Consistency training
Unlabeled data의 consistency training에서 중요한점은 데이터의 작은 변화에도 모델이 불변적이어야 한다는 것이다. 이런 특성을 만족시키기 위해서 주로 hard augmentation을 통해 얻어진 이미지의 difference를 줄이는 작업을 한다. 이 논문은 굉장히 다양하게 mix된 이미지를 통해서 해당 조건을 만족시키려 한다.
Method
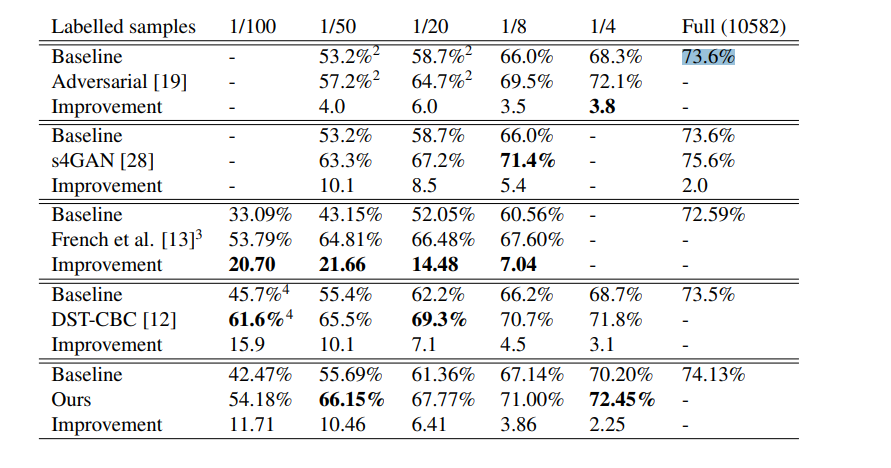
2개의 input image를 활용하여 1개의 output image와 label을 만들어낸다.
그 과정에서 하나의 이미지에서 절반의 클래스를 복사하여 다른 이미지에 붙인다.(copy and paste)
detail한 과정은
1. 선택된 두 unlabeled data를 nueral network의 input으로 하여 결과값을 얻는다.
2. 하나의 이미지를 선택하여 class별 그룹을 생성한다.
3. 랜덤하게 존재하는 class그룹의 절반을 선택한다.
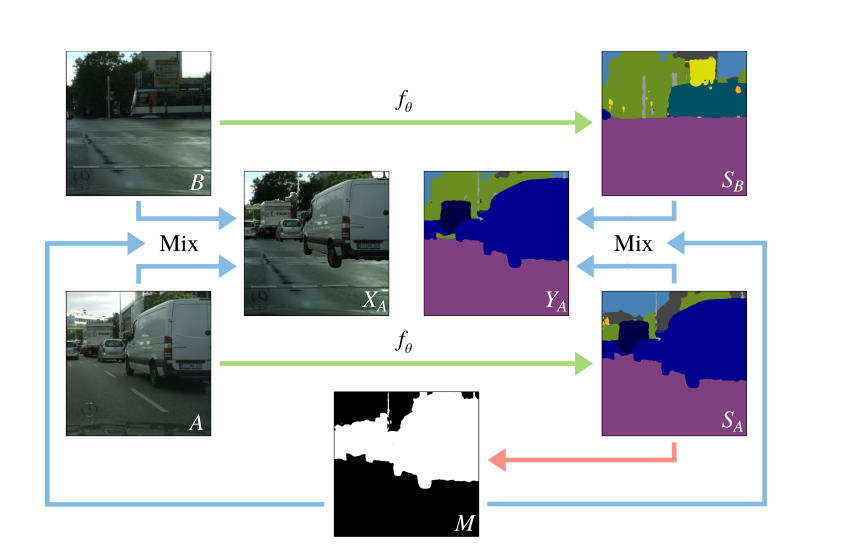
4. 선택된 class에 대해 binary mask를 생성한다
5. 생성된 binary mask를 이용하여 새로운 이미지와 label을 생성한다.
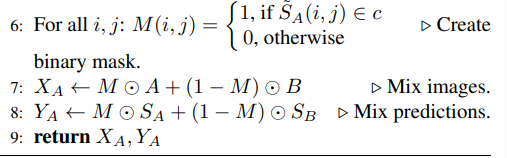
Mean teacher framework
student model은 labeled data를 이용하여 학습하고, unlabeled data를 통해 student와 teacher간의 consistency loss를 구한다.
학습을 진행하면서 일정 주기마다 student model의 weight를 지수이동평균(EMA)를 내어서 teacher model의 weight를 업데이트 해준다.
해당 논문은 semi-supervised learning을 효과적이고 쉽게 구현하기 위해서 그전까지 가장 효율적인 model이었던 mean teacher framework를 채택한다.
Loss and Training
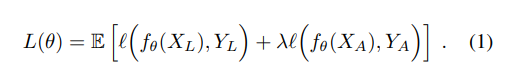
Loss는 labeled data/unlabeled data의 cross entropy의 선형 결합으로 이루어져 있다.
논문에서는 한 배치당 data의 비율을 각각 50%로 사용하였다.
즉 배치마다 50% 데이터로 student를 학습하고 ema를 하여 teacher weight를 업데이트 하고 나머지 50%로 teacher를 학습시켰을 것이라 예상된다.
또한 모델 초기에는 성능이 안좋음으로, teacher모델의 가중치가 낮아야한다(0에 가까워야한다). 그럼으로 학습이 진행되면서 점점 가중치를 키우는 방향으로 학습이 진행된다.
conclusion