Representation Similarity and CKA
실험 기준을 정의한다.
비교 하고자 하는 layer에서 추출한 두 feature map X,Y에 대하여
(p = 비교하고자 하는 데이터셋의 개수 m1 = feature map 차원)
K = X의 gram matrix, L = Y의 gram matrix
Gram mtrix(x) = 로 두 벡터(행렬)간의 inner production을 나타내어 기하학적으로 두 벡터간의 유사도를 표현한다고 할 수 있다.(하지만 최종적인 식에서는 이런 의미로 사용하진 않음)
결과적으로 수많은 feature에 대해 서로 유사도를 비교할 것임으로 mean,variance가 유사도 비교에 주는 영향성을 줄이기위해 centralize 한다
최종적으로 K,L에 대한 Hilbert-Schmidt independence을 사용하여 유사도를 구한다
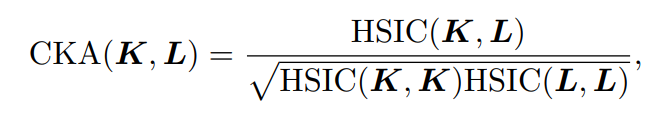
이렇게 계산된 유사도는 Gram matrix로 모든 뉴런에대해 pairwise하게 계산됨으로 matrix의 othogonal transform이나 permutation에 대하여 불변하다.
EXP1
각 실험 모델의 모든 layer(activation ,normalization 포함)에 대하여 pairwise한 X,Y쌍에 대하여 CKA를 구한 Heatmap
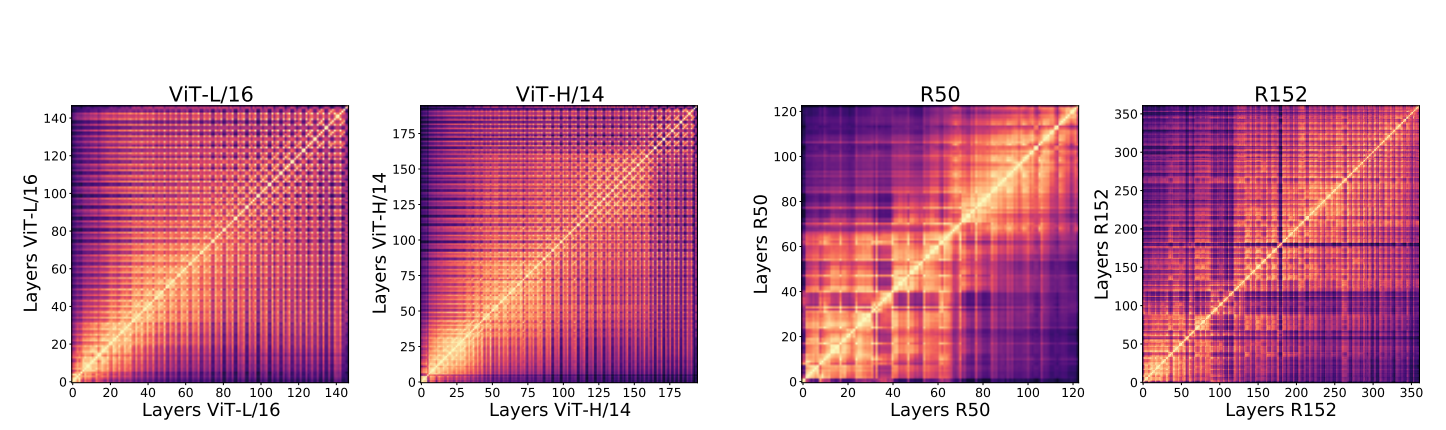
VIT는 Resnet 계열보다 일정한 heatmap을 보인다
Resnet은 heatmap이 이분화 되있는것처럼 보이는 반면에 VIT는 low layer로부터 high layer로 까지의 정보가 잘 전달되는 것으로 보인다
VIT와 Resnet을 각각 X,Y로 두고 같은 실험을 반복한다.
