스팸 이메일 분류기 만들기
NLP 기술로 편지함에서 스팸 걸러낼 수 있는 감지모델
기본적인 통계 모델 Naive Bayes Classifier 사용
이분법으로?
가장 간단한 0, 1로 나누는 이분법을 logistic regression이라는 통계 모델을 가지고 학습 해봤는데 Spam detection도 이분법으로 가능할까?
문제는 어떤 데이터를 가지고 있느냐이다.
영화리뷰 긍정,부정 나눌 때 가진 데이터셋 처럼
스팸 이메일 역시 이러한 학습 데이터 필요하다.
스팸 아닌 이메일 (negative; 0), 스팸 이메일 (positive; 1)
이런 데이터를 가지고 있다면 바로 binary classification 문제로 정의하고
해결책 찾아볼 수 있다.
- 이렇게 데이터에 정답 붙어 있는 것을 supervised learning (지도학습) 이라고 한다.
만약 데이터가 없다면
-
메일 직접 분류
이것을 human annotation, data labeling이라고 한다.
통계 모델 학습시킬 정도 규모가 될 때까지 직접 사람이 학습 데이터 만들어 내는 것이다. -
anomaly detection
anomaly는 변칙이라는 뜻, 데이터 전체 보았을 때 다른 데이터 포인트들과 아주 동떨어진 것을 찾아내는 것이다.
데이터 특성 따라 성능의 차이 많이 날 수 있고 제대로된 평가 힘들 수 있다.
( 이 방법은 label이 따로 필요하지 않은 unsupervised learning)
데이터가 있다고 가정 하고 1번 째 binary classification 문제 접근하자
Multinomial Naive Bayes classifier
https://junpyopark.github.io/bayes/
c : classifier가 선택할 수 있는 class ( 지금의 경우 binary이기 때문에 스팸이냐, 아니냐 두개의 class이다)
d : document (이메일)

어떤 이메일(d) 주어질 때, 이 메일이 스팸인지 아닌지 (c=0? c=1?) 각각 확률 계산 후, 더큰 큰 확률 가진 c를 찾는다.
P(c|d)는 베이즈 정리 통해 이렇게 바뀌어질 수 있다.
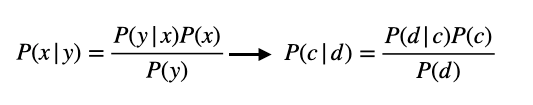
Bayes Theorem을 P(c|d) 그대로 적용

P(d)는 가장 큰 확률의 c를 찾는 것과 상관이 없기 때문에 날려도 좋다.
남은 것은 2가지 항목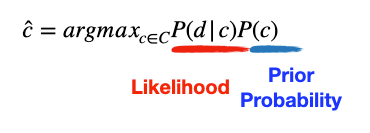
P(c) : prior probability
P(c)는 이메일(d)과 상관 없이 classifier가 선택할 수 있는 class의 확률, 사전확률이라고 한다.
2가지 옵션이 있는데 스팸이냐(c=1), 아니냐(c=0) 어떻게 이 확률을 계산할 수 있을까?
그냥 주어진 학습 데이터에서 스팸의 비율 얼마인지 계산하면 된다.
예를 들어 100개의 이메일 중 2개 스팸이라는 것 알면
P(c=1) = 0.02, P(c=0) = 0.98 이다.
P(d|c) : likelihood
Likelihood(가능도)는 어떤 이메일이 스팸 class에서 등장할 가능성을 계산한 숫자다.
c = 스팸이라고 주어졌을 때, 이 이메일이 작성될 확률을 계산한 것이다.
이미 스팸이라는 가정을 하고 이메일이 쓰여졌다면 얼마나 그럴듯 하냐를 계산한 거라 생각하면 된다.
얼마나 그럴듯하게 계산하는지는 이메일에 들어가 있는 단어 하나하나를 살펴보는 것이다.
"광고", "무료", "보험", "체험", "판매"
같은 단어들이 보이면 바로 스팸으로 여기고 삭제한 경험과 같은 원리로
naive bayes classifier는 학습 데이터 중 스팸 이메일들에 들어 있는 단어들에 대한 통계를 확률로 계산한다.
ex) "보험" 단어 스팸 이메일 100개 중에 90개, 보통 이메일 10개중 1번 들어있다고 하면 P(보험|스팸) = 90/100 = 0.9로 계산

순진하게 단어를 바라본다면?
이메일(d)에 대한 확률을 알고 싶다.
각 이메일은 여러 개의 단어들(w)로 이루어져 있으며
단어들의 joint probability(결합 확률)은 어떻게 계산할까?
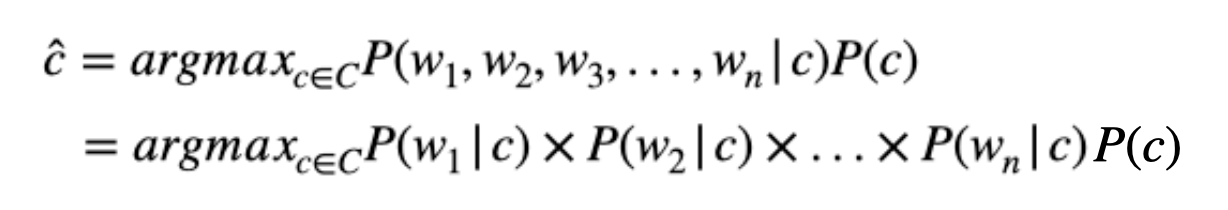
이메일의 joint probability를 제대로 계산하려면 단어의 순서가 중요
naive bayes classifier는 순서 무시하고 각 단어들이 independent 하다는 가정을 넣는다
간단한 예시, "보험 판매 오늘 당장" 이메일을 가지고 마지막까지 계산을 하면
다음과 같다

0.89와 0.01은 예시로 정한 숫자

0.0178 > 0.0098
"보험 판매 오늘 당장" 이메일은 스팸인 것으로 예측 되었다.
