
안녕하세요
첫 캐글, 데이콘 입문으로 '타이타닉 생존자 예측'을 해보았습니당
처음이라 서툴지만 나름 열심히 해보았어요!ㅎ
데이터 다운로드 경로 : https://dacon.io/en/competitions/open/235539/data
0. 라이브러리(필요한 도구) 불러오기
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from lightgbm import LGBMClassifier
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
1. 데이터 로딩
-
PassengerID : 탑승객 고유 아이디
-
Survival : 탑승객 생존 유무 (0: 사망, 1: 생존)
-
Pclass : 등실의 등급
-
Name : 이름
-
Sex : 성별
-
Age : 나이
-
Sibsp : 함께 탐승한 형제자매, 아내, 남편의 수
-
Parch : 함께 탐승한 부모, 자식의 수
-
Ticket :티켓 번호
-
Fare : 티켓의 요금
-
Cabin : 객실번호
-
Embarked : 배에 탑승한 항구 이름 ( C = Cherbourn, Q = Queenstown, S = Southampton)
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')train.tail()
→ 총 891개의 데이터, 총 12개의 feature
2. EDA
def bar_chart(feature):
survived = train[train['Survived']==1][feature].value_counts()
dead = train[train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Surevived', 'Dead']
df.plot(kind = 'bar', stacked = True, figsize = (10,5))(1) Sex(성별) : male(남성)이 많이 죽음
bar_chart('Sex')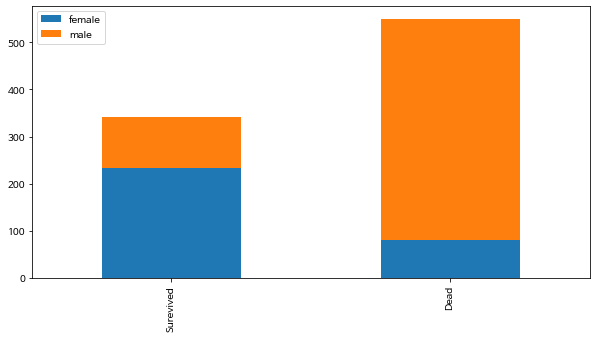
(2) Pclass(좌석등급) : 3등급 좌석 사망자 수가 많음
bar_chart('Pclass')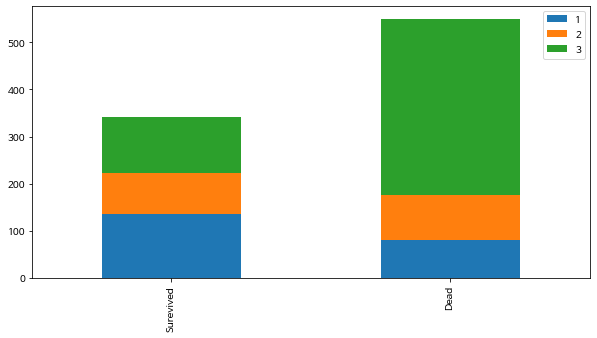
(3) SibSp(함께 탐승한 형제자매, 아내, 남편의 수) : 연관성 애매
0명인 사람이 많이 죽기도 하였지만, 8명인 사람도 죽음
bar_chart('SibSp')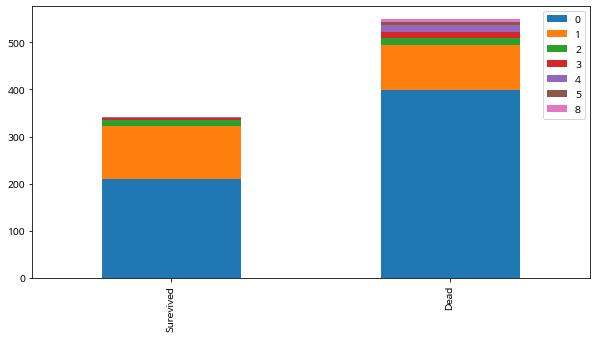
(4) Age(나이) :
가설 - 어릴수록 생존율이 높을 것이다?