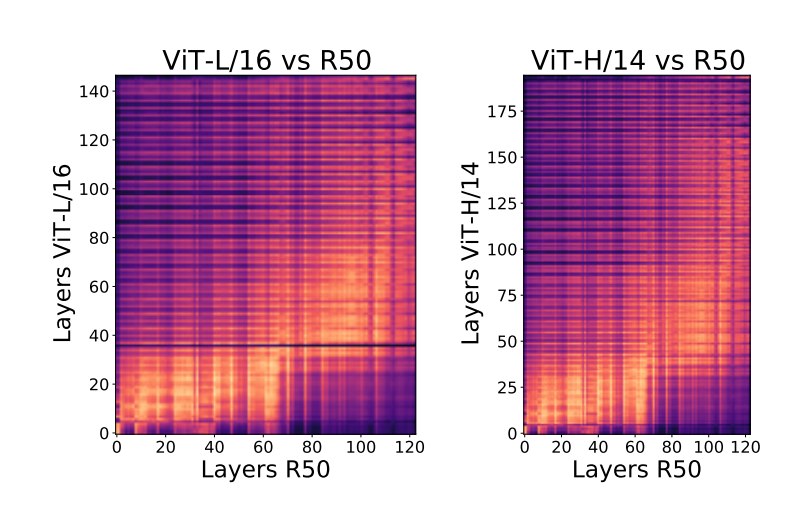
VIT layer을 전체를 3등분 하였을 때
1. low layer 부분은 resnet과 비슷한 representation을 계산하는 것 처럼 보여진다
2. mid layer 부분은 resnet의 high layer과 비슷한 계산을 하는 것 처럼 보인다
3. high layer 부분은 resnet과 완전히 다른 계산을 하는 것 처럼 보인다
4. VIT에서 lower layer에 해당 하는 부분이(%) resnet에서는 훨씬 많은 layer을 필요로 한다
-> VIT는 마지막에 resnet에 없는 CLS token을 이용하기 때문 -> 더 많은 정보를 함축하고 있는 것 처럼 보인다
EXP2
이런 차이를 내는 요소에 대하여 가설을 세우고 실험한다
가설) global information을 aggregate하는 차이 때문이다(self-attention layer)
https://github.com/sayakpaul/probing-vits/blob/main/notebooks/mean-attention-distance-1k.ipynb 참고
1. 이미지의 각 패치개수에 따른 행렬 nxn을 만들고 각 각 postion i와 j에 따른 절대 거리를 적는다
2. 이 행렬과 attention weight를 element-wise multiply 후 mean을 구함
-> 이렇게 만들어진 값은, 각 position에 대하여 얼마나 멀리 있는 값까지 반영했는지를 알 수 있다.(weight값은 0~1사이 이기때문에, 곱해지는 position값이 훨씬 크기 때문(ex 16))
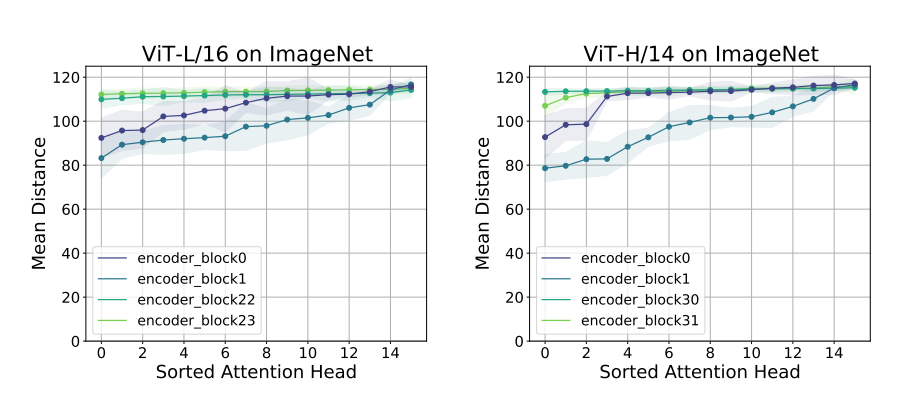
- low layer은 local한 정보와 global한정보를 모두 가지고있다.
