당연하게도 적립금 유무에 대하여 학습할 수 있는 Dataset은 존재하지 않는다. 따라서 직접 Crawling을 진행하여 데이터 셋을 구축하기로 하였다.
본 프로젝트의 목적은 Review image를 기반으로 실제로 적립금이 지급되는지, 지급되지 않는지를 확인하는 것이다. 따라서 Review image와 해당 Review에 대하여 적립금이 지급되었는지, 지급되지 않았는지에 대한 정보 또한 저장하여야 한다.
적립금이 지급되지 않은 이미지는 정확하게 확인할 수 있는데, 아래와 같은 뎃글이 달리면 적립금 기준을 충족시키지 못한 것이다.
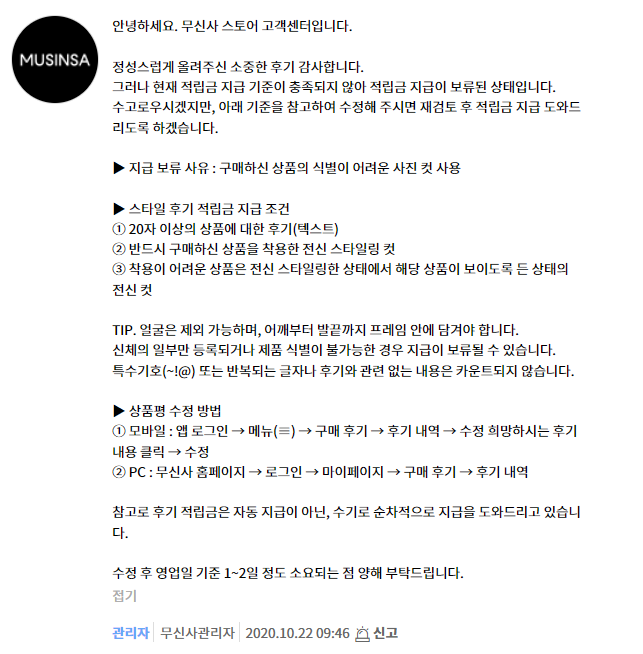
하지만 반대로 리뷰만 보고 적립금이 지급되었는지를 확인할 수 있는 방법은 없다. 이는 아직 적립금이 지급된 것인지, 아니면 심사 중인지를 확인할 방법이 없기 때문이다. 따라서 최근 1년간 판매량이 많은 제품 100개에 대하여 오래된 review 순으로 500개씩 Crawling을 진행하였다.(충분히 오랜 시간이 지난 리뷰에 대해서는 적립금 심사가 이미 끝났을 확률이 높다고 판단.)
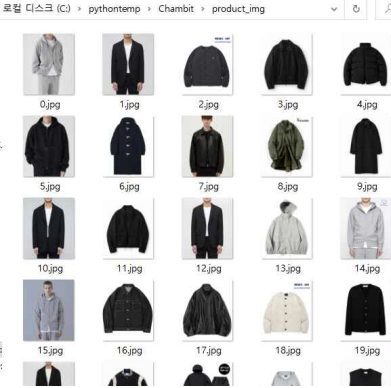
Crawling을 통해 저장되는 코드는 이미지는 아래와 같이 도식화 할 수 있다.
- 제품 이미지(100장)
- 리뷰 이미지(각 500장)
- 적립금이 지급된 리뷰이미지
- 적립금이 지급되지 않은 리뷰 이미지
Crawling은 BeautifulSoup 라이브러리를 활용하여 진행하였다.
