Computer Vision 최강자, Convolutional Neural Network (CNN)
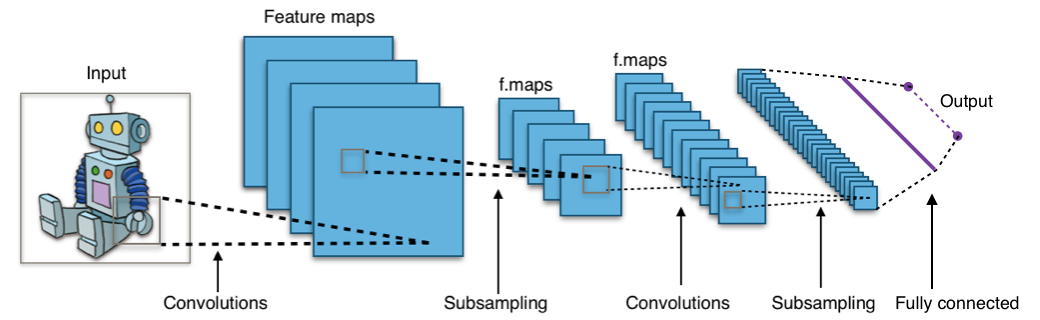
이미지 부분 부분을 현미경으로 줌 인해 본다.
이것을 필터(convolution filter)라고 하는데, 이 필터를 이미지 전체를 훑으며 살펴보도록 움직여 전체 이미지에 대한 이해를 형성하는 구조를 가지고 있다.
http://taewan.kim/post/cnn/
CNN -> 사물 인식,얼굴/표정 인식 등 주요 CV 문제들은 엄청나게 많은 학습 데이터로 거대하고 deep한 CNN 모델 만들면 인간이 눈으로 사물을 인식하는 만큼 잘할 수 있게 됬다.
Word embedding을 쌓아서 그림처럼
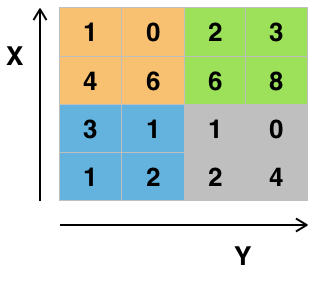
이런식으로 이미지는 2차원의 매트릭스다.
하나의 item안에 픽셀 값이 들어있다.