- high layer은 모두 global 한 정보를 가지고 있다.
- 데이터가 불충분한 imagenet에서는 vit가 성능저하가 심한데, 이 때는 lower layer에서 locally한 정보를 충분히 담고 있지 않은것처럼 보임으로, 모델의 성능에 local information이 굉장히 중요함을 알 수 있다.
가설)
그렇다면 Low layer에서 Resnet과 다르게 global 정보도 받아들이기 때문에 이 방식에서 잡아내는 feature의 특징이 달라지는 걸까?
VIT의 첫번째 encoder영역의 head의 subset과 resnet의 lower layer에 대하여
1. CKA를 구한다
2. VIT subset의 mean distance를 X축으로 하고 CKA를 Y축으로 하는 그래프를 그리고 분석한다.
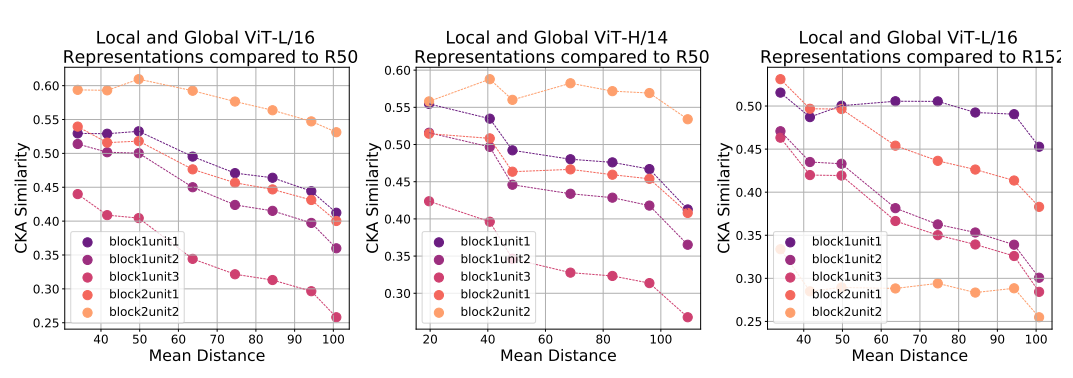
mean distance가 늘어남에 따라 CKA가 급격히 떨어지는것을 보아 VIT가 lower layer에서 global information을 반영하는 점이 feature의 차이를 만들어내고 있다고 볼 수 있다.
추가실험)
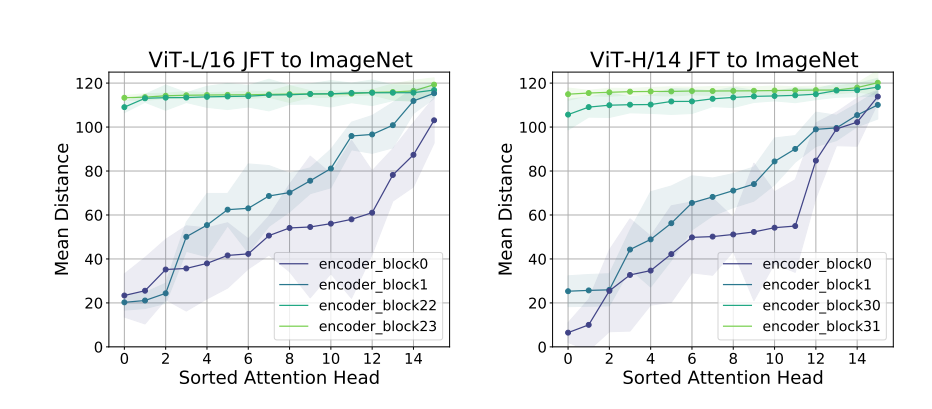
Effective Receptive field를 그림으로써 위 가정을 다시한번 확인한다