plt.figure(figsize = (10,5))
plt.title('나이',fontsize = 20)
sns.stripplot(x = 'Survived', y = 'Age', data = train, jitter = True)
plt.xlabel('생존여부', fontsize = 20)
plt.ylabel('나이', fontsize = 20)
plt.show()
#0: 사망, 1: 생존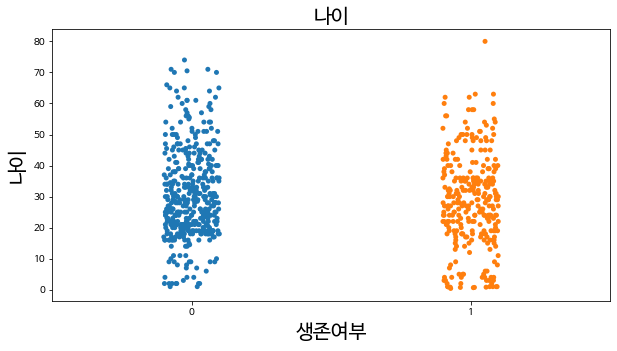
(5) Parch(함께 탐승한 부모, 자식의 수)
bar_chart('Parch')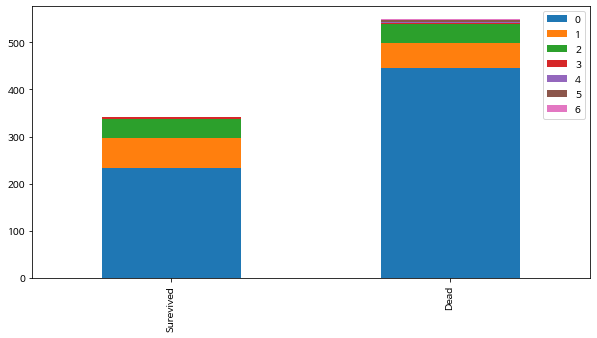
(6) Fare(티켓 요금) : 가장 비싼 요금의 티켓 구매자들은 생존하긴 함
plt.figure(figsize = (10,5))
plt.title('티켓 요금',fontsize = 20)
sns.stripplot(x = 'Survived', y = 'Fare', data = train, jitter = True)
plt.xlabel('생존여부', fontsize = 20)
plt.ylabel('요금', fontsize = 20)
plt.show()
#0: 사망, 1: 생존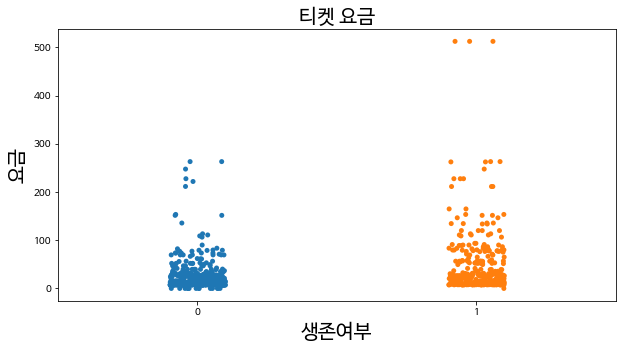
3. 데이터 확인
train.info()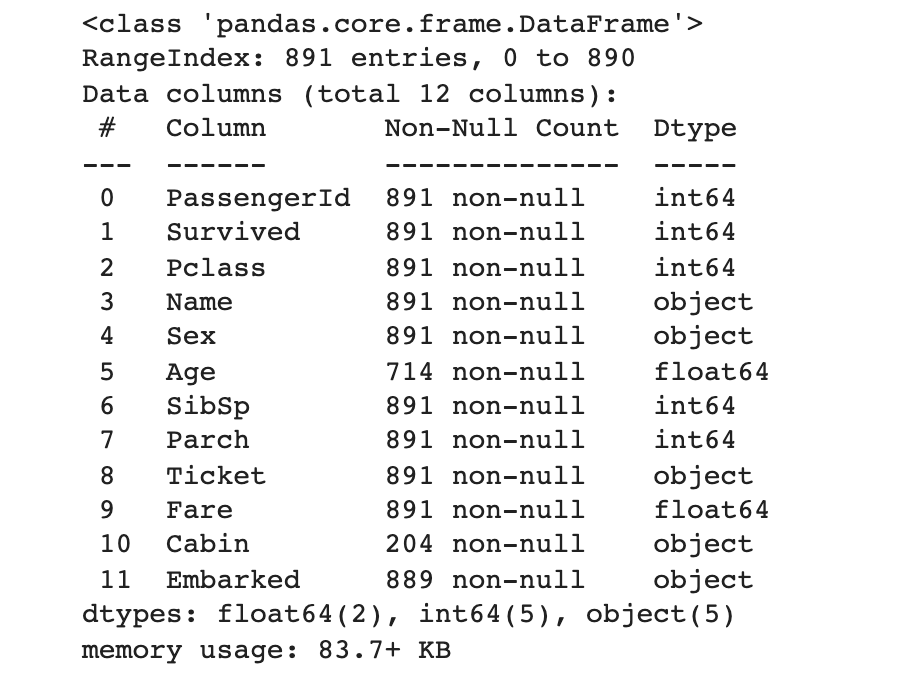
→ null값 확인(Age, Cabin, Embarked)
test.isnull().sum()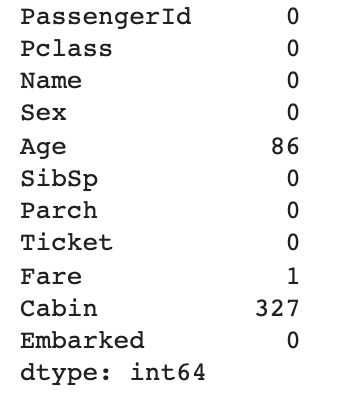
→ null값 확인(Age, Fare, Cabin)
4. 데이터 전처리
1) 이상치 및 결측치 처리
✓ pd.DataFrame.fillna() :
결측치를 채우고자 하는 column과 결측치를 대신하여 넣고자 하는 (값)을 명시 (범주형 변수일 경우, 최빈값으로 대체)
✓ pd.DataFrame.map({딕셔너리})
딕셔너리에 따라 key값을 value로 바꿈
train['Age'] = train['Age'].fillna(29) #최빈값
train['Sex'] = train['Sex'].map({'male' : 0, 'female' : 1})
test['Age'] = test['Age'].fillna(29)
test['Fare'] = test['Fare'].fillna(32)
test['Sex'] = test['Sex'].map({'male' : 0, 'female' : 1})train = train.drop(['Name', 'Ticket'], axis = 1)
test = test.drop(['Name', 'Ticket'], axis = 1)train_x = train[['Pclass', 'SibSp','Age', 'Sex', 'Fare']]
train_y = train['Survived']
test_x = test[['Pclass', 'SibSp', 'Age', 'Sex', 'Fare']]
2) 표준화 및 정규화
⭐️ 정규화 :
특성 값의 범위를 [0, 1]로 옮김
(X - MIN) / (MAX-MIN)
⭐️ 표준화 :
어떤 특성의 값들이 정규분포를 따른다고 가정
값들을 0의 평균, 1의 표준편차를 갖도록 변환
(X - 평균) / 표준편차
##표준화 : 평균 = 0, 표준편차 = 1
from sklearn.preprocessing import StandardScaler
# StandardScaler객체 생성
scaler = StandardScaler()