앞에서 배운 word embedding은 단어를 N x 1 매트릭스, 즉 column vector로 표현했는데 만약 한 문장의 모든 단어들의 word embedding들을 전부 쌓아버린다면
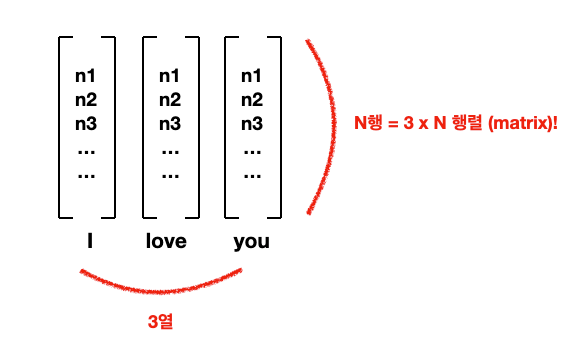
문장에 10개의 단어 있고, embedding의 사이즈 300이면 10 x 300 매트릭스 -> 가로 10 세로 300의 길쭉한 이미지 생성
아래 이미지 처럼 각 word embedding을 heatmap 이미지처럼 표현 가능
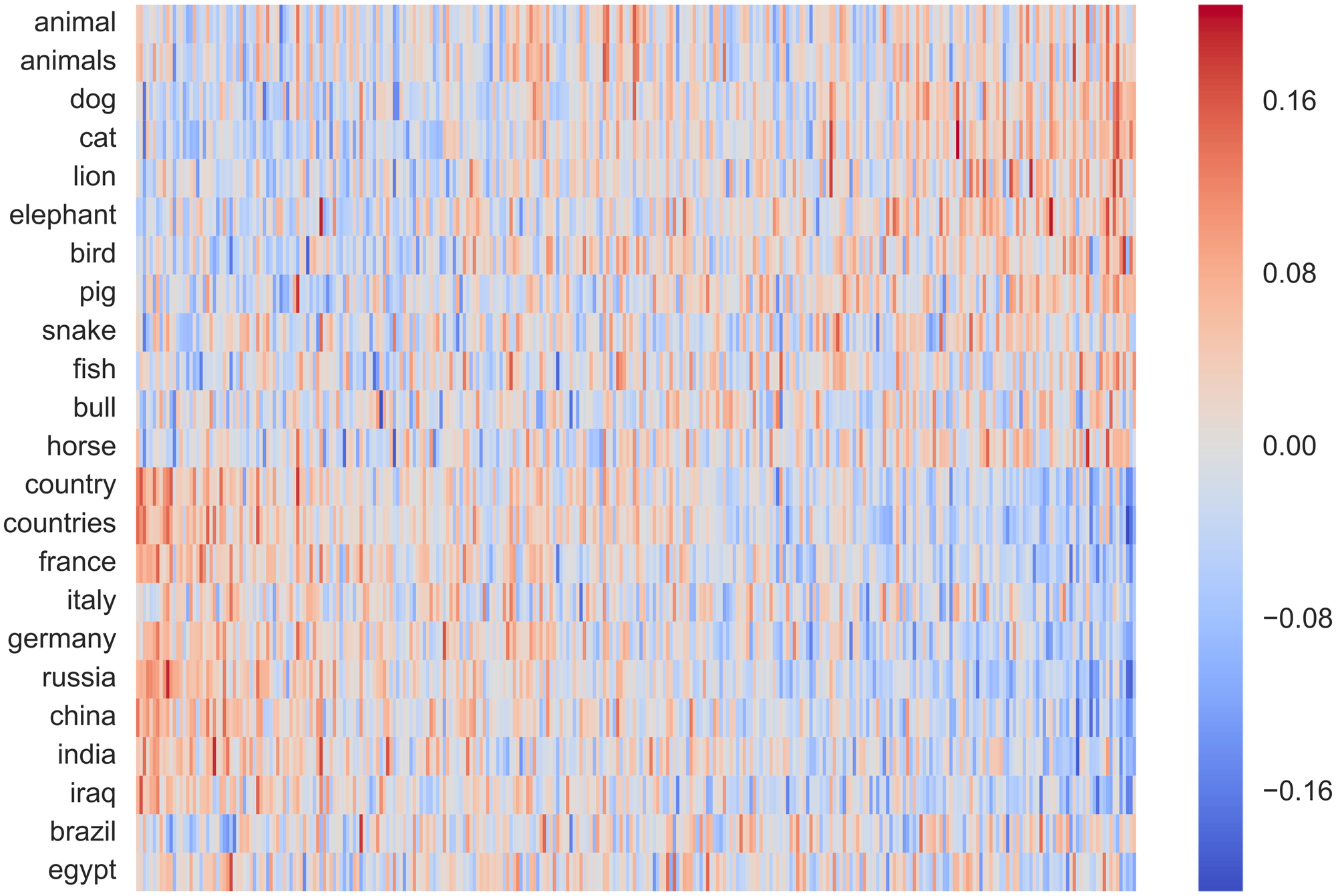
이처럼 word embedding 활용하면 어떤 문장도 2차원 매트릭스로 표현 가능하고 CNN을 쓸 준비가 된다.
NLP에 Computer Vision 기술 부워보자
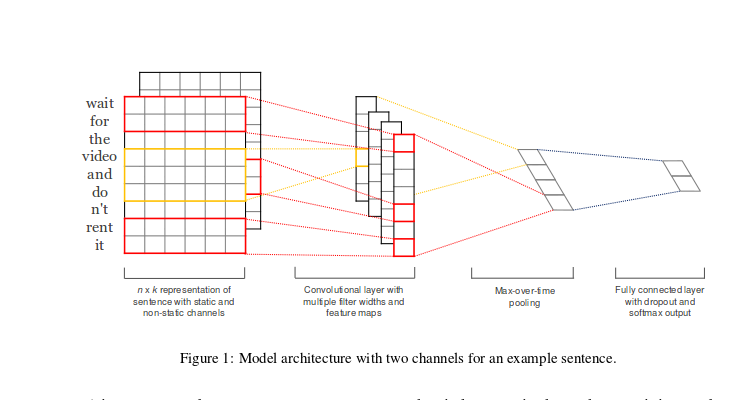
단어를 보는 CNN (WordCNN)이 이미지를 보는 CNN과 다른 점은 2D 필터가 아니라 1D 필터를 쓴다는 점이다.