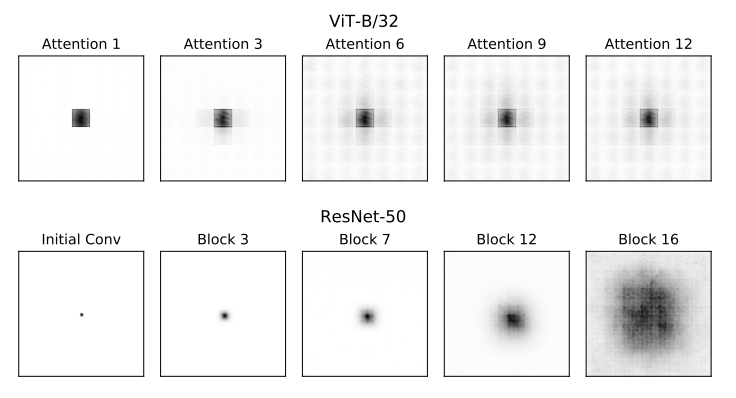
- low layer에서 VIT가 조금더 global한 정보를 담고있고 global 정보를 반영하는 쪽으로 학습되고 있음을 볼 수 있다
- VIT는 strong residual connection에 의해 중앙 patch에 대한 의존성이 높아보인다(다음 section)
EXP3
그렇다면 VIT는 첫 실험과 같이 low layer의 정보를 high layer로 잘 전달하는데 이런 현상과 skip connection이 관련이 있을까?
이라고 할 때 이 두 값의 norm의 비 의 값이 클수록 skip connection의 영향력이 높고 작을수록 영향력이 적음을 의미한다.
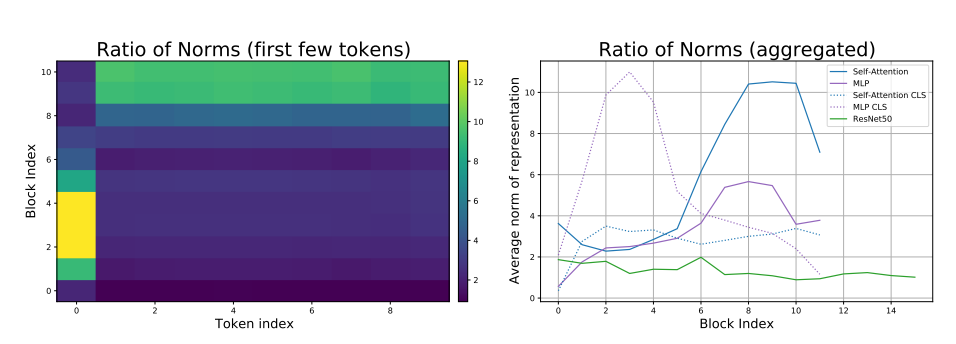
- 네트워크 전반부에는 CLS token이 주로 skip connection에서 우세한 형태를 이룬다
- 후반부에는 반대로 spatial token의 영향력이 늘어나고 cls token의 영향력이 줄어든다.(z_i를 short branch f(z_i)를 long branch라고 표현하고 있다)
- 전반적으로 Resnet과 비교했을 때 VIT에서 skip connection이 훨씬 중요한 역할을 하고있음을 알 수 있다.
그렇다면 skip connection을 제거하고난 후의 학습 양상은 어떻게 될까?
