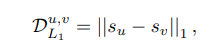
두 stroke의 parameter를 기준으로 L1 loss를 구한다. -> stroke의 scale이 무시된다.
Stroke distance:
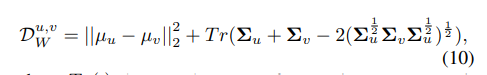
rotation stroke parameter을 (x,y)를 중심으로 하는 gaussian distribution을 따른다고 가정하였을 때 비교 대상인 두 strike u,v에 대하여 wessertein distance를 구한 값이다.
Stroke bce:
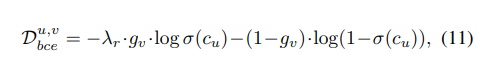
u = predict v = ground truth
if :
else :
1.high confidence with u : loss high
2.low confidence with v: loss low
1.high confidence with u : loss low
2.low confidence with v: loss high
result: ground truth에 따른 가중치값.
Stroke loss:
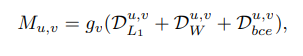
Inference

1.real world image를 K개의 scailing을 진행한다.
2.이미지를 P by P로 잘라서 predictor를 거친다
3.결과를 합친다.