# StandardScaler 로 데이터 셋 변환. fit( ) 과 transform( ) 호출.
scaler.fit(train_x)
train_scaled = scaler.transform(train_x)
train_x = train_scaled
scaler.fit(test_x)
test_scaled = scaler.transform(test_x)
test_x = test_scaled
print(test_x)
##정규화 : [0,1]
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler객체 생성
scaler = MinMaxScaler()
# MinMaxScaler 로 데이터 셋 변환. fit() 과 transform() 호출.
scaler.fit(train_x)
train_scaled = scaler.transform(train_x)
train_x = train_scaled
scaler.fit(test_x)
test_scaled = scaler.transform(test_x)
test_x = test_scaled
print(test_x)5. 모델 정의 및 학습
모델은 의사결정나무, 로지스틱회귀, 랜덤포레스트, LightGBM, 인공신경망 모델들을 학습시켜 보았습니다!
먼저 kfold로 머신러닝 모델의 평균 정확도를 구해보았습니다.
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
k_fold = KFold(n_splits=10, shuffle=True, random_state=0)# kfold 함수
def kfold_func(clf):
scoring = 'accuracy'
score = cross_val_score(clf, train_x, train_y, cv=k_fold, n_jobs=1, scoring=scoring)
print(score)
print('평균 정확도:', round(np.mean(score)*100,2))🔎 kfold 평균 정확도는 다음과 같았습니다
-
의사결정나무 : 77.44
-
로지스틱회귀 : 79.35
-
랜덤포레스트 : 82.72
-
LightGBM : 81.93
💡 하지만 각각의 모델의 예측값을 직접 제출하였을 때, 인공신경망 모델의 스코어가 가장 높았습니다!
따라서 인공신경망 모델을 선택! → 튜닝
from tensorflow.keras.utils import to_categorical
train_y = to_categorical(train_y)
train_y
#원핫인코딩 0 1 1...from tensorflow.keras import models
from tensorflow.keras import layers
import tensorflow as tf
DL = models.Sequential(name = 'Classification')
DL.add(layers.Dense(64, activation = 'relu', input_shape = (5,))) #특성 13개 input
DL.add(layers.Dense(32, activation = 'relu'))
DL.add(layers.Dense(2, activation = 'sigmoid')) #0~1 사이의 값 확률DL.compile(loss = 'binary_crossentropy',
optimizer = tf.keras.optimizers.Adam(lr=0.0005),
metrics = ['accuracy'])es = EarlyStopping(monitor='loss', mode='min', verbose=1, patience=50)
아주 얕은 모델이고, EarlyStopping 또한 넣어주었습니다!
%%time
Hist_DL = DL.fit(train_x, train_y, epochs = 300, batch_size = 2, callbacks = [es])

DL_test_y_pred = DL.predict(test_x)
print(DL_test_y_pred.shape)
DL_test_y_pred# 두 개(0,1)의 확률 중 높은 쪽을 선택
arr = []
for i in DL_test_y_pred :
if i[0] > i[1] :
arr.append(0)
else :
arr.append(1)
DL_test_y_pred = arr6. 제출 파일 생성
submission = pd.read_csv("submission.csv")
submission['Survived'] = 모델명_test_y_pred
submission.to_csv('모델명_submission.csv', index = False)7. 성능 평가

데이콘에서 스코어는 0.76088로 705명 중 315등

캐글에서 스코어는 0.77990으로 13833명 중 3292등을 했습니다
(데이콘이랑 캐글이랑 스코어 기준이 다른가봐용 찾아보니 데이콘은 평가 기준이 AUC네요)
나중에 더 스코어를 올려보겠습니다!
좋은 아이디어 있으시면 댓글 달아주세요✨