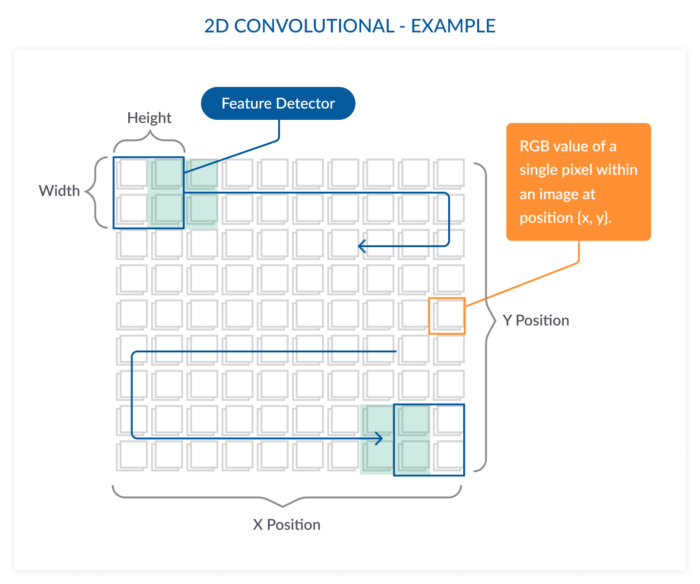
이미지에 사용되는 2D 필터는 아래 사진처럼 x축과 y축의 공간 관계를 고려한다.
우리가 눈으로 사진을 훑는 것과 비슷하다.
NLP에서 사용하는 CNN은 아래와 같이 하나의 축만 고려하는 1D 필터를 사용한다.
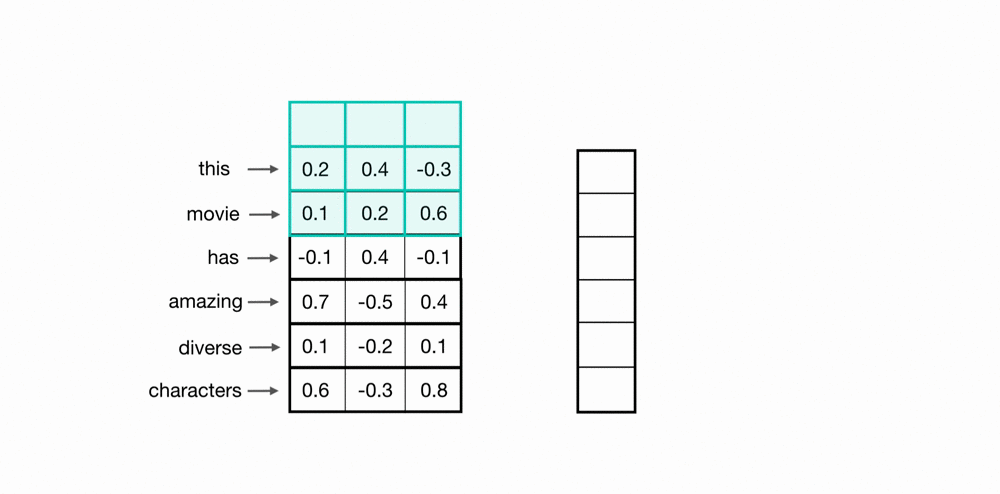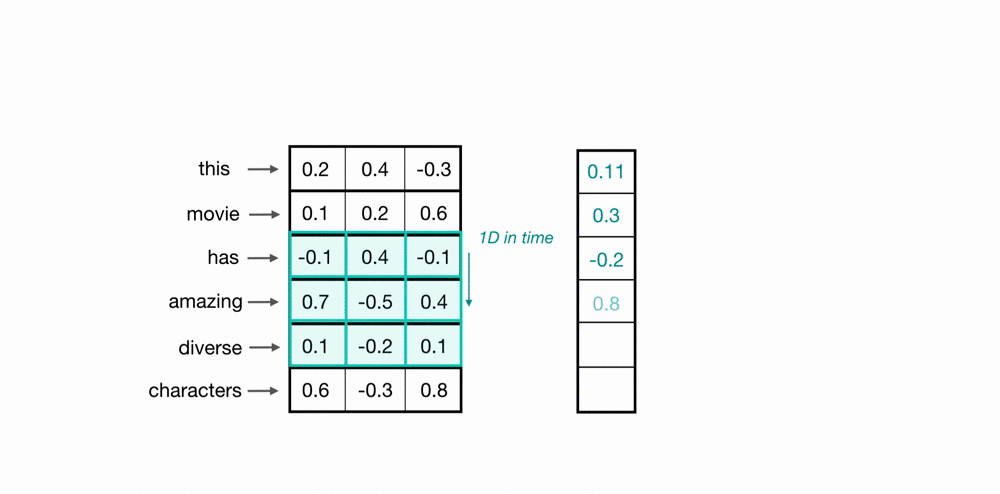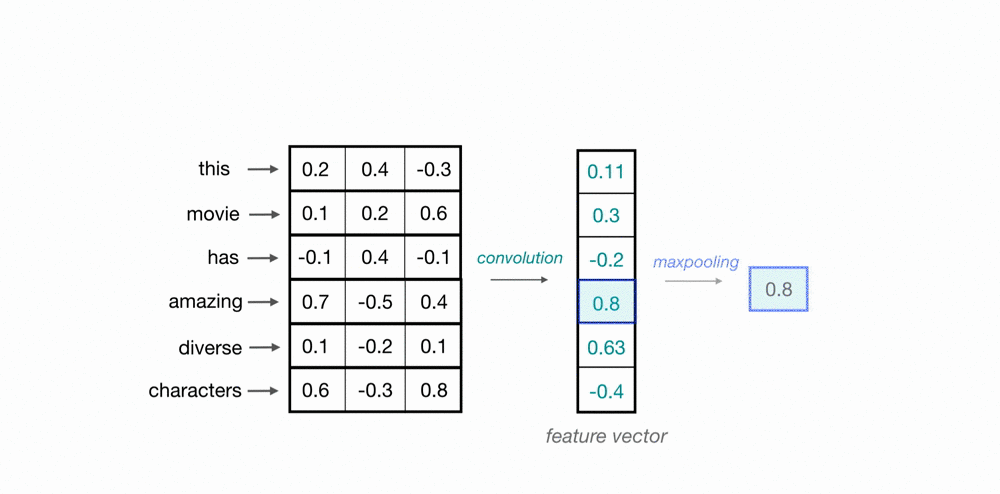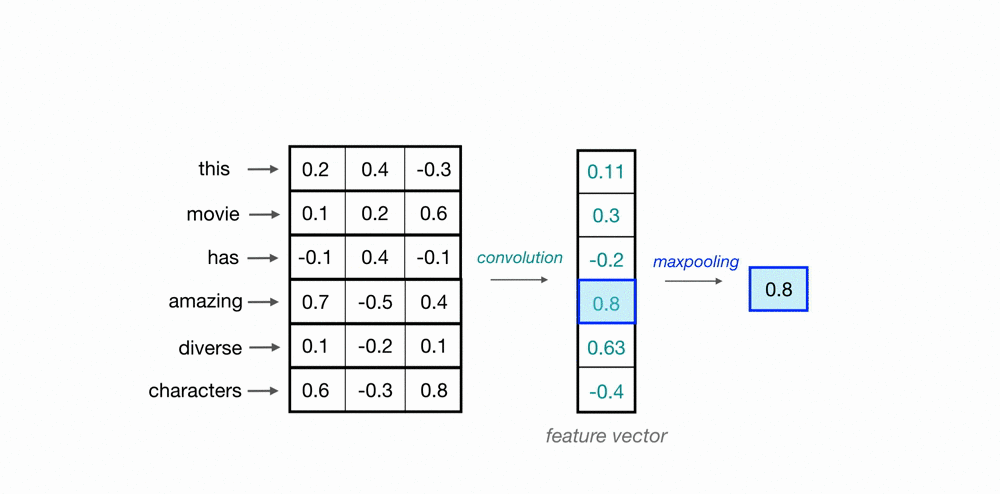
애초에 word embedding은 이미지의 위, 아래나 왼쪽,오른쪽처럼 어떠한 공간적인 관계를
가지고 설계된 게 아니기 때문이다.
그렇기 때문에 위의 예처럼 1D CNN은 한번에 단어 전체의 vector 3개 숫자를 고려한다.
(위에는 하나의 단어를 column vector가 아니라 누워있는 row vector로 표현)
**1D Convolution을 더 깊게 이해하고 싶으신 분은 위키독스의 이 블로그를 참고.
WordCNN은 위 논문에서 감정분석, 질문유형분석, 객관/주관유형분석에서 뛰어난 성능을 보여준다.
pretrained wordembedding
알고리즘들 이용해 엄청나게 많은 (정말 많은) 데이터로 학습한 결과물이다.
데이터가 없거나 적은 대부분의 사람들에게 단비 같은 존재다.
실제로 WordCNN 원 논문을 비롯해 pretrained wordembedding 사용했을 때 성능 올라감
특히 학습 데이터 적을 때 더욱 효과적이여서 웬만하면 가져다 놓고 시작하는 것이 상식이 되었다.
이는 ML에서 transfer learning이라고도 한다.
오픈소스로 다운로드 받을 수 있는 pretrained embedding 대표적인 3가지
- word2vec : skipgram으로 Google News로 학습한 Google의 word vector.
- GloVe : Matrix factorization으로 학습된 Stanford의 word vector.
- FastText : skipgram의 업그레이드 버전으로 학습된 Facebook의 word vector.

정보에 감사드립니다.