Intro
Why?)
기존의 GBDT -> 모든 데이터로 모든 feature에 대한 split point를 검증해야함 -> time consuming -> 이런 비효율적인 과정을 data sampling과 sparse matrix처리를 이용하여 개선한다
이전 개선 노력들의 문제점
1) 데이터의 크기를 줄이기 위한 노력
일정 threshold 이하의 weight를 가지는 data instance 삭제
- Adaboost 처럼 misclassified data에 대하여 weight를 주는 방식이 gbdt같은 경우 존재하지 않아 적용하기 어려움
weak learner 마다 데이터를 샘플링하는 비율을 다르게 하여 학습- SGB의 방식은 적용 가능하나 오히려 성능 하락하는 문제 발생
2) 데이터 feature을 줄이기 위한 노력
차원축소나 데이터 분석등을 통해 이루어질 수 있지만, 이런 축소는 데이터의 column들이 일정부분 기능이 겹쳐있다는 가정을 통해 이루어지지만, 그렇지 않을 수 도 있고 그렇기 때문에 역효과가 날 수도 있다.
-> 이런 문제들을 GOSS,EFB를 통해 해결한다
Gradient-based One-side sampling
Adaboost -> 데이터의 weight를 정의하지만 GBDT에서는 정의하지 않음
GBM -> 각각의 data instance에서 Gradient가 작다는 것은 이미 잘 예측하고 있음을 의미
-> 그러면 gradient가 작은 데이터를 버릴까? 그렇게 되면 데이터의 전체적인 분포가 변하지 않을까? 라는 생각에서 출발
Main idea)
gradient가 작은 데이터에 대하여 sampling을 하고, distribution의 손실에 대한 보상으로 information gain을 계산 할 때 작은 gradient를 가지는 데이터에 대하여 가중치를 준다.
DEF)
GBDT에서 information gain은 split 이후의 variance로 계산된다

GOSS에서 information gain은 다음과 같이 정의된다.
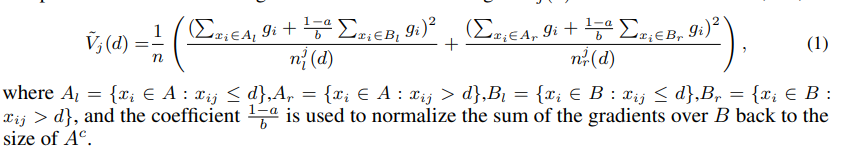
a -> 는 전체에서 상위 몇퍼센트를 남길 것인지
b -> a의 여집합 중에서 몇퍼센트를 남길 것인지
즉 위에서 설명한 것처럼 각 식에서 두번째 term인 부분이 smaller gradient를 가지는 부분이고 앞에 (1-a)/b라는 weight를 붙여준다(직관적으로 이해하자면, 샘플링된 파트가 전체 smaller 파트를 대표하도록, 지금 데이터셋의 크기인 b로 나누고 전체 smaller 파트의 크기인 1-a를 곱하여 scailing 해준다)
GOSS과정)

Exclusive Feature Bundling
비슷한 경향을 가지는 feature를 하나로 묶어 표현하는 방식
mutually exclusive 관계가 아니라면 하나로 묶어 표현하겠다.
이런 문제는 각 feature을 vertex로 생각하는 graph coloring방식으로 생각할 수 있고 그렇기 때문에, 대표적은 NP문제로 greedy방식을 이용해 근사하는 방법을 선택한다.
-> how?)
1. 각 feature별로 서로 같이 0이 아닌 row가 몇개 있는지 계산한다 -> edge value
2. 각 feature을 vertex로 둔다.
3. degree순으로 정렬 후 가장 높은 vertex부터 순회한다.
4. cut-off(기준 값) x 데이터 개수 만큼의 값을 넘기지 못하는 edge를 지운다.
5. 그렇게 해서 그루핑 된 값을 하나의 feature로 만든다.
5-1. 기본적으로 두 feature에 대하여 앞에있는 feature를 기준값으로 둔다면 두번째 feature의 값을 첫 feature의 최댓값+ 두번 째 feature의 값으로 두고 이 두 feature값을 합친값으로 한다.
5-2. 만약 두 feature 모두 0이 아니라면 기준 feature 값을 사용한다.->정보 손실이 생길 수 있지만, 시간적 이득을 생각한다.