-> block i에대한 skip connection을 제거하는 실험을 한다.(CKA)
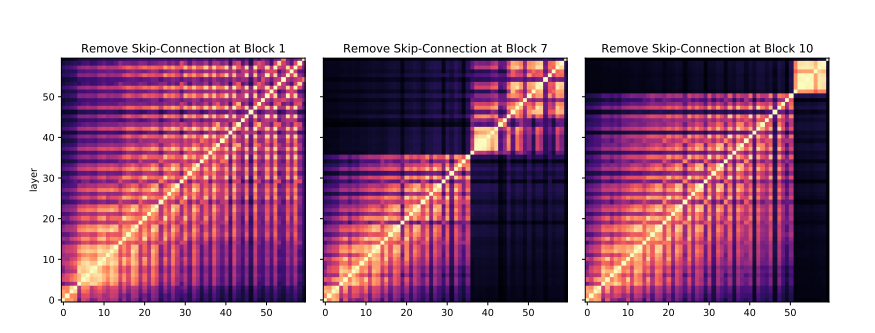
- middle layer에 대한 skip connection 제거는 약 4%의 성능 하락을 가져왔다
- skip connection이 이루어지지 않은 layer을 기준으로 정보가 global하게 전해지지 않고 있음을 알수있다.
- 그렇기 때문에 middle layer가 다른 부분보다 더 치명적인 영향이 있음을 알 수 있다.
EXP4
지금까지의 실험을 종합해보면 self-attention은 spatial information을 잘 aggregate하는 역할을 skip connection은 high layer로 information을 전파하는 역할을 하고있다.
그렇다면 VIT는 spatial localization에 대하여 얼마나 잘 작동하는가? 그리고 spatial information이 high layer까지 잘 보존되는가? Resnet과 비교해보면 어떤가?
-> 아런문제는 object detection과 같은 문제를 해결할 때 중요하다
Resnet과 VIT의 token representation을 비교한다
Resnet에는 이런 개념이 없기 때문에 새로 개념을 정의한다
Resnet에서 token representation은 특정한 spatial location에 대한 모든 convolution 연산의 집합이다.
정의된 token으로 input image와 last layer간의 CKA를 구한다.
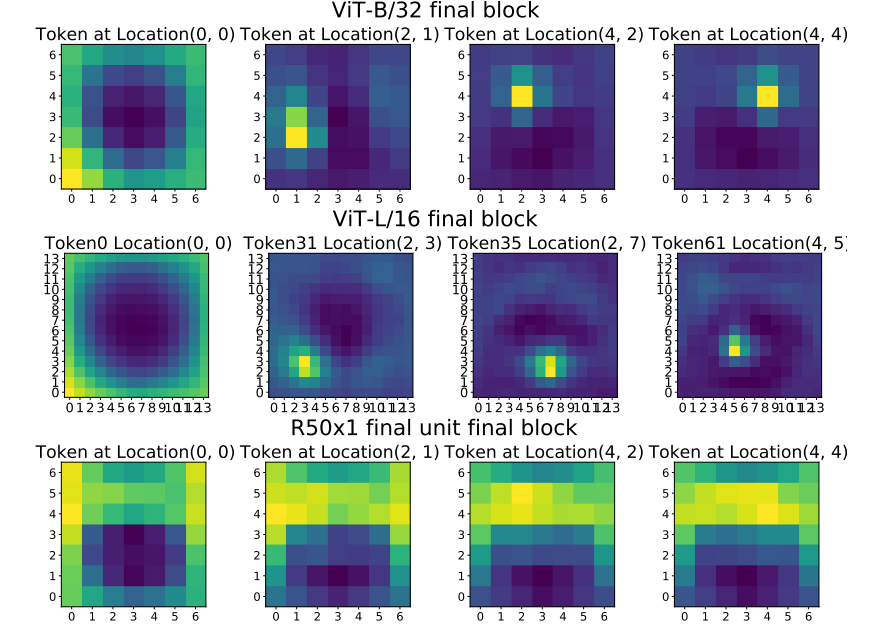
- VIT는 각 local이 확실하게 구분되어 있다.