# 제품 이미지 크롤링
page_link = "https://www.musinsa.com/categories/item/002?d_cat_cd=002&brand=&list_kind=small&sort=sale_high&sub_sort=1y&page=1&display_cnt=90&group_sale=&exclusive_yn=&sale_goods=×ale_yn=&ex_soldout=&kids=&color=&price1=&price2=&shoeSizeOption=&tags=&campaign_id=&includeKeywords=&measure="
product_img_click_link = []
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
# driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
driver.get(page_link)
req = requests.get(page_link, headers={"User-Agent": "Mozilla/5.0"})
item_num = 1
page_button_num = 4
while(len(product_img_click_link)<=100):
befor_page = driver.current_url
# 제품 페이지 접속
div_num = len(driver.find_elements_by_css_selector('#searchList > li:nth-child('+str(item_num)+') > div')) - 1
try:
button = driver.find_element_by_xpath('//*[@id="searchList"]/li['+str(item_num)+']/div['+str(div_num)+']/div[1]/a')
except:
try:
button = driver.find_element_by_xpath('//*[@id="searchList"]/li['+str(item_num)+']/div['+str(div_num - 1)+']/div[1]/a')
except:
button = driver.find_element_by_xpath('//*[@id="searchList"]/li['+str(item_num)+']/div['+str(div_num - 2)+']/div[1]/a')
driver.execute_script("arguments[0].click();", button)
sleep(0.5)
option = len(driver.find_elements_by_css_selector('#goods_opt_area > select'))
print(item_num,"번째 아이템",option,"개의 옵션")
# 제품에 옵션이 1개인 제품만 이미지 크롤링 및 웹페이지 주소 append
if option <= 1:
product_img_url = driver.find_element_by_xpath('//*[@id="bigimg"]').get_attribute('src')
url = driver.current_url
urllib.request.urlretrieve(product_img_url, product_img_path +'/'+str(len(product_img_click_link))+".jpg")
print("추가할 url: ",url)
product_img_click_link.append(url)
item_num+=1
else:
item_num+=1
driver.get(befor_page)
sleep(0.5)
if item_num == 91:
item_num = 1
page_button = driver.find_element_by_xpath('//*[@id="goods_list"]/div[2]/div[5]/div/div/a['+str(page_button_num)+']')
page_button_num += 1
driver.execute_script("arguments[0].click();", page_button)
sleep(0.5)
# 리뷰 이미지 크롤링
with open("product_link_list.pkl","wb") as f:
pickle.dump(product_img_click_link, f)
with open("product_link_list.pkl","rb") as f:
product_link_list = pickle.load(f)
o_count = 0
x_count = 0
for idx, page_address in enumerate(product_link_list):
# 무신사 페이지 열기
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
driver.get(page_address)
req = requests.get(page_address, headers={"User-Agent": "Mozilla/5.0"})
# 리뷰 이미지 저장 폴더 생성
review_img_path = './review_img/'+str(idx)+'_review_img'
# product_img_path = './review_img/'+i['title']+'_review_img'
os.makedirs(review_img_path, exist_ok=True)
os.makedirs(review_img_path+'/적립O', exist_ok=True)
os.makedirs(review_img_path+'/적립X', exist_ok=True)
# 가장 마지막 페이지로 이동
button = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div[11]/div[2]/div/a[9]')
driver.execute_script("arguments[0].click();", button)
sleep(2)
# 마지막 페이지는 그냥 넘김
review_num = len(driver.find_elements_by_css_selector('#reviewListFragment > div'))
# print("마지막페이지 리뷰 개수: ", review_num)
# button_num = len(driver.find_elements_by_css_selector('#reviewListFragment > div.nslist_bottom > div.pagination.textRight > div > a')) - 3
# print("마지막페이지 버튼 개수:", button_num)
# LP_button = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div['+str(review_num)+']/div[2]/div/a['+str(button_num)+']')
LP_button = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div['+str(review_num)+']/div[2]/div/a[2]')
driver.execute_script("arguments[0].click();", LP_button)
sleep(2)
# 마지막 페이지 바로 이전부터 반복을 통해 크롤링
for k in range(10):
for i in range(6,1,-1):
for j in range(1,11):
# 이미지 정보 가져오기
try:
imgUrl = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div['+str(j)+']/div[4]/div[3]/div/ul/li/img').get_attribute('src')
except:
imgUrl = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div['+str(j)+']/div[4]/div[3]/div/ul/li[1]/img').get_attribute('src')
# 리뷰 댓글 정보 가져오기 및 폴더에 이미지 저장
review_comment_id = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div['+str(j)+']/div[6]/div').get_attribute('c_idx')
review_comment_len = len(driver.find_elements_by_css_selector('#comment_'+str(review_comment_id)+' > div'))+1
print(review_comment_id)
print(review_comment_len)
if review_comment_len == 1:
urllib.request.urlretrieve(imgUrl, review_img_path + "/적립O/"+str(count)+".jpg")
o_count+=1
sleep(0.5)
elif review_comment_len == 2:
try:
path = '//*[@id="comment_'+str(review_comment_id)+'"]/div/div[3]/p/span[2]'
dat = driver.find_element_by_xpath(path)
urllib.request.urlretrieve(imgUrl, review_img_path + "/적립X/"+str(count)+".jpg")
x_count+=1
except:
urllib.request.urlretrieve(imgUrl, review_img_path + "/적립O/"+str(count)+".jpg")
o_count+=1
continue
else:
for m in range(1,review_comment_len):
try:
path = '//*[@id="comment_'+str(review_comment_id)+'"]/div['+str(m)+']/div[3]/p/span[2]'
dat = driver.find_element_by_xpath(path)
urllib.request.urlretrieve(imgUrl, review_img_path + "/적립X/"+str(count)+".jpg")
x_count+=1
break
except:
continue
urllib.request.urlretrieve(imgUrl, review_img_path + "/적립O/"+str(count)+".jpg")
o_count+=1
sleep(0.5)
button = driver.find_element_by_xpath('//*[@id="reviewListFragment"]/div[11]/div[2]/div/a['+str(i)+']')
driver.execute_script("arguments[0].click();", button)
sleep(0.5)
o_count = 0
x_count = 0전체코드는 해당 레포지터리에서 확인할 수 있다.

Hi~