- 0 token은 edge부분을 나타내고 있다
- 오히려 Resnet은 token간의 locality의 경계가 확실하지 않다
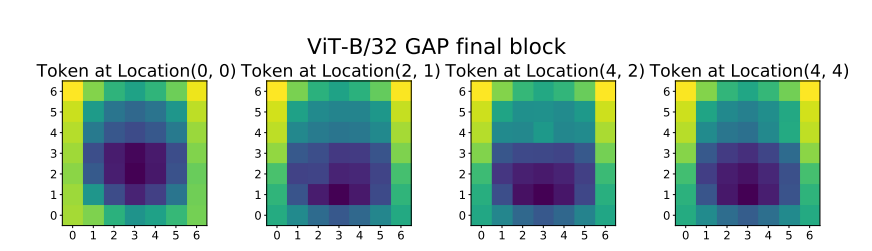
- 이 결과에 대하여 Resnet이 GAP를 이용해 학습되어 나타난 결과라 생각해 VIT에서 GAP를 추가한 실험을 한다
- GAP가 weaker locality를 만들었음을 알 수 있다.
그렇다면 각각의 token의 작동방식에 대해 실험해본다
- linear probe
- 각 모델의 feature map을 새로운 classifier에 넣어 학습시킨다.
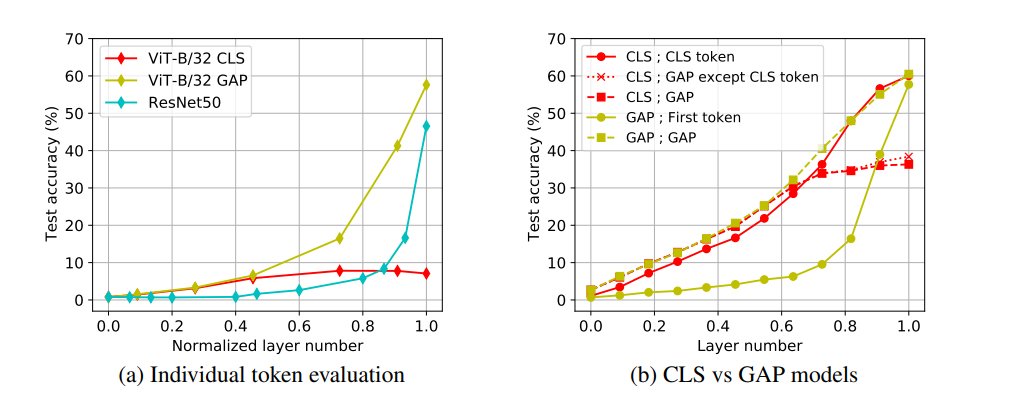
- GAP와 resnet이 high layer에 대하여 더 잘 작동하고 있음을 알 수 있다.
- CLS를 사용하면 이미지를 전체가 아닌 각 token이 서로 다른 분명한 local을 학습하고 나머지 두 case는 GAP를 이용해 경계구분없이 모두 전역적인 지역정보를 포함하고 있기 때문에 이런 결과가 나왔을 것이다.
- 이 결과를 증명하기 위해 오른쪽 그래프에서 VIT에서 single token GAP가 제일 좋은 성능과 비슷한 성능을 내는것을 보아 다른 token들도 GAP의 특성 때문에 비슷한 정보를 포함하고 있기 때문이라고 예측할 수 있다.
EXP5
- 데이터 scale과 모델의 상관관계
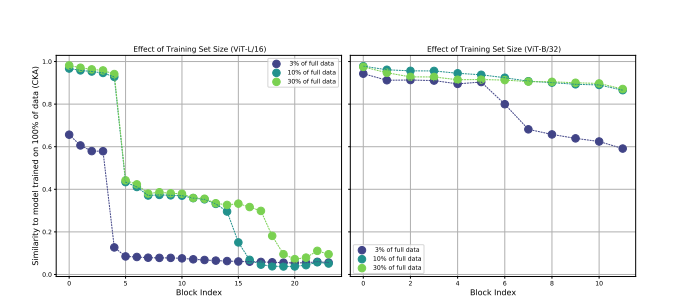
low layer에서는 데이터 scale이 차이가 많이 나도 CKA값이 비슷함을 알 수 있다.
데이터 scale이 영향을 주는 것은 주로 high layer임을 알 수 있다.